Major-TOM/Core-S2RGB-249k-DINOv2
收藏Hugging Face2026-05-04 更新2026-05-10 收录
下载链接:
https://hf-mirror.com/datasets/Major-TOM/Core-S2RGB-249k-DINOv2
下载链接
链接失效反馈官方服务:
资源简介:
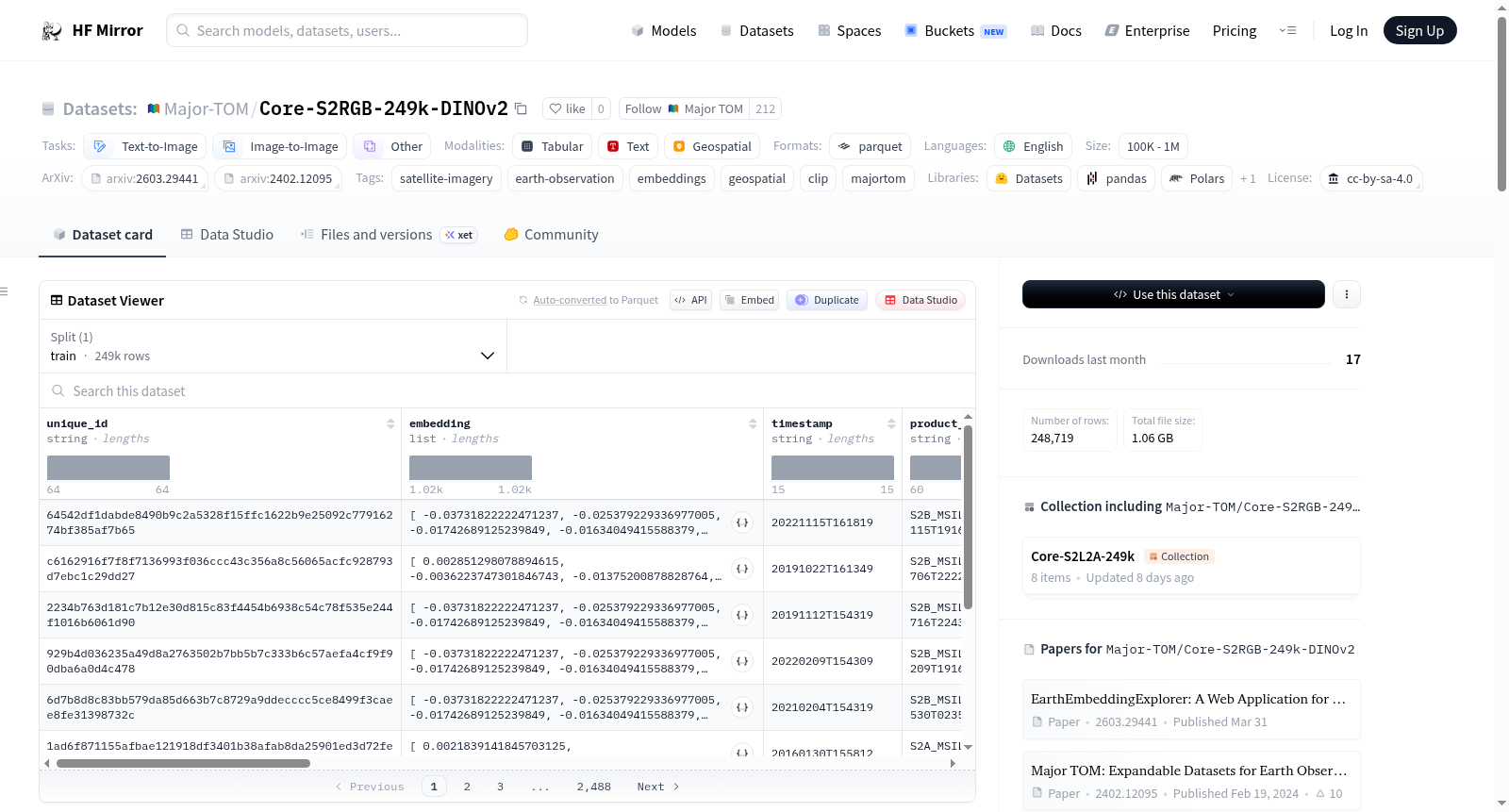
Core-S2RGB-249k-DINOv2是一个基于Core-S2L2A-249k数据集使用DINOv2-large模型计算的视觉嵌入数据集。数据集包含248,719个384×384像素的Sentinel-2 L2A图像块,经过预处理后生成768维的嵌入向量。输入波段为RGB(B04, B03, B02),输出格式为GeoParquet,嵌入维度为768。数据集的计算流程包括预处理、调整大小、编码、后处理和地理空间元数据保留。文件布局包括一个主要的嵌入GeoParquet文件和一个README文件。数据集的模式包括多个字段,如unique_id、embedding、timestamp等。
Core-S2RGB-249k-DINOv2 is a vision-only embedding dataset computed from Core-S2L2A-249k using the DINOv2-large model. The dataset contains 248,719 patches of 384 × 384 px Sentinel-2 L2A images, processed to produce 768-dimensional embeddings. The input bands are RGB (B04, B03, B02), and the output format is GeoParquet with an embedding dimension of 768. The computation pipeline includes pre-processing, resizing, encoding, post-processing, and preservation of geospatial metadata. The file layout consists of a main embedding GeoParquet file and a README file. The schema includes fields such as unique_id, embedding, timestamp, and others.
