GRS-QA
收藏arXiv2024-11-07 更新2024-11-12 收录
下载链接:
http://arxiv.org/abs/2411.00369v2
下载链接
链接失效反馈官方服务:
资源简介:
GRS-QA是由加州大学圣克鲁兹分校等机构创建的图推理结构化问答数据集,旨在解决现有问答数据集缺乏细粒度推理结构的问题。该数据集包含113,000个基于维基百科的问答对,通过构建推理图来明确捕捉复杂的推理路径。数据集的创建过程包括将每个句子视为节点,并根据原始逻辑关系添加边,同时生成结构负样本以研究结构对问答性能的影响。GRS-QA主要应用于评估大型语言模型在多跳推理任务中的表现,旨在解决复杂推理能力的需求。
GRS-QA is a structured question answering dataset for graph reasoning developed by institutions including the University of California, Santa Cruz, aiming to address the issue that existing QA datasets lack fine-grained reasoning structures. This dataset comprises 113,000 Wikipedia-based question-answer pairs, and explicitly captures complex reasoning paths through the construction of reasoning graphs. The dataset creation workflow involves treating each sentence as a node, adding edges based on original logical relationships, and generating structured negative samples to study the impact of structural features on QA performance. GRS-QA is primarily utilized to evaluate the performance of large language models (LLMs) in multi-hop reasoning tasks, and is designed to meet the demand for assessing models' complex reasoning capabilities.
提供机构:
加州大学圣克鲁兹分校, Adobe研究, 思科Outshift, 俄勒冈大学
创建时间:
2024-11-01
搜集汇总
数据集介绍
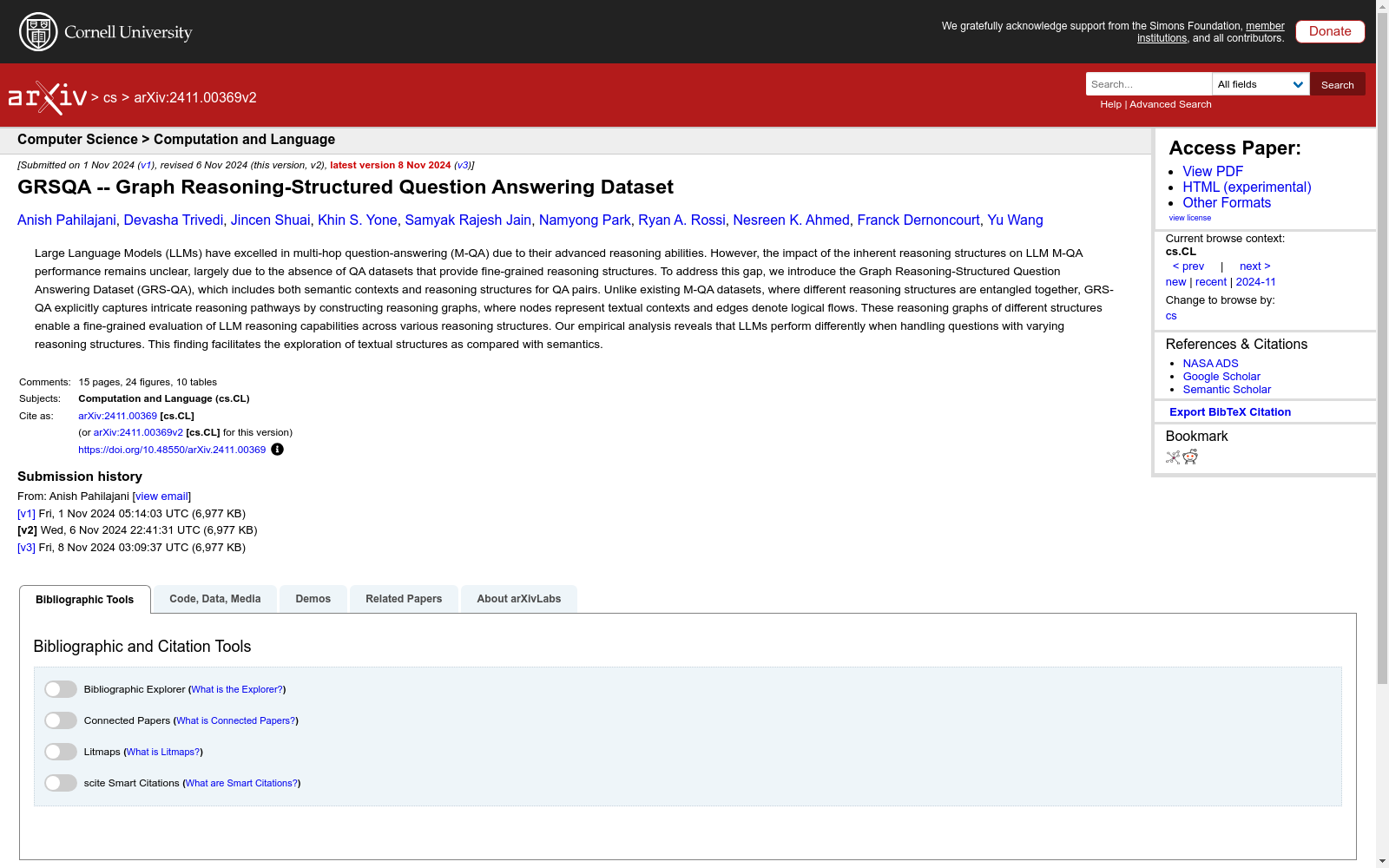
构建方式
GRS-QA数据集的构建基于三个现有的多跳问答数据集:HotpotQA、MuSiQue和2WikiMultiHopQA。这些数据集提供了多样且全面的推理结构。具体而言,每个问答对中的句子被视为节点,而节点之间的连接则基于原始数据集中的局部关系建立边。通过这种方式,构建了正向推理图和负向推理图。正向推理图展示了从问题到答案的金标准推理步骤,而负向推理图则通过扰动正向推理图的结构来生成,以研究结构对推理和问答性能的影响。
特点
GRS-QA数据集的显著特点在于其显式地捕捉了复杂的推理路径,通过构建推理图来实现。这些推理图不仅提供了透明的逻辑步骤,还根据其结构复杂性进行了分类,并附有元数据(如推理步骤数和类型),便于分析问题难度、推理复杂性和模型性能。此外,数据集还引入了负向推理图,通过结构扰动来研究结构对推理性能的独立影响,从而提供了对模型推理能力更细致的评估。
