RETA
收藏arXiv2021-11-23 更新2024-06-21 收录
下载链接:
https://www.reta-benchmark.org
下载链接
链接失效反馈官方服务:
资源简介:
RETA数据集是由浙江大学计算机科学与技术学院创建的,专注于视网膜血管树分析。该数据集包含81张图像,源自IDRiD数据集的第一个子集,并附有像素级别的血管掩模。创建过程中,采用了半自动化的粗到细工作流程进行血管像素的标注,并严格控制了标注者间的变异性和标注者内的变异性。数据集不仅包含二值血管掩模,还提供了动脉/静脉掩模、血管骨架、分支点、树和异常等详细标注。RETA数据集的应用领域广泛,包括自动血管分割算法的开发与评估,以及跨模态管状结构分割的研究,旨在解决视网膜血管分析中的通用性问题。
The RETA dataset was developed by the College of Computer Science and Technology, Zhejiang University, and focuses on retinal vascular tree analysis. It contains 81 images sourced from the first subset of the IDRiD dataset, paired with pixel-level vascular masks. During the dataset construction, a semi-automated coarse-to-fine workflow was utilized for annotating vascular pixels, with strict control over inter-annotator and intra-annotator variability. The dataset not only includes binary vascular masks but also provides detailed annotations such as artery/vein masks, vascular skeletons, bifurcation points, vascular trees, and abnormalities. The RETA dataset has broad application scenarios, including the development and evaluation of automated vascular segmentation algorithms, as well as research on cross-modal tubular structure segmentation, aiming to solve the generalizability challenges in retinal vascular analysis.
提供机构:
浙江大学计算机科学与技术学院
创建时间:
2021-11-23
搜集汇总
数据集介绍
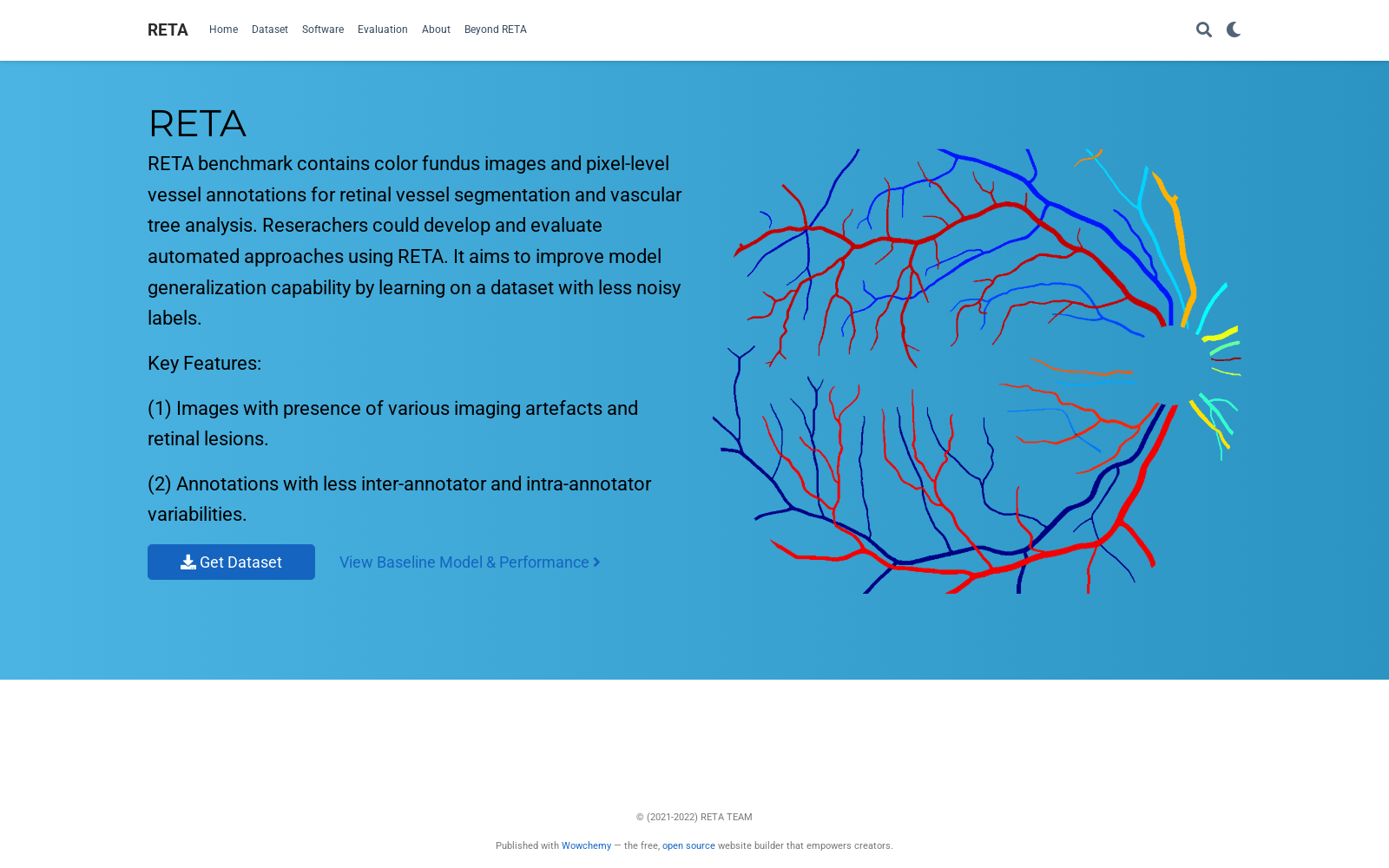
构建方式
在视网膜血管分析领域,构建高质量标注数据集对算法泛化能力至关重要。RETA数据集采用半自动化从粗到细的工作流程,首先利用预训练的VGAN模型生成初始血管分割结果,随后通过自主研发的CARL标注软件进行像素级手动校正。标注过程分为像素级、结构级和网络级三个阶段,通过多阶段标注和标签消歧策略有效控制标注者间与标注者内变异。最终通过模型预测与人工标注的交叉验证,实现噪声像素的识别与修正,确保标注结果的精确性与一致性。
使用方法
研究者可通过官方平台获取数据集,其中包含图像文件夹与MATLAB格式的标注文件。数据集支持血管分割算法的开发与评估,建议保持1024×1024原始分辨率以避免重采样导致的血管断裂问题。评估指标除传统像素级度量外,推荐采用对血管厚度不敏感的骨架相似性与拓扑相似性指数。针对视场边界伪影问题,附带的图像预处理代码可有效抑制背景干扰。数据集兼容CARL可视化工具,支持多尺度标注查验与质量评级,为跨模态管状结构分割研究提供可靠基准。