提供机构:
Major-TOM
搜集汇总
数据集介绍
构建方式
Core-S2RGB-249k-DINOv2数据集是基于Core-S2L2A-249k源影像构建而成,该源数据集包含248,719个384×384像素的Sentinel-2 L2A遥感影像块。构建流程首先对每个影像块的RGB波段(B04、B03、B02)进行叠加与归一化处理,通过2.5×(bands/1e4).clip(0,1)操作将其映射至真彩色图像范围内的[0,1]区间。随后采用最近邻插值将图像缩放至DINOv2-large模型所需的224×224像素输入尺寸。缩放后的RGB张量被送入自监督视觉Transformer模型DINOv2-large中,提取维度为768的CLS标记嵌入向量。生成过程中未对嵌入向量进行L2归一化处理,以保留在检索时按需归一化的灵活性。最终,原始UTM地理足迹被重投影至EPSG:4326坐标系,以获取几何边界、中心经纬度等字段,并与源数据集中的元数据一同存储于GeoParquet格式文件中。
特点
该数据集的核心特点在于将自监督视觉表征学习与地理空间信息深度耦合,为遥感图像检索与分析提供了一种纯净的视觉嵌入资源。每个影像块的嵌入向量由DINOv2-large模型从RGB三波段中提取,该模型在大规模自然图像上通过自蒸馏策略学习到丰富的语义特征,使其编码结果具备较强的场景泛化表达能力。区别于直接在遥感数据上训练的模型,DINOv2的嵌入为跨模态检索与零样本迁移提供了兼容自然图像与卫星影像的通用表征空间。每个样本还携带详尽的地理上下文维度,包括精确的地理坐标、采集时间戳、源产品标识及格网索引,使得嵌入向量能够与空间位置、时间序列等多维信息联合使用。数据集规模接近25万条嵌入记录,覆盖全球多个区域,为大规模地理空间分析奠定了数据基础。
使用方法
用户可通过主流数据处理框架轻松调用该数据集。使用Pandas库的read_parquet函数可直接读取主文件DINOv2_crop_384x384.parquet,加载包含248,719条嵌入记录的DataFrame。每条记录包含一个768维的浮点型嵌入向量,可通过索引访问其形状以确认维度。数据集无需额外预处理,用户在检索或相似度计算任务中可按需对嵌入向量执行L2归一化处理。地理元数据字段如geometry、centre_lat与centre_lon支持空间过滤与区域子集提取;timestamp字段可用于时序分析;grid_cell与product_id则便于溯源原始影像。对于需要存储或交换嵌入的应用场景,GeoParquet格式的高效列式存储特性可显著降低I/O开销。建议引用原始Major-TOM论文与DINOv2论文以尊重学术贡献。
背景与挑战
背景概述
得益于自监督视觉Transformer(ViT)的迅猛发展,DINOv2等模型在自然图像领域展现出卓越的表征能力,然而跨模态地理空间检索任务仍面临特征鸿沟与语义对齐的双重挑战。在此背景下,由Zheng、Czerkawski等研究团队于2026年构建的Core-S2RGB-249k-DINOv2数据集应运而生,它基于Major-TOM框架下的Core-S2L2A-249k卫星影像原片,通过DINOv2-large模型提取768维CLS令牌嵌入特征。该数据集的核心研究问题在于探究纯粹RGB波段输入下,自监督视觉模型对遥感图像的编码有效性及其在地理跨模态检索中的泛化性能,其发布为全球卫星图像类人语义比对提供了标准化特征基准。
当前挑战
该数据集所应对的领域挑战聚焦于遥感影像表征的模态差异性,具体表现为:1)空间域对齐难题,原始Sentinel-2多光谱影像需经波段筛选与归一化处理(2.5倍缩放至[0,1]),再经最近邻插值压缩至224×224像素,此过程必然引入细节损失与光谱信息混淆,增加特征判别难度;2)跨域泛化困境,DINOv2模型天然受限于自然图像预训练权重,对地理空间地物的纹理、尺度与结构先验缺乏针对性适配,易产生领域漂移。构建过程中亦面临元数据维护挑战,248,719个影像块需精确投影至WGS-84坐标体系并融合时间戳、网格标识等多源字段,任何一步转换误差都将污染查询与检索结果的拓扑一致性。
常用场景
经典使用场景
Core-S2RGB-249k-DINOv2数据集的核心应用在于为遥感影像提供高层次的语义特征提取与表征。该数据集利用DINOv2-large模型对来自Sentinel-2卫星的RGB波段图像进行自监督编码,生成768维的全局特征嵌入。这些嵌入向量捕捉了地物在视觉语义层面的抽象信息,广泛应用于基于内容的遥感图像检索、大规模土地覆盖分类、场景相似度匹配以及跨模态地理空间搜索等任务。借助其统一的地理空间元数据,用户可以高效地完成空间数据挖掘与分析。
解决学术问题
该数据集有效解决了遥感领域中高质量语义嵌入数据匮乏的核心难题。传统基于像素或手工特征的表示方法难以处理大范围、高变异的卫星图像,而Core-S2RGB-249k-DINOv2提供的自监督视觉嵌入为地理空间场景理解提供了通用且鲁棒的底层特征。研究者借助这一嵌入数据集,可以绕过昂贵的标注成本,开展多尺度地理模式识别、跨区域影像匹配以及零样本场景分类等前沿课题,推动了深度学习在遥感领域的可复现性和大规模应用。
衍生相关工作
该数据集催生了一系列富有影响力的后续工作。基于其嵌入表征,EarthEmbeddingExplorer应运而生,构建了全球卫星影像的跨模态检索Web应用,在ICLR 2026 Workshop中脱颖而出。此外,研究者利用该嵌入库进行了迁移学习下的遥感场景分类基准测试,验证了自监督视觉特征在地理空间任务中的泛化能力。同时,该数据集也成为了Multi-modal Earth Observation Retrieval等竞赛的标准评测基底,推动了地理空间人工智能领域的公开基准建立。
以上内容由遇见数据集搜集并总结生成