使用方法
GRS-QA数据集可用于评估大型语言模型在多跳问答任务中的推理能力。研究者可以通过分析模型在不同推理结构下的表现,来评估其在复杂推理任务中的性能。具体使用方法包括:首先,利用数据集中的正向推理图来训练和测试模型,以评估其在标准推理路径上的表现;其次,使用负向推理图来测试模型在结构扰动下的鲁棒性;最后,结合不同的推理图类型和元数据,开发新的评估指标,如推理召回率和精确率,以全面评估模型的推理能力。
背景与挑战
背景概述
近年来,大型语言模型(LLMs)在多跳问答(M-QA)任务中表现出色,得益于其先进的推理能力。然而,这些模型在处理复杂推理结构时的表现仍不明确,主要原因是缺乏提供细粒度推理结构的问答数据集。为了填补这一空白,加州大学圣克鲁兹分校、Adobe研究、Cisco Outshift和俄勒冈大学的研究人员共同推出了Graph Reasoning-Structured Question Answering Dataset(GRS-QA)。该数据集不仅包含语义上下文,还明确捕捉了推理路径,通过构建推理图来展示节点间的逻辑流。这些推理图的不同结构使得能够对LLMs在各种推理结构中的推理能力进行细粒度评估。GRS-QA的推出为研究LLMs在复杂推理任务中的表现提供了新的视角,并促进了文本结构与语义之间关系的探索。
当前挑战
GRS-QA数据集在构建过程中面临多项挑战。首先,现有的大多数多跳问答数据集缺乏明确的推理结构,这限制了LLMs利用预定义推理路径的能力,迫使其仅依赖内部知识进行推理。其次,这些数据集混合了不同复杂度的问答对,未进行分类,使得难以在细粒度结构层面上研究LLMs的问答能力。此外,数据集中推理图类型的分布不均衡,某些复杂结构的样本较少,可能导致模型在处理复杂推理模式时表现不佳。最后,数据集涵盖多个领域,缺乏固定主题,增加了领域特定推理的难度。这些挑战要求在未来的研究中进一步优化数据集的结构和内容,以提升LLMs在复杂推理任务中的表现。
常用场景
经典使用场景
在自然语言处理领域,GRS-QA数据集的经典使用场景主要集中在多跳问答(M-QA)任务中。该数据集通过构建推理图,明确捕捉问答对之间的复杂推理路径,从而为大型语言模型(LLMs)提供了一个精细评估其推理能力的平台。研究人员利用GRS-QA数据集,可以深入分析LLMs在处理不同结构复杂度的问答任务时的表现,从而推动模型在复杂推理任务中的性能提升。
衍生相关工作
基于GRS-QA数据集,研究者们开展了一系列相关工作,进一步推动了多跳问答和推理图分析的研究。例如,有研究利用GRS-QA数据集开发了新的评估指标,如推理召回率和精确率,以更全面地评估LLMs的推理能力。此外,还有工作探讨了如何结合图神经网络(GNNs)和检索增强模型,以提升模型在处理复杂推理任务时的表现。这些衍生工作不仅丰富了GRS-QA数据集的应用场景,也为多跳问答领域的研究提供了新的思路和方法。
数据集最近研究
最新研究方向
在自然语言处理领域,多跳问答(M-QA)任务对模型的推理能力提出了严峻挑战。近年来,大型语言模型(LLMs)在多跳问答任务中表现出色,但其对推理结构的理解仍需深入研究。为此,GRS-QA数据集应运而生,该数据集通过引入显式的推理图结构,为LLMs的多跳问答能力提供了精细化的评估框架。研究者们利用GRS-QA数据集,探索了不同推理结构对LLMs性能的影响,发现模型在处理复杂推理路径时表现显著下降。这一发现不仅揭示了现有模型的局限性,也为未来开发更强大的推理模型提供了方向。此外,GRS-QA数据集的构建方法和分析结果为多跳问答任务的研究提供了新的视角,推动了该领域的前沿进展。
相关研究论文
- 1GRS-QA -- Graph Reasoning-Structured Question Answering Dataset加州大学圣克鲁兹分校 · 2024年
以上内容由遇见数据集搜集并总结生成


