ZEDD (ZEro-shot Depth from Defocus)
收藏arXiv2026-03-28 更新2026-03-31 收录
下载链接:
https://zedd.cs.princeton.edu
下载链接
链接失效反馈官方服务:
资源简介:
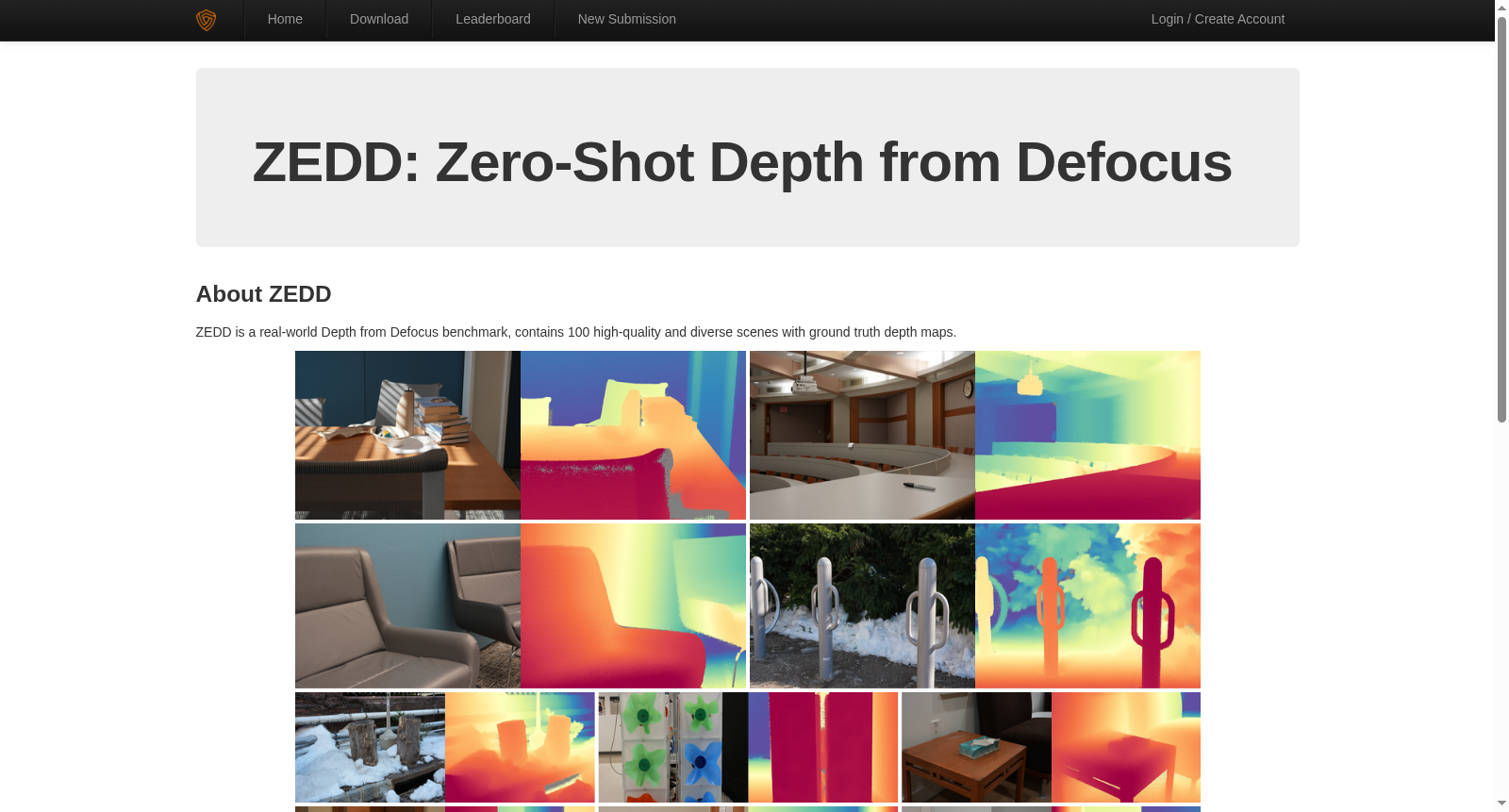
ZEDD是由普林斯顿大学团队构建的高质量离焦深度估计基准数据集,包含100个独特场景的4K分辨率焦点堆栈图像,覆盖室内外多样化环境。数据集采用专业单反相机配合F1.4-16多档光圈拍摄,通过高精度激光雷达获取密集深度真值,场景数量较前人工作提升8.3倍。其创新性数据采集流程实现了精确的焦点距离标定与光学模糊模拟,旨在解决现有DfD数据集规模小、泛化性差的核心痛点,为零样本深度估计任务提供可靠评估基准。
ZEDD is a high-quality defocus depth estimation benchmark dataset developed by a research team from Princeton University. It includes 4K-resolution focal stack images across 100 unique scenes, covering diverse indoor and outdoor environments. The dataset was captured using a professional DSLR camera with apertures adjustable from F1.4 to F16, and its dense ground-truth depth values were acquired via high-precision LiDAR. The number of scenes is 8.3 times that of prior related works. Its innovative data acquisition pipeline enables accurate focal distance calibration and optical blur simulation, aiming to address the core pain points of existing DfD datasets—small scale and poor generalizability—and provide a reliable evaluation benchmark for zero-shot depth estimation tasks.
