COINjecture/NP-Solutions
收藏Hugging Face2026-04-11 更新2026-04-12 收录
下载链接:
https://hf-mirror.com/datasets/COINjecture/NP-Solutions
下载链接
链接失效反馈官方服务:
资源简介:
---
license: mit
task_categories:
- other
language:
- en
tags:
- blockchain
- proof-of-work
- np-complete
- optimization
- energy-measurement
- consensus
size_categories:
- 1K<n<10K
---
# COINjecture NP-Solutions Dataset
## Dataset Description
This dataset contains real-time blockchain data from the COINjecture Network, a proof-of-useful-work (PoUW) blockchain that uses NP-complete problems for consensus. This is a **unified, continuous dataset** that includes all problem types (SubsetSum, SAT, TSP, Custom) and consensus blocks in a single repository for comprehensive analysis.
### Dataset Summary
The COINjecture Network is a blockchain that replaces traditional proof-of-work mining with solving useful computational problems. This unified dataset captures:
- **Problem Submissions**: NP-complete problems (SubsetSum, SAT, TSP, Custom) submitted to the network
- **Solution Submissions**: Solutions to problems with verification metrics
- **Consensus Blocks**: Complete block data including transactions, PoUW metrics, and energy measurements
Records are produced by **network nodes** (see `coinject_huggingface::DatasetRecord` in this repo) and uploaded as JSONL to the Hub. They are **not** the same artifact as other exports (e.g. API index tables); use this dataset for raw node-emitted training and research corpora.
**All problem types are stored in a single continuous dataset** (`COINjecture/NP-Solutions`) to enable cross-problem-type analysis and unified research workflows.
### Supported Tasks
- **Research**: Study of NP-complete problem solving performance
- **Energy Analysis**: Energy consumption patterns in computational problem solving
- **Blockchain Analytics**: Consensus mechanism performance and transparency metrics
- **Machine Learning**: Training models on problem-solution pairs
### Languages
English (problem descriptions and metadata)
## Explorer-style layout (reference)
The JSONL rows are the source of truth; the layout below is the **recommended human-readable presentation** for explorers, dashboards, and docs. Times like `15s ago` are computed from `timestamp` (Unix seconds) relative to “now” when rendering.
### Example — SAT (consensus / mined block)
```text
Block #123525
SAT
15s ago
Problem:
Satisfy 78 clauses with 26 variables
Solution:
Satisfying assignment found
Solver: 74446bf9...d77e15
Reward (BEANS)
124,324,271
Work (bits)
12.432
Asymmetry
5725.40×
Quality
1.000
Δt: 28.6 ms solve / 0.01 ms verify
Est. energy: 2.9 J
```
### Example — SubsetSum (consensus / mined block)
```text
Block #123524
SubsetSum
20s ago
Problem:
Find subset summing to 3938
Values: [55, 683, 630, 222, 651, 376, 332, 38, 827, 191, 292, 485, 453, 744, 403, 283, 717, 823, 350, 55, 928, 967, 995, 384, 354, 979, 733, 488, 882, 708, 67, 309, 751, 831]
Solution:
Indices 9, 10, 18, 19, 23, 29, 30, 31, 32, 33 → Sum: 3938
Solver: 74446bf9...d77e15
Reward (BEANS)
110,826,140
Work (bits)
11.083
Asymmetry
2845.00×
Quality
1.000
Δt: 2.8 ms solve / 0.00 ms verify
Est. energy: (from total_energy_joules when present)
```
### Precomputed `explorer_card`
Current nodes set **`explorer_card`** on each emitted row to the same layout as below (UTC time line). For custom viewers you can print `record["explorer_card"]` directly, or rebuild from fields using the Python helper in this README.
