PranavKashyappp/delhi_air_quality_feature_store_processed.csv
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/PranavKashyappp/delhi_air_quality_feature_store_processed.csv
下载链接
链接失效反馈官方服务:
资源简介:
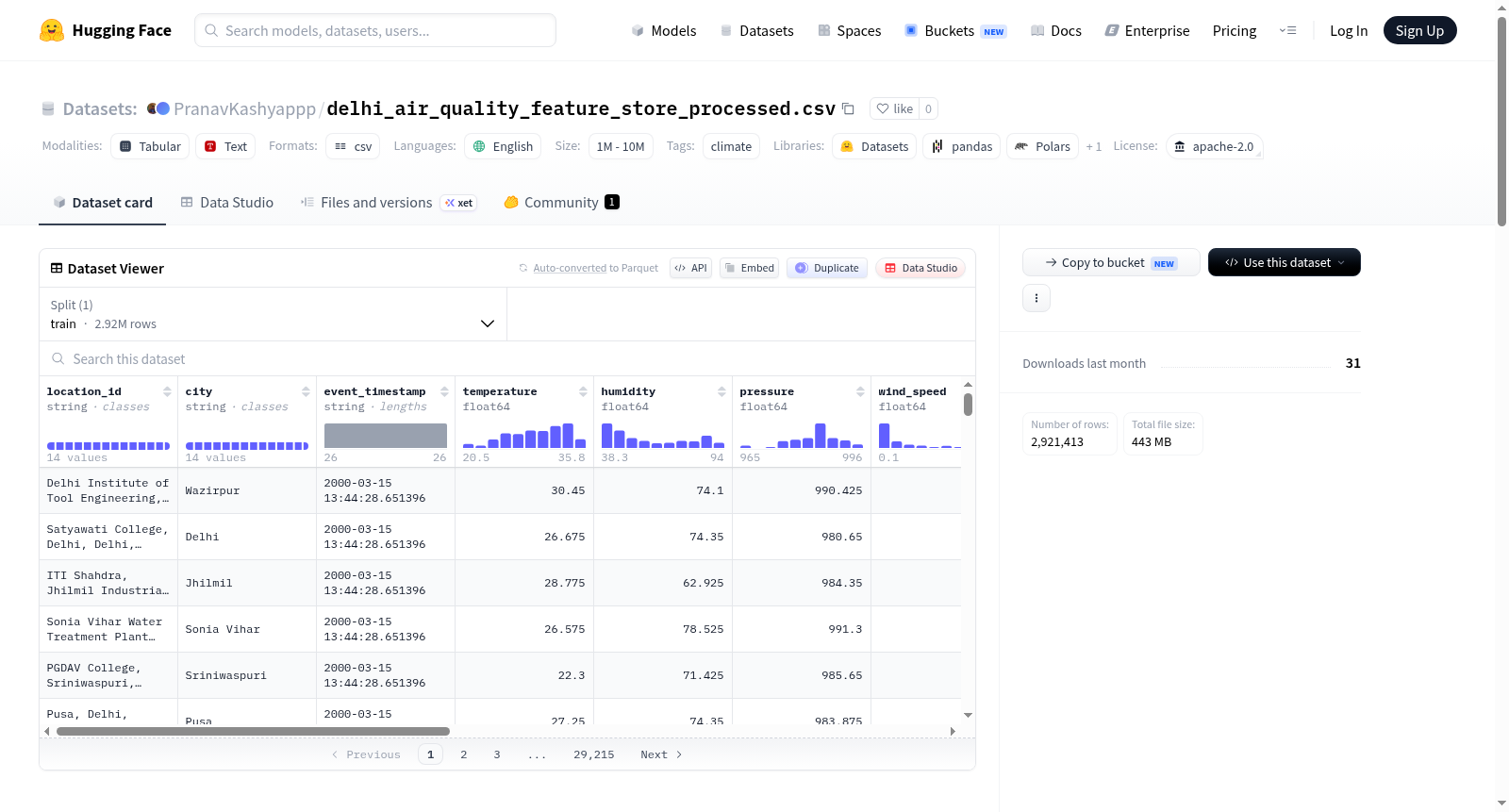
该数据集包含来自印度德里多个地点的290万行每小时气象和空气质量数据,时间跨度为2000年3月至2024年11月。数据包括环境参数如温度、湿度、大气压力、风速、风向以及污染物浓度(PM2.5、PM10、NO2、SO2、O3、CO)和相应的空气质量指数(AQI)。数据集已针对模型训练进行了预处理,包括删除AQI值为-的行(占总数据集的15%)、处理缺失值(通过删除、均值插补和最近邻插值等方法)以及识别和记录缺失数据的中心。此数据集专门为模型训练而设计,如需其他用途或可视化,可参考未处理版本的数据集。
This dataset contains 2.9M rows of hourly weather and air quality data from multiple locations across Delhi, India, collected from March 2000 to November 2024. The data includes environmental parameters such as temperature, humidity, atmospheric pressure, wind speed, wind direction, and concentrations of pollutants (PM2.5, PM10, NO2, SO2, O3, CO), along with the corresponding Air Quality Index (AQI). The data has been pre-processed for model training, including the following updates: Rows with AQI values marked as - have been removed, as they accounted for 15% of the total dataset. Missing values have been handled through various methods, including dropping, mean imputation, and nearest neighbor interpolation. Centers responsible for missing data have been identified and documented. This processed dataset is specifically curated for model training. For alternative uses or visualizations, you may refer to the unprocessed version of the dataset.