背景与挑战
背景概述
视网膜血管树分析作为早期检测糖尿病视网膜病变、高血压视网膜病变及中风等微血管与大血管疾病的非侵入性手段,其重要性在医学影像领域日益凸显。RETA基准数据集由浙江大学与阿尔伯塔大学的研究团队于2021年共同构建,旨在应对现有视网膜血管分割与树状结构分析中泛化能力不足的挑战。该数据集包含81幅源自IDRiD挑战赛的彩色眼底图像及其精细标注的血管掩码,不仅提供二进制血管分割标签,还涵盖了动静脉分类、血管骨架、分叉点及完整血管树等多层次注释。通过自主研发的计算机辅助视网膜标注软件与半自动化工作流程,RETA显著提升了标注的一致性与准确性,为血管分割算法的开发与评估、多任务视网膜图像分析及跨模态管状结构分割研究提供了高质量基准。
当前挑战
RETA数据集致力于解决视网膜血管树分析中的核心挑战:其一,在领域问题层面,现有血管分割模型在跨数据集评估中表现出泛化能力薄弱,尤其对训练集外私有图像的预测鲁棒性不足,导致后续动静脉树分离、拓扑特征量化等分析步骤仍需依赖人工校正;其二,在构建过程中,像素级血管标注面临标注者间与标注者内变异引入的噪声干扰,且微小血管与病变区域(如微动脉瘤、渗出物)的精细标注极为耗时,需通过多阶段标注策略与专用软件工具以控制标注质量。此外,血管交叉点、边界模糊区域及图像边缘部分血管的拓扑结构还原亦构成技术难点,需结合形态学处理与人工验证以确保标注的几何与拓扑准确性。
常用场景
经典使用场景
在视网膜图像分析领域,RETA数据集为血管分割算法的开发与评估提供了标准化基准。该数据集包含81幅带有精细标注的眼底图像,涵盖动脉/静脉分类、血管骨架、分叉点及树状结构等多层次注释。研究者通常利用这些高质量标注训练深度学习模型,特别是针对存在糖尿病性视网膜病变等复杂病灶的图像进行血管分割,以提升模型在病理条件下的泛化能力。数据集采用的半自动化标注流程有效控制了标注者间差异,为血管分割任务提供了可靠的黄金标准。
解决学术问题
RETA数据集主要解决了视网膜血管分析中标注质量不一致和泛化能力不足的学术难题。传统公共数据集常因标注噪声和边界模糊问题影响模型性能评估,而RETA通过多阶段标注策略和标签消歧技术,显著提升了血管标注的精确度与一致性。该数据集为血管拓扑结构分析、动脉/静脉分离算法验证提供了高质量基础,同时通过分形维度等临床指标验证了标注的生物学合理性,推动了视网膜血管量化分析方法的标准化进程。
实际应用
在临床医学实践中,RETA数据集支持开发自动化视网膜疾病筛查系统。基于该数据集训练的血管分割模型可应用于糖尿病视网膜病变、高血压视网膜病变等微血管疾病的早期检测。血管几何特征(如管径、弯曲度)和拓扑参数(如分叉密度)的精确测量,为心血管疾病风险预测提供了量化依据。此外,标注软件CARL的公开使医疗机构能够可视化血管结构,辅助医生进行术前规划和疗效评估,实现了计算机视觉技术与临床诊疗流程的有效融合。
数据集最近研究
最新研究方向
在视网膜血管分析领域,RETA基准数据集凭借其精细的动脉/静脉分割、血管骨架及拓扑结构标注,正推动着多任务学习与跨模态管状结构分割的前沿探索。当前研究热点聚焦于利用该数据集提升血管分割模型的泛化能力,尤其是在存在糖尿病病变的图像中,通过结合拓扑相似性指标与骨骼相似性度量,以更公平地评估分割性能。此外,RETA的高质量标注为血管几何与拓扑特征分析提供了可靠基础,助力于早期微血管疾病的生物标志物发现,如通过分形维度变化关联糖尿病性黄斑水肿的严重程度,彰显了其在临床辅助诊断与计算机视觉交叉研究中的深远意义。
相关研究论文
- 1The RETA Benchmark for Retinal Vascular Tree Analysis浙江大学计算机科学与技术学院 · 2021年
以上内容由遇见数据集搜集并总结生成