### Line-by-line mapping (JSONL → display)
| Display | JSON fields / rule |
|--------|----------------------|
| **Block #…** | `block_height` |
| **Type line** (SAT, SubsetSum, …) | `problem_type` |
| **Relative time** | `timestamp` vs viewer clock (e.g. `format_relative(timestamp)`) |
| **Problem:** | Derived from `problem_data` by type (see below) |
| **Solution:** | Derived from `solution_data` + `problem_data` (see below) |
| **Solver:** | `solver` or `submitter` (hex); show as `first8...last6` for privacy |
| **Reward (BEANS)** | `bounty` (string u128) or formatted integer — native reward units on the network |
| **Work (bits)** | `work_score` when set; format with fixed decimals (e.g. 3) |
| **Asymmetry** | `time_asymmetry` (solve/verify time ratio); suffix `×` |
| **Quality** | `solution_quality` when set (0–1 scale) |
| **Δt:** | `solve_time_us`, `verify_time_us` → ms: `solve_time_us / 1000`, `verify_time_us / 1000` |
| **Est. energy** | `total_energy_joules` (or sum of solve/verify energy fields) with one decimal and ` J` |
**SAT — Problem line:** From `problem_data.clauses` length and `problem_data.variables` (or equivalent):
`Satisfy {n_clauses} clauses with {n_vars} variables`.
**SAT — Solution line:** If `solution_data.assignments` exists: “Satisfying assignment found” (or list assignment preview for research dumps).
**SubsetSum — Problem line:** `Find subset summing to {problem_data.target}` plus `Values: {problem_data.numbers}` (truncate with “…” if extremely long).
**SubsetSum — Solution line:** `Indices {comma-separated} → Sum: {target}` where indices are `solution_data.indices` and target is `problem_data.target` (recompute sum for verification in tooling).
**TSP / Custom:** Use the same block header; problem/solution lines should summarize `problem_data` / `solution_data` (tour length, custom label) — extend the same pattern.
### Optional: Python sketch
```python
from __future__ import annotations
import time
from typing import Any, Mapping
def _rel_ago(ts: int) -> str:
s = max(0, int(time.time()) - int(ts))
if s < 60:
return f"{s}s ago"
if s < 3600:
return f"{s // 60}m ago"
return f"{s // 3600}h ago"
def _addr_short(hex64: str | None) -> str | None:
if not hex64 or len(hex64) < 16:
return hex64
return f"{hex64[:8]}...{hex64[-6:]}"
def _fmt_int_string(s: str | None) -> str:
if not s:
return "—"
try:
return f"{int(s):,}"
except ValueError:
return s
def problem_line(pt: str, pd: Mapping[str, Any]) -> str:
if pt == "SAT":
n_c = len(pd.get("clauses") or [])
n_v = int(pd.get("variables") or 0)
return f"Satisfy {n_c} clauses with {n_v} variables"
if pt == "SubsetSum":
nums = pd.get("numbers") or []
tgt = pd.get("target")
return f"Find subset summing to {tgt}\nValues: {nums}"
return str(pd)
def solution_line(pt: str, pd: Mapping[str, Any], sd: Mapping[str, Any] | None) -> str:
if sd is None:
return "—"
if pt == "SAT":
return "Satisfying assignment found"
if pt == "SubsetSum":
idx = sd.get("indices") or []
tgt = pd.get("target")
return f"Indices {', '.join(str(i) for i in idx)} → Sum: {tgt}"
return str(sd)
def format_block_card(r: Mapping[str, Any]) -> str:
pt = r.get("problem_type") or "?"