提供机构:
PranavKashyappp
搜集汇总
数据集介绍
构建方式
在全球城市化进程加速与空气污染问题日益严峻的背景下,该数据集应运而生,旨在为空气质量建模与气象预测研究提供高质量的训练资源。其构建基于印度德里地区2000年3月至2024年11月期间多个站点的小时级气象与空气质量原始观测数据,涵盖温度、湿度、气压、风速、风向等气象要素,以及PM2.5、PM10、NO2、SO2、O3、CO等六项污染物浓度与对应的空气质量指数(AQI)。为提升数据可用性,研究团队对原始数据进行了系统性预处理:首先剔除了AQI值为“-”的无效行(约占总数据量的15%),随后针对缺失值采取了多元策略,包括直接删除、均值填充及最近邻插值法,并对缺失数据的责任中心进行了追溯与记录,最终形成了包含约290万条记录的清洁数据集。
特点
该数据集的核心特色在于其大规模、长时序与高覆盖度的整合特性,集成了德里多个地理位置的实时环境监测信息,时间跨度近25年,记录数量达到290万行,为气候与污染趋势分析提供了坚实的数据基础。数据字段设计兼具气象与污染双重维度,既包含常规环境参数如温湿度与气压,也囊括了六种关键污染物浓度与综合AQI指标,便于多变量关联分析与模型训练。此外,数据经过规范化清洗与插补处理,缺失值得到妥善应对,数据质量显著提升,尤其适配于机器学习与深度学习模型的直接调用,降低了研究者预处理数据的负担,体现了从原始观测到工程化数据集的高效转化。
使用方法
借助Hugging Face的datasets库,研究者可便捷地加载该数据集。具体而言,通过执行`from datasets import load_dataset`,再运行`dataset = load_dataset('abhinavsarkar/delhi_air_quality_feature_store_processed.csv')`即可将数据导入工作环境。加载后的数据集可直接用于监督学习任务,如以AQI或特定污染物浓度为预测目标,或开展时序预测与回归分析。数据集的字段列名明确,包含数值型与时间戳型特征,方便进行特征工程与模型输入构建。研究人员也可根据自身需求对数据进一步划分训练集与测试集,或利用其气象变量作为协变量提升预测准确性。由于数据集已预处理好,用户无需额外清洗,能够快速聚焦于模型开发与实验验证。
背景与挑战
背景概述
该数据集由Abhinav于2024年构建并发布,聚焦印度德里自2000年3月至2024年11月间近25年的逐时空气质量与气象数据,涵盖温度、湿度、气压、风速风向及PM2.5、PM10、NO2、SO2、O3、CO等关键污染物浓度,并附有空气质量指数(AQI)。作为德里地区规模最大的公开处理数据集之一,其290万条记录为环境科学、公共卫生及机器学习领域提供了珍贵的高时间分辨率长序列资料,助力于空气污染动态建模、源解析及预警系统研究,对南亚区域环境治理具有重要推动力。
当前挑战
德里作为全球污染最严重的城市之一,其空气质量受季风、工业排放、交通及秸秆焚烧等多重因素交织影响,时空异质性极强,传统监测手段难以捕捉复杂非线性关系。构建过程中,数据集面临15%的AQI缺失行需剔除、多传感器数据融合时因设备故障与传输延迟导致的碎片化缺失问题,作者通过均值插补与近邻插值等策略处理,但部分极端污染事件的信息完整性仍受挑战。此外,不同测站数据质量参差,需溯源并标记负责中心,增加了预处理复杂度。
常用场景
经典使用场景
该数据集广泛应用于空气污染预测与空气质量指数(AQI)的时序建模任务中。研究者通常利用其涵盖超过二十年的逐小时气象与污染物浓度记录,构建基于循环神经网络、长短期记忆网络或Transformer架构的预测模型。数据集中丰富的多变量时间序列特征——如温度、湿度、风速及PM2.5、NO₂等浓度——为捕捉污染物扩散与气象因素之间的复杂非线性关系提供了坚实基础,使得短期空气质量预报与极端污染事件预警成为经典的研究切入点。
实际应用
在实际应用中,该数据集可赋能城市智能环境监测系统的开发。基于其训练出的空气质量预测模型能够为政府环保部门提供未来数小时内的AQI变化趋势,辅助制定重污染天气下的应急减排措施。同时,面向公众的个性化健康出行建议系统亦可从中受益,通过结合实时气象与污染数据,向敏感人群推送避开高污染时段与区域的行动方案,从而降低呼吸系统疾病的暴露风险。
衍生相关工作
该数据集衍生了多项具有影响力的研究工作,例如基于时序分解与集成学习的混合预测模型、融合空间相关性的图神经网络多站点污染物联合建模,以及利用生成对抗网络进行缺失数据插补的方法。部分工作进一步扩展了数据集的应用边界,将其与城市交通流量或能源消耗数据结合,探究人为活动对空气质量的间接影响。这些衍生成果不仅提升了原始数据的利用价值,也为跨领域的环境智能研究提供了可复用的基准与范式。
以上内容由遇见数据集搜集并总结生成


