kth8/gpt-oss-20b-MedXpertQA-benchmark
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/kth8/gpt-oss-20b-MedXpertQA-benchmark
下载链接
链接失效反馈官方服务:
资源简介:
---
license: apache-2.0
language:
- en
base_model: openai/gpt-oss-20b
datasets:
- TsinghuaC3I/MedXpertQA
---
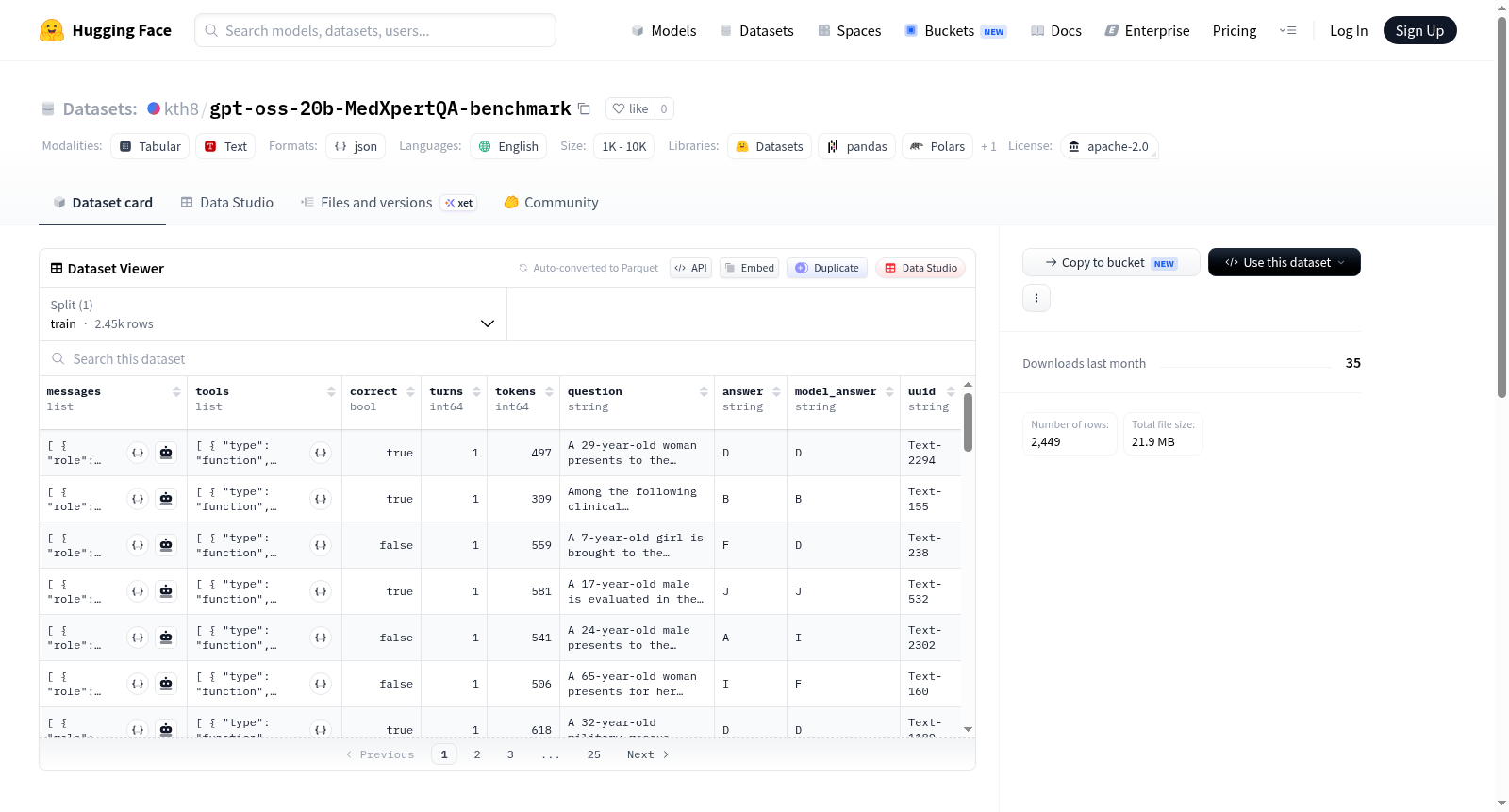
Benchmark of [openai/gpt-oss-20b](https://huggingface.co/openai/gpt-oss-20b) against [TsinghuaC3I/MedXpertQA](https://huggingface.co/datasets/TsinghuaC3I/MedXpertQA) dataset, "Text" subset, "test" split.