pd = r.get("problem_data") or {}
sd = r.get("solution_data")
ws = r.get("work_score")
ta = r.get("time_asymmetry")
q = r.get("solution_quality")
su = r.get("solve_time_us") or 0
vu = r.get("verify_time_us") or 0
ej = r.get("total_energy_joules")
lines = [
f"Block #{r.get('block_height', '?')}",
str(pt),
_rel_ago(int(r.get("timestamp") or 0)),
"",
"Problem:",
problem_line(pt, pd),
"",
"Solution:",
solution_line(pt, pd, sd),
"",
f"Solver: {_addr_short(r.get('solver') or r.get('submitter'))}",
"",
"Reward (BEANS)",
_fmt_int_string(r.get("bounty")),
"",
"Work (bits)",
f"{ws:.3f}" if isinstance(ws, (int, float)) else "—",
"",
"Asymmetry",
f"{ta:.2f}×" if isinstance(ta, (int, float)) else "—",
"",
"Quality",
f"{q:.3f}" if isinstance(q, (int, float)) else "—",
"",
f"Δt: {su / 1000:.1f} ms solve / {vu / 1000:.2f} ms verify",
]
if isinstance(ej, (int, float)):
lines.append(f"Est. energy: {ej:.1f} J")
return "\n".join(lines)
```
## Dataset Structure
### Data Instances
Each record in the dataset represents either:
1. A problem submission (when a problem is submitted to the network)
2. A solution submission (when a solution is verified)
3. A consensus block (complete block data with all transactions)
### Data Fields
| Field | Type | Description |
|-------|------|-------------|
| **PRIMARY CONTENT** |||
| `problem_id` | string | Unique identifier for the problem |
| `problem_type` | string | Type of problem: "SubsetSum", "SAT", "TSP", "Custom", or "Private" |
| `problem_data` | object | Complete problem data (JSON object) |
| `solution_data` | object (optional) | Solution data with normalized structure |
| `explorer_card` | string | Preformatted explorer-style card (multi-line text). Uses **absolute UTC** from `timestamp` in the card (not “Ns ago”). Omitted or empty on legacy JSONL without this field. |
| **IDENTIFIERS** |||
| `block_height` | int64 | Block height when the record was created |
| `timestamp` | int64 | Unix timestamp (consensus rows: block header time; marketplace rows may use ingest time — see `metrics_source`) |
| `submitter` | string (optional) | Address of the problem submitter (hex encoded) |
| `solver` | string (optional) | Address of the solution solver (hex encoded) |
| **PERFORMANCE METRICS** |||
| `problem_complexity` | float64 | Complexity score of the problem |
| `bounty` | string | Bounty amount in native tokens (serialized as string to avoid JSON precision loss) |
| `work_score` | float64 (optional) | Work score calculated for the solution |
| `solution_quality` | float64 (optional) | Quality score of the solution |
| **ASYMMETRY METRICS** |||
| `time_asymmetry` | float64 (optional) | Ratio of solve_time / verify_time |
| `space_asymmetry` | float64 (optional) | Memory asymmetry metric |
| `energy_asymmetry` | float64 (optional) | Energy asymmetry ratio |
| **ENERGY MEASUREMENTS** |||
| `solve_energy_joules` | float64 (optional) | Energy consumed during solving (joules) |
| `verify_energy_joules` | float64 (optional) | Energy consumed during verification (joules) |
| `total_energy_joules` | float64 (optional) | Total energy consumption (joules) |
| `energy_per_operation` | float64 (optional) | Energy per operation estimate |
| `energy_efficiency` | float64 (optional) | Energy efficiency metric |
| **TIMING (consensus / detailed rows)** |||
| `solve_time_us` | uint64 (optional) | Solve duration in microseconds (→ ms in explorer) |
| `verify_time_us` | uint64 (optional) | Verify duration in microseconds |
| **MINING / CONSENSUS** |||
| `difficulty_target` | uint32 (optional) | Minimum leading zero bits in block hash (node PoW setting) |
| `nonce` | uint64 (optional) | Winning header nonce |
| **METADATA** |||
| `status` | string | Status: "Pending", "Solved", "Mined", "Validated", etc. |
| `submission_mode` | string | Submission mode: "public", "private", or "mining" |
| `energy_measurement_method` | string | Method used: "rapl", "powermetrics", or "estimate" |
| **DATA PROVENANCE** |||
| `metrics_source` | string | Source of metrics: "block_header_actual", "measured_marketplace", "estimated", or "not_applicable" |
| `measurement_confidence` | string | Confidence level: "high" (from header), "medium" (proxy/measured), "low" (estimate), or "not_applicable" |
| `data_version` | string | Dataset schema version (e.g. `v3.1` — see `huggingface/src/metrics.rs`) |
Consensus and marketplace paths may populate **additional optional fields** (timing, memory, energy, network, mining, hardware, economics). The full schema is `DatasetRecord` in `huggingface/src/client.rs`.
