si
收藏Hugging Face2026-02-14 更新2026-02-15 收录
下载链接:
https://huggingface.co/datasets/xhmm/si
下载链接
链接失效反馈官方服务:
资源简介:
该数据集名为'seamless-interaction',专注于音频分类任务,特别是语音和说话人评估领域。数据集包含英语音频数据,结构上分为多个音频文件夹和Parquet数据文件。数据字段包括对话ID(conversation_id)、话语列表(utterances)以及音频路径(audio_path)。其中,每个话语包含说话人标签(spk)和单词级别的详细信息(如单词内容、开始时间和结束时间)。该数据集适用于需要精细时间标注和说话人识别的音频处理任务。
创建时间:
2026-02-09
原始信息汇总
数据集概述
基本信息
- 数据集名称: seamless-interaction
- 数据集地址: https://huggingface.co/datasets/xhmm/si
- 许可证: other
- 主要语言: 英语 (en)
- 标签: audio, speech, speaker, evaluation
- 任务类别: audio-classification
- 配置文件: default
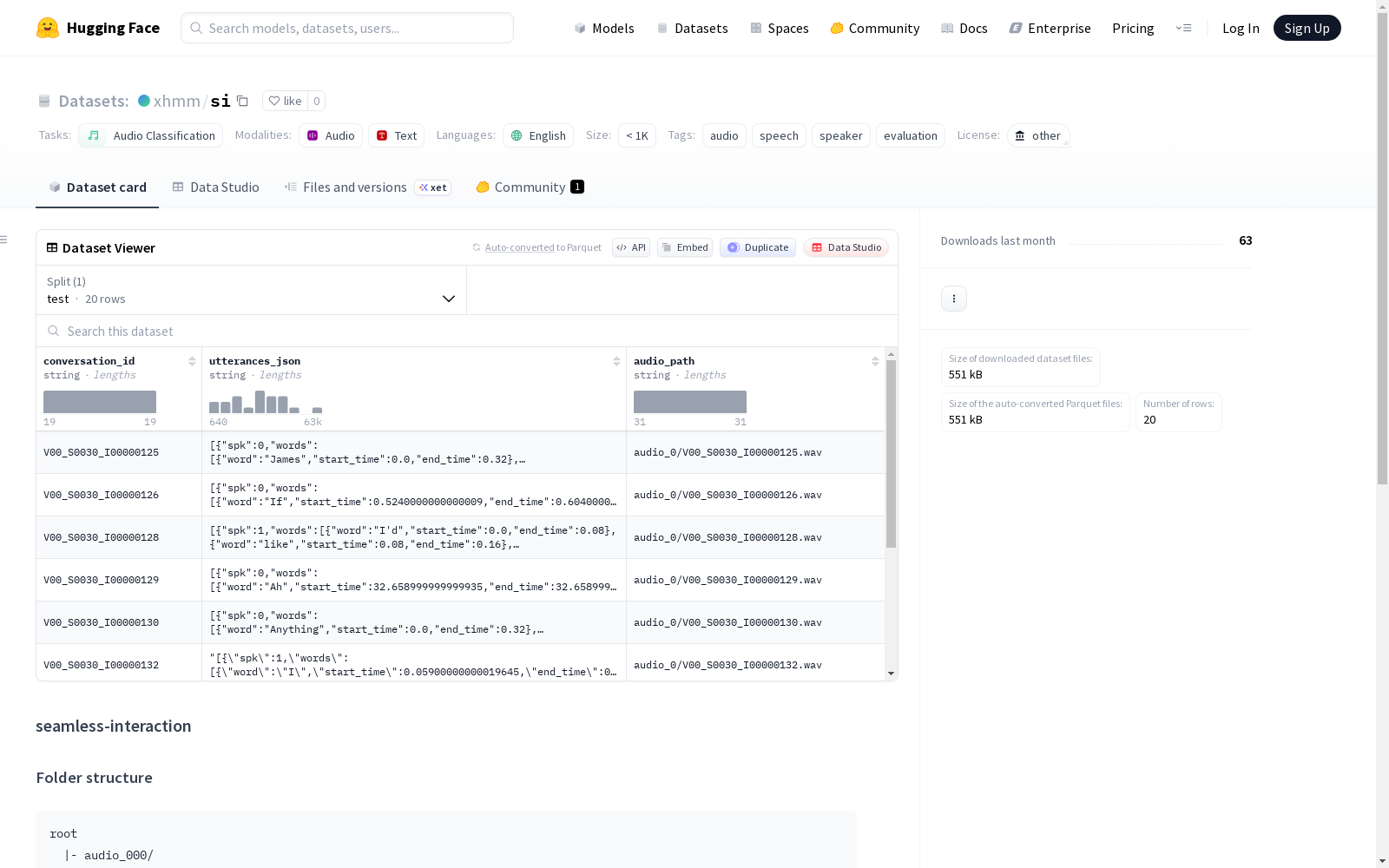
数据内容与结构
- 数据文件: 包含
data_0.parquet和data_001.parquet等文件。 - 文件夹结构: 根目录下包含以
audio_000/、audio_001/等命名的音频文件夹,以及对应的.parquet数据文件。
数据格式
数据以 Parquet 文件格式存储,包含以下列:
json { "conversation_id": "{conversation_id}", "utterances": [ { "spk": 0, "words": [ { "word": "str", "start_time": 0.0, "end_time": 0.08 } ] } ], "audio_path": "audio_{group_idx}/{conversation_id}.wav" }
列描述
- conversation_id: 对话的唯一标识符。
- utterances: 包含多个话语的列表,每个话语包含:
- spk: 说话者标识(整数)。
- words: 单词列表,每个单词包含:
- word: 单词文本(字符串)。
- start_time: 单词开始时间(浮点数)。
- end_time: 单词结束时间(浮点数)。
- audio_path: 对应音频文件的相对路径,格式为
audio_{group_idx}/{conversation_id}.wav。
数据划分
- 测试集: 对应
data_0.parquet文件。
搜集汇总
数据集介绍
构建方式
在语音交互技术蓬勃发展的背景下,seamless-interaction数据集通过精心设计的流程构建而成。其核心数据来源于真实或模拟的对话场景,将每段对话的音频文件与详细的文本转录及时间戳对齐信息相结合。构建过程中,对话被分割为独立的发言片段,并为每个单词标注了精确的开始与结束时间,同时通过说话人标识区分不同参与者,最终以结构化的Parquet格式和配套的音频文件夹形式进行组织封装。