提供机构:
普林斯顿大学·计算机科学系
创建时间:
2026-03-28
搜集汇总
数据集介绍
构建方式
在计算机视觉领域,深度估计任务常受限于数据质量与规模。ZEDD数据集的构建采用了严谨的采集流程,通过高分辨率单反相机在多种光圈设置下捕获焦点堆栈图像,并利用高精度激光雷达获取密集的地面真实深度图。为确保数据准确性,研究团队设计了远程控制镜头马达的校准管道,并对每幅图像进行精确的空间对齐,以消除镜头呼吸效应带来的影响。最终,数据集涵盖了100个独特场景,显著提升了场景多样性与数据质量。
特点
ZEDD数据集在深度估计领域展现出多项突出特点。其图像分辨率高达4K,并包含从F/1.4到F/16的多档光圈设置,能够呈现清晰且平滑的散焦效果。地面真实深度数据来源于高精度激光雷达,通过时间累积点云技术实现了高密度空间覆盖,有效避免了遮挡区域的缺失问题。此外,数据集场景覆盖广泛,包含室内外多种环境,为模型提供了丰富的几何结构信息,显著超越了以往数据集的规模与质量。
使用方法
该数据集主要用于评估深度散焦任务的零样本泛化性能。研究人员可将焦点堆栈图像及其对应的焦点距离作为输入,通过训练好的网络模型预测密集度量深度图。在使用过程中,建议按照标准评估指标,如绝对相对误差和阈值精度,对模型输出进行定量分析。数据集支持对不同光圈大小、焦点距离分布及堆栈图像数量的鲁棒性测试,为深度估计模型的泛化能力提供了全面验证平台。
背景与挑战
背景概述
在计算机视觉领域,深度估计是三维场景理解的核心任务之一,而基于离焦的深度估计(Depth from Defocus, DfD)通过分析聚焦堆栈中图像的模糊变化来推断场景的几何结构。ZEDD(ZEro-shot Depth from Defocus)数据集由普林斯顿大学的研究团队于2026年创建,旨在解决现有DfD基准在场景多样性、图像质量和真实离焦效果方面的不足。该数据集包含100个独特场景的高分辨率4K图像,覆盖室内外多种环境,并利用高精度激光雷达提供密集且精确的深度真值。ZEDD的核心研究问题是推动零样本泛化能力下的DfD模型发展,通过引入大规模、高质量的实景数据,显著提升了深度估计的准确性和鲁棒性,对自动驾驶、机器人导航和增强现实等应用产生了深远影响。
当前挑战
ZEDD数据集所解决的领域挑战在于传统DfD方法在零样本泛化场景中的局限性,即模型往往过拟合于特定数据集,难以适应真实世界复杂多变的离焦模式和场景内容。构建过程中的挑战包括:首先,采集高质量的离焦堆栈需要精确控制镜头焦点距离和光圈参数,涉及复杂的硬件校准和软件控制流程,以消除镜头呼吸效应并确保图像对齐;其次,获取高精度深度真值依赖于激光雷达点云的累积与配准,需克服传感器噪声、遮挡边界伪影以及反射表面导致的测量缺失问题,通过手动清理和滤波算法提升数据可靠性。
常用场景
经典使用场景
在计算机视觉领域,深度估计是理解三维场景几何结构的基础任务之一。ZEDD数据集作为首个专注于零样本离焦深度估计的高质量真实世界基准,其经典使用场景在于为深度估计模型提供大规模、高精度的训练与评估平台。该数据集通过采集100个独特场景的高分辨率焦点堆栈图像,并结合激光雷达获取的密集深度真值,为研究人员构建了从离焦线索中恢复度量深度图的标准化测试环境。在零样本泛化设置下,ZEDD使得模型能够直接应用于未经训练的领域,推动了离焦深度估计从过拟合特定数据集的局限向实际应用场景的跨越。
解决学术问题
ZEDD数据集主要解决了离焦深度估计领域长期存在的两大核心学术问题:一是缺乏高质量、多样化的真实世界基准,以往数据集如DDFF在场景数量、图像分辨率和离焦效果真实性方面存在显著不足;二是现有模型泛化能力弱,难以在零样本设置下适应未知领域。通过提供8.3倍于先前数据集的场景覆盖、4K分辨率图像及高精度激光雷达深度真值,ZEDD为模型训练与评估建立了可靠基础。其意义在于促进了离焦深度估计从理论模拟向实际应用的转变,为开发具有强泛化能力的深度估计模型提供了关键数据支撑,推动了计算机视觉中三维场景理解技术的进步。
衍生相关工作
ZEDD数据集的发布催生了一系列相关经典工作,主要集中在网络架构设计与训练策略的创新上。基于该数据集,研究者提出了FOSSA网络,这是一种基于视觉Transformer的架构,通过引入焦点距离嵌入的堆栈注意力层,实现了跨焦点堆栈的高效信息交换。这一设计启发了后续工作如DualFocus和HybridDepth,它们进一步探索了变分优化与多阶段融合方法以提升深度估计精度。同时,ZEDD推动了对合成数据生成管道的改进,例如利用大规模RGBD数据集生成逼真焦点堆栈,促进了零样本泛化研究。这些衍生工作共同深化了对离焦深度估计机理的理解,并为计算机视觉中的度量深度恢复提供了新的技术路径。
以上内容由遇见数据集搜集并总结生成