### Solution Data Structure
Solutions are normalized to a consistent structure to avoid schema conflicts:
```json
{
"type": "SubsetSum" | "SAT" | "TSP" | "Custom",
"data": <normalized data>
}
```
- **SubsetSum**: `data` is an array of indices (numbers)
- **SAT**: `data` is an array of 0/1 values (normalized from booleans)
- **TSP**: `data` is an array representing the tour (numbers)
- **Custom**: `data` is a base64-encoded string
### Problem Data Structure
For consensus blocks, `problem_data` contains comprehensive block information:
```json
{
"height": <block_height>,
"miner": <miner_address>,
"transactions": [...],
"solution_reveal": {
"problem": {...},
"solution": {
"type": "...",
"data": [...]
},
"commitment_hash": "...",
"problem_hash": "..."
},
"solve_time_us": <time_in_microseconds>,
"verify_time_us": <time_in_microseconds>,
"energy_estimate_joules": <energy>,
...
}
```
## Dataset Creation
### Source Data
Data is collected in real-time from running COINjecture Network nodes. Each node pushes records to this dataset when:
- A problem is submitted via transaction
- A solution is submitted and verified
- A consensus block is mined or validated
### Data Collection Process
1. **Problem Submission**: When a problem transaction is processed, a record is created with problem data
2. **Solution Submission**: When a solution is verified, metrics are calculated and a record is created
3. **Consensus Blocks**: Complete block data is recorded for transparency and analysis
### Data Preprocessing
- Solutions are normalized to consistent schema (see Solution Data Structure)
- Energy measurements use multiple methods (RAPL, powermetrics, or estimation)
- Addresses are hex-encoded for consistency
- Timestamps are Unix epoch seconds
- Large integers (u128) are serialized as strings to avoid JSON precision loss
- All problem types are unified in a single continuous dataset for cross-problem analysis
## Dataset Statistics
- **Total Records**: Growing in real-time (unified dataset with all problem types)
- **Update Frequency**: Real-time (buffered, flushed when 10 total records accumulated across all problem types)
- **Data Format**: JSONL (newline-delimited JSON)
- **Storage Location**: `/data/` directory in the repository
- **Problem Types**: SubsetSum, SAT, TSP, Custom, Private (all in one dataset)
- **Data Quality**: v3.1 institutional-grade records when emitted by current nodes (block header and extended metrics where available)
## Considerations for Using the Data
### Ethical Considerations
- All data is from public blockchain transactions
- Addresses are included only if explicitly enabled (privacy option)
- No personally identifiable information is collected
### Licensing
This dataset is released under the MIT License.