特点
该数据集最显著的特点在于其精细的多模态对齐结构,不仅提供了完整的对话音频,还包含了单词级别的精确时间边界标注和说话人身份信息。这种设计使得数据集能够同时支持语音识别、说话人日志、语音活动检测等多种语音处理任务的评估与研究。其以对话为单位的组织方式,以及清晰分离的音频文件与元数据,为研究者分析连贯的交互语音场景提供了极大的便利。
使用方法
使用seamless-interaction数据集时,研究者可通过加载Parquet文件获取对话的元数据,包括话语序列、单词时间戳和对应的音频文件路径。随后,根据‘audio_path’字段定位并读取相应的WAV格式音频文件,即可将音频信号与文本及说话人标签进行关联分析。该数据集适用于训练或评估涉及对话场景的语音处理模型,例如通过时间戳信息对齐音频与文本,或利用说话人标签进行角色分离研究。
背景与挑战
背景概述
在语音处理与人工智能交互领域,无缝交互(seamless-interaction)数据集于近年应运而生,其核心研究问题聚焦于多说话人对话场景下的语音分析与评估。该数据集由相关研究机构构建,旨在通过精确标注的对话音频与文本对应信息,推动语音识别、说话人分离及自然语言理解等技术的融合创新。其设计不仅促进了对话系统在真实环境中的性能评测,也为跨模态学习提供了关键数据支撑,对提升智能助手的交互自然度与鲁棒性具有显著影响力。
当前挑战
该数据集致力于解决多说话人对话场景中的语音评估挑战,包括在复杂声学环境下实现高精度的说话人分离与语音识别,以及确保对话连贯性的语义理解。在构建过程中,面临的主要挑战涉及大规模对话音频的采集与同步标注,需克服背景噪音干扰、说话人重叠及时间戳对齐等技术难题,同时保持数据标注的一致性与完整性,以支撑后续模型的可靠训练与评估。
常用场景
经典使用场景
在语音交互技术领域,seamless-interaction数据集为多轮对话中的说话人识别与语音活动检测提供了关键资源。该数据集通过标注对话中的说话人身份和词级时间戳,支持模型在复杂对话流中精确区分不同发言者,并捕捉语音的时序边界。这一场景常被用于构建智能助手或客服系统,以提升对话连贯性与自然度,是语音处理研究中评估模型鲁棒性的基准环境。
解决学术问题
该数据集有效应对了语音处理中对话分割与说话人归属的学术挑战。传统方法在重叠语音或快速话轮转换中常出现误判,而seamless-interaction提供的细粒度标注助力研究者开发更精准的端到端模型。其意义在于推动了对话场景下的语音技术标准化评估,为说话人日志生成、语音识别对齐等任务提供了可靠的数据基础,促进了跨学科研究的融合与创新。
衍生相关工作
基于seamless-interaction数据集,学术界衍生了一系列经典工作,如端到端神经说话人日志系统与多模态对话分析框架。这些研究不仅优化了说话人识别的准确率,还拓展至情感分析与意图检测等维度。相关成果常发表于INTERSPEECH等顶级会议,推动了语音处理与自然语言处理的交叉进展,为后续大规模对话数据集的构建提供了方法论借鉴。
以上内容由遇见数据集搜集并总结生成