Accuracy: 27.1%.
| Metric | Value |
|----------------------|---------------|
| **Correct** | 664 |
| **Incorrect** | 1785 |
| **Errors** | 1 |
| **Total samples** | 2450 |
| **Total completion tokens** | 3,163,003 |
Raw stats:
```json
{
"accuracy": 0.271,
"correct": 664,
"incorrect": 1785,
"error": 1,
"total": 2450,
"completion_tokens": 3163003
}
```
Benchmark of openai/gpt-oss-20b against TsinghuaC3I/MedXpertQA dataset, Text subset, test split, including accuracy, number of correct and incorrect samples, errors, total samples, and total completion tokens.
提供机构:
kth8
搜集汇总
数据集介绍
构建方式
本数据集旨在评估开源语言模型gpt-oss-20b在医学知识问答任务上的表现,基于清华大学C3I团队构建的MedXpertQA数据集中的“Text”子集及“test”划分构建而成。通过统一调用模型对2450个医学测试样本进行推理生成,并记录每次回答的正确性、错误类型及所消耗的完成令牌数,系统性地收集了模型的输出结果与基准标签的比对信息,最终整理为一份结构化的评测基准数据集。
特点
该数据集的核心特征在于提供了对gpt-oss-20b在专业医学问答场景下性能的首次公开基准测试结果,包含详细的逐样本正确/错误标注、错误计数以及完成令牌消耗统计。整体准确率为27.1%,其中正确样本664例,错误样本1785例,错误仅1例,样本覆盖全面且评估指标完备,为后续开源医学大模型的能力对比与迭代优化提供了可靠且可复现的参考基线。
使用方法
研究者可直接加载该数据集用于复现gpt-oss-20b在MedXpertQA测试集上的评估结果,或将其作为其他医学问答模型的性能对照基准。数据集以标准格式存储,可通过HuggingFace Datasets库轻松读取,用户亦可依据其中的正确性标签与完成令牌数,进一步分析模型在不同医学子领域上的表现差异及计算效率,进而指导模型选择与改进方向。
背景与挑战
背景概述
在自然语言处理与生物医学交叉领域,大语言模型的能力评估始终是核心议题。gpt-oss-20b-MedXpertQA-benchmark由清华大学C3I团队于近期构建,旨在系统评估开源模型GPT-OSS-20B在医学知识问答任务上的表现。该基准基于MedXpertQA数据集中的文本子集及测试集,聚焦于模型对专业医学问题的推理与生成能力。作为首个针对20B参数级开源模型在医学问答领域的公开评估,该基准填补了中等规模开源模型在医疗场景下性能量化的空白,为后续模型优化与领域应用提供了关键参照,对推动开源模型在精准医疗中的可信部署具有重要启示。
当前挑战
当前该基准面临的核心挑战包括:1)领域适配难题:20B参数模型在医学问答中准确率仅27.1%,远低于临床可用标准,暴露出模型在术语理解、知识推理与长尾病症识别上的深度不足,亟需解决医学领域预训练与微调策略的优化问题。2)构建过程挑战:评估涉及2450个样本,但单次推理即消耗超300万完成令牌,导致计算开销巨大;同时数据集仅含单一模型与单次分割的测试结果,缺乏跨模型、跨数据划分的鲁棒性验证,易产生性能偏差。这些挑战制约了基准的可推广性与资源效率,需通过模型缩放、数据增强及多维度评估体系加以克服。
常用场景
经典使用场景
该数据集作为医学领域大规模语言模型的标准化评测基准,其经典使用场景在于衡量通用型开源模型在专业医疗知识问答任务中的表现能力。通过将openai/gpt-oss-20b模型在MedXpertQA数据集“Text”子集的“test”划分上进行零样本评估,研究者能够系统性地检验模型对复杂医学问题的理解与生成准确率。这一过程不仅为模型性能提供了可重复的量化指标,更揭示出当前通用大模型在专业医学领域精度的显著局限性,为后续针对性优化指明了方向。
解决学术问题
该数据集针对的核心学术问题是:通用预训练语言模型在高度专业化的医学知识领域中的泛化能力与可靠性评估。在学术研究中,模型在MedXpertQA上仅取得27.1%的准确率,直观地揭示了现有开源大模型在应对专业医学问答时存在的知识盲区与推理短板。这一发现推动了关于模型知识边界、领域特异性微调策略以及跨学科知识迁移机制的研究,促使学界重新审视通用模型在安全敏感场景中部署的风险与挑战。
衍生相关工作
基于该基准的评估结果,衍生出若干具有影响力的相关工作。研究者利用其揭示的性能短板,设计了面向医学领域的指令微调数据集与训练策略,显著提升了模型在MedXpertQA上的准确率。同时,该基准被用作验证测试集,评估了包括检索增强生成、知识图谱注入以及多阶段推理框架在内的多种增强方法。此外,它还催生了关于模型置信度校准与医疗错误成本量化分析的系列研究,推动了负责任医疗AI的发展。
以上内容由遇见数据集搜集并总结生成