### Citation Information
If you use this dataset in your research, please cite:
```bibtex
@dataset{coinjecture_np_solutions,
title={COINjecture NP-Solutions Dataset},
author={COINjecture Network},
year={2024},
url={https://huggingface.co/datasets/COINjecture/NP-Solutions}
}
```
## Dataset Access
### Using Hugging Face Datasets
```python
from datasets import load_dataset
# Load the dataset
dataset = load_dataset("COINjecture/NP-Solutions", split="train")
# Access records
for record in dataset:
print(record["problem_id"])
print(record["problem_data"])
```
### Direct File Access
The raw JSONL files are available in the `/data/` directory:
- Files are named `data_<timestamp>.jsonl`
- Each line is a complete JSON record
- Files can be processed with standard JSONL tools
### API Access
The dataset is accessible via the Hugging Face API:
- Dataset viewer: https://huggingface.co/datasets/COINjecture/NP-Solutions
- API endpoint: `https://huggingface.co/api/datasets/COINjecture/NP-Solutions`
### Uploading with the Hugging Face CLI
For manual pushes (exports, Parquet/JSONL, README updates), use the [`hf` CLI](https://huggingface.co/docs/huggingface_hub/guides/cli):
```bash
brew install hf
# Optional: interactive login (or rely on HF_TOKEN in the environment)
hf auth login
# From the directory that contains the files you want on the Hub:
hf upload COINjecture/NP-Solutions . --repo-type=dataset
```
Set `HF_DATASET_NAME` / `--hf-dataset-name` to this repo’s Hub id (`COINjecture/NP-Solutions`). Hyphen vs underscore are different Hub repositories if both exist.
## Additional Information
### Energy Measurement Methods
- **RAPL** (Linux): Intel/AMD Running Average Power Limit counters
- **powermetrics** (macOS): macOS powermetrics tool
- **estimate**: CPU TDP-based estimation (fallback, works everywhere)
### Problem Types
1. **SubsetSum**: Find a subset of numbers that sum to a target
2. **SAT**: Boolean satisfiability problem
3. **TSP**: Traveling Salesman Problem
4. **Custom**: Arbitrary problem data (base64 encoded)
### Performance Metrics
- **Time Asymmetry**: Measures how much harder solving is than verifying
- **Space Asymmetry**: Memory usage differences
- **Energy Asymmetry**: Energy consumption differences
- **Energy Efficiency**: Work performed per unit of energy
## Contact
For questions or issues:
- Dataset repository: https://huggingface.co/datasets/COINjecture/NP-Solutions
- Open a discussion on the dataset page
## Changelog
### 2026-04-10
- **`explorer_card` field**: Each JSONL row includes a precomputed multi-line card (UTC time); implemented in `huggingface/src/explorer_card.rs`.
- **Explorer layout**: Documented the block-card presentation (block #, type, time, problem/solution prose, solver, BEANS reward, work, asymmetry, quality, Δt, energy) with line-by-line JSON mapping and a Python `format_block_card` helper.
### 2025-11-23
- **Unified Dataset**: Consolidated all problem types (SubsetSum, SAT, TSP, Custom) into a single continuous dataset
- **Schema Fix**: Fixed u128 bounty serialization (now serialized as string to avoid JSON precision loss)
- **Data Provenance**: Added institutional-grade data provenance fields (metrics_source, measurement_confidence, data_version)
- **Unified Buffer**: Changed from per-problem-type buffers to unified buffer that flushes all types together
- **Enhanced Metrics**: All consensus blocks now include actual block header metrics (high confidence)
提供机构:
COINjecture
搜集汇总
数据集介绍
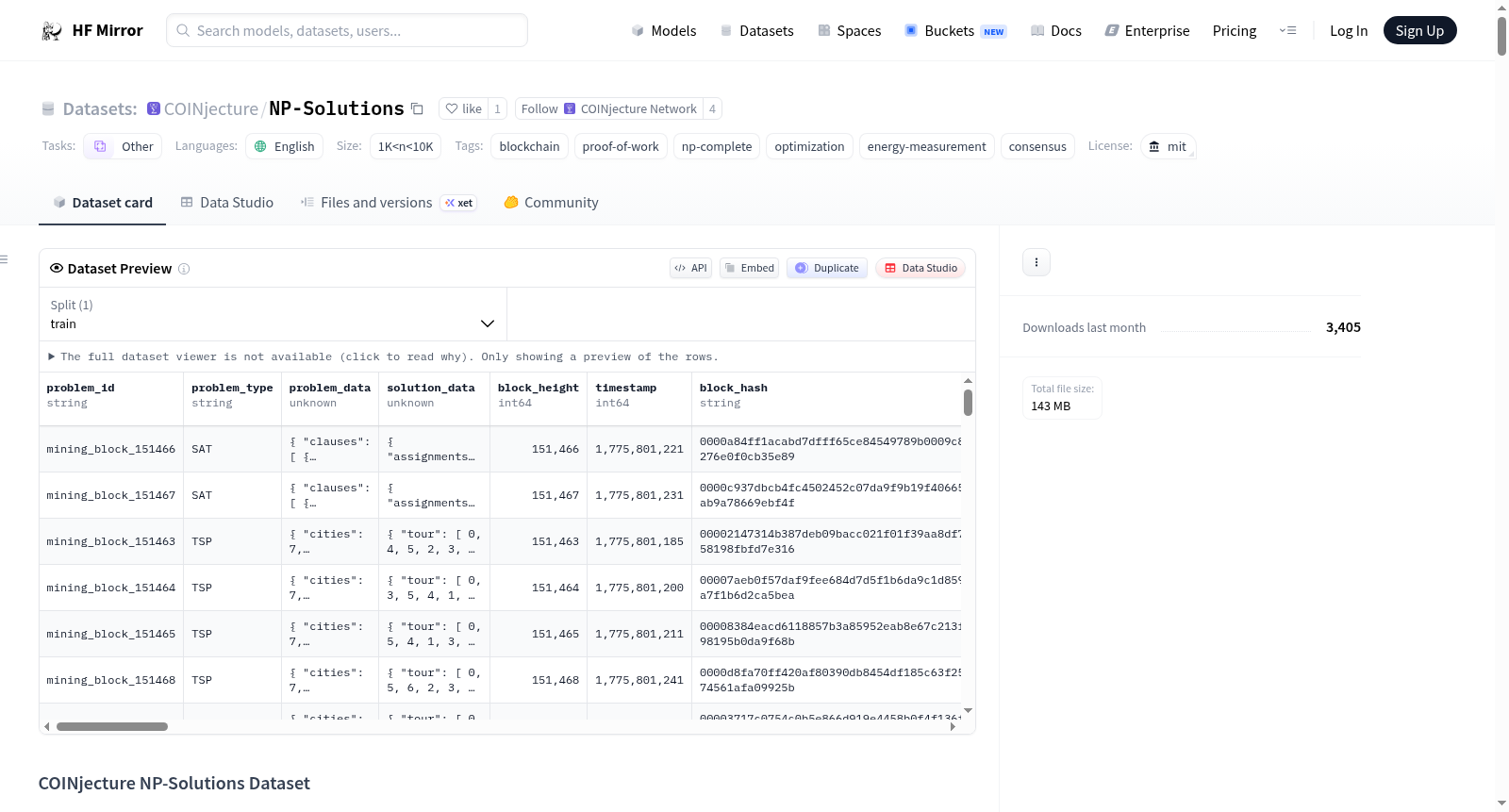
构建方式
在区块链技术领域,NP-Solutions数据集通过实时捕获COINjecture网络的运行数据构建而成,该网络采用有用工作量证明机制,利用NP完全问题达成共识。数据收集过程由网络节点驱动,每当问题提交、解决方案验证或共识区块生成时,节点会生成包含问题数据、解决方案及性能指标的记录,并以JSONL格式上传至数据集仓库。所有记录均经过规范化处理,确保解决方案数据结构一致,能量测量采用多种方法,时间戳统一为Unix纪元秒,大型整数以字符串形式序列化以避免精度损失,从而形成一个统一、连续且支持跨问题类型分析的高质量数据集。
特点
该数据集的核心特点在于其统一性与实时性,它将子集和、布尔可满足性、旅行商问题及自定义问题等多种NP完全问题类型整合于单一连续数据流中,便于进行跨问题类型的综合研究。数据集不仅包含问题与解决方案的原始数据,还涵盖了丰富的时间不对称性、空间不对称性、能量消耗及效率等性能指标,为区块链共识机制、计算复杂性及能量分析提供了多维度的透明度量。此外,数据集结构经过精心设计,每条记录均附有预格式化的探索卡片,支持直接可视化呈现,同时通过规范化字段确保数据模式的一致性,避免了模式推断中的常见错误。
使用方法
研究人员可通过Hugging Face Datasets库直接加载该数据集,利用其统一的JSONL格式进行数据访问与分析。数据集适用于多个研究任务,包括NP完全问题求解性能研究、区块链共识机制的能量消耗模式分析,以及基于问题-解决方案对的机器学习模型训练。用户可按照数据字段映射关系,提取区块高度、问题类型、时间戳、奖励及各类性能指标,结合提供的Python辅助函数重构人类可读的展示格式。对于高级应用,可直接处理原始JSONL文件,或利用数据集中预计算的探索卡片进行快速可视化,从而深入探究有用工作量证明区块链的运作细节与优化潜力。
背景与挑战
背景概述
NP-Solutions数据集由COINjecture网络于2024年创建,旨在为区块链共识机制的研究提供实证基础。该数据集的核心研究问题聚焦于将传统工作量证明机制替换为有用工作量证明,通过解决NP完全问题来实现共识,从而提升区块链系统的计算效用与能源效率。其统一且连续的数据结构,涵盖了子集和、布尔可满足性、旅行商问题及自定义问题等多种类型,为跨问题分析与性能评估提供了前所未有的资源,对分布式计算与密码学领域产生了深远影响。
当前挑战
该数据集致力于解决区块链共识机制中计算资源浪费的核心挑战,旨在量化有用工作量证明在解决NP完全问题时的性能与能耗表现。构建过程中的主要挑战包括实时数据采集的完整性保障、多种问题类型数据的统一规范化处理,以及能耗测量方法的跨平台一致性维护。此外,历史数据因字段缺失导致的模式不一致问题,也增加了数据集后续集成与分析的复杂性。
常用场景
经典使用场景
在区块链共识机制研究中,NP-Solutions数据集为探索有用工作量证明(PoUW)范式提供了核心实证基础。该数据集整合了多种NP完全问题(如子集和、布尔可满足性、旅行商问题)的实时求解记录与共识区块数据,使研究者能够系统分析不同计算难题在分布式网络中的求解性能、时间不对称性以及能耗模式。通过统一存储多类问题实例及其对应的验证指标,该数据集支持跨问题类型的比较研究,为优化共识算法中的计算资源分配提供了关键基准。
衍生相关工作
围绕该数据集已衍生出多项聚焦于共识机制创新与计算资源优化的研究。经典工作包括基于其时间不对称性与能耗指标,设计新型PoUW协议以平衡安全性与实用性;亦有研究利用其问题-解决方案对训练神经网络,用于近似求解NP完全问题或评估求解器性能。此外,数据集支撑了区块链透明度与可审计性方面的分析,催生了针对共识过程能源足迹的计量经济学模型,为绿色计算与可持续区块链的发展提供了理论依据。
数据集最近研究
最新研究方向
在区块链共识机制革新领域,NP-Solutions数据集正推动着有用工作量证明(PoUW)范式的深度探索。该数据集整合了子集和、布尔可满足性、旅行商问题等多种NP完全问题的实时求解记录,为研究计算复杂性理论与分布式系统融合提供了独特实验场。前沿研究聚焦于构建新型非对称验证模型,通过分析求解与验证的时间、空间及能耗不对称性指标,优化共识算法的能源效率。同时,机器学习方法正被应用于问题-解决方案对的模式识别,旨在预测求解难度与资源消耗的关联规律。这些研究不仅回应了加密货币领域对可持续挖矿技术的迫切需求,也为计算复杂性理论在现实系统中的量化评估开辟了新路径。
以上内容由遇见数据集搜集并总结生成


