QATD2k
收藏arXiv2025-05-23 更新2025-05-24 收录
下载链接:
https://huggingface.co/datasets/Eedi/Question-Anchored-Tutoring-Dialogues-2k
下载链接
链接失效反馈官方服务:
资源简介:
QATD2k是一个包含真实世界辅导对话的大规模开源数据集,旨在支持高质量教育对话数据的需求。该数据集包含4129个对话,每个对话都是学生在进行诊断性问题时与辅导老师之间的互动。数据集由Eedi公司收集,旨在为研究者和开发人员提供真实的在线辅导场景数据,以推动教育技术研究。QATD2k数据集通过PIIvot框架进行匿名化处理,确保学生和辅导老师的隐私安全。
QATD2k is a large-scale open-source dataset containing real-world tutorial dialogues, designed to support the demand for high-quality educational conversation data. It includes 4129 dialogues, each representing the interaction between a student and a tutor during diagnostic problem-solving sessions. Collected by Eedi, this dataset aims to provide researchers and developers with authentic online tutoring scenario data to advance educational technology research. The QATD2k dataset has been anonymized via the PIIvot framework to guarantee the privacy and security of both students and tutors.
提供机构:
Eedi
创建时间:
2025-05-23
原始信息汇总
数据集概述:Question-Anchored-Tutoring-Dialogues-2k
基本信息
- 名称:Question Anchored Tutoring Dialogues
- 语言:英语
- 标签:教育
- 许可协议:CC-BY-NC-4.0
- 数据规模:1K<n<10K
- 任务类别:文本生成
数据集详情
- 描述:包含来自Eedi数学辅导干预的对话,每个对话代表学生请求帮助时的聊天记录。
- 元数据:
- DQ-Question-Metadata:学生请求辅导的问题。
- Dialogue-Subjects:课程的主题和子主题。
- 创建者:Matthew Zent, Digory Smith, Simon Woodhead
- 资助方:Eedi
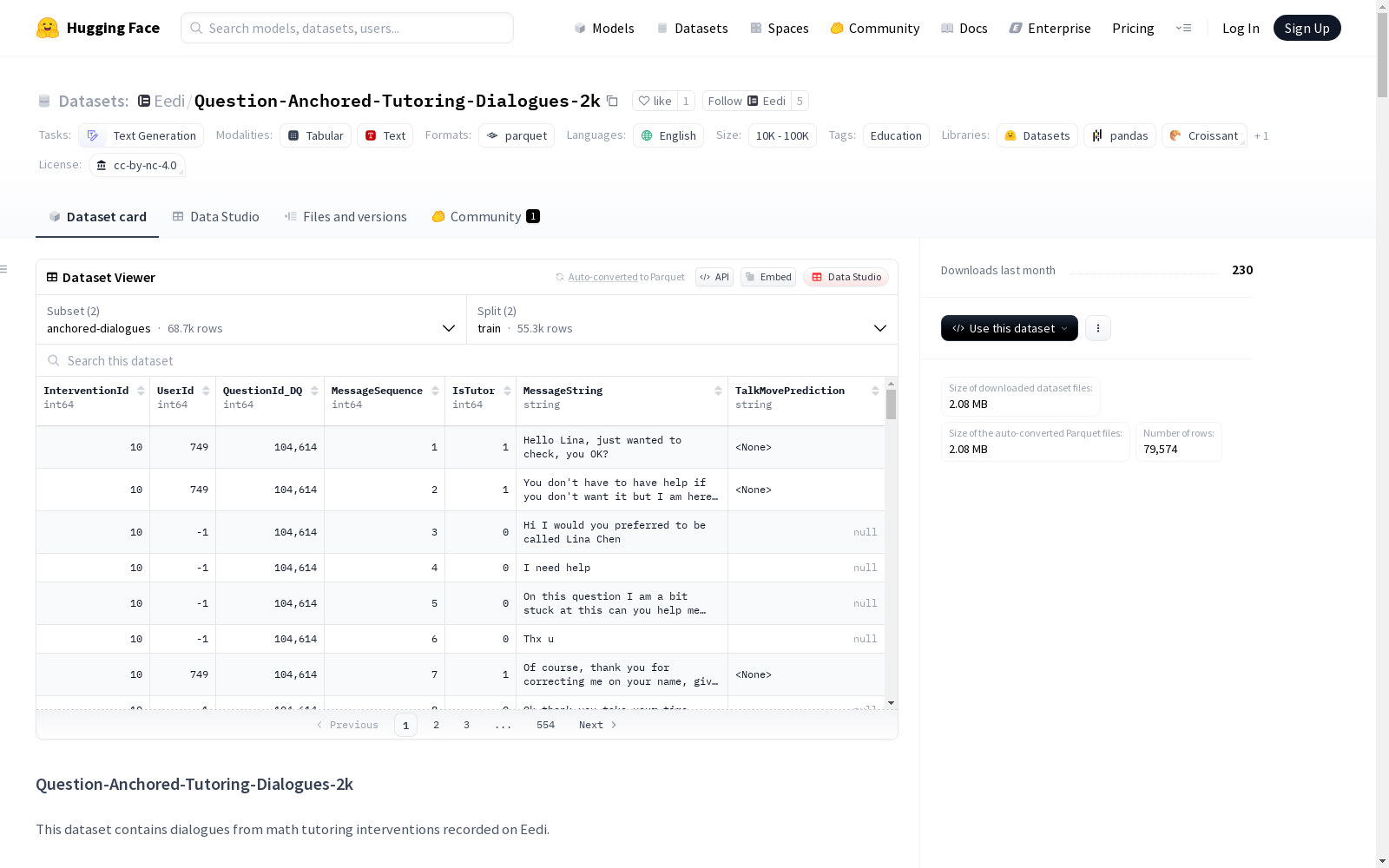
数据集结构
配置1:anchored-dialogues
- 特征:
- InterventionId:干预的唯一标识符。
- UserId:用户的唯一标识符。
- QuestionId_DQ:诊断问题的唯一标识符。
- MessageSequence:消息在对话中的序列号。
- IsTutor:消息是否来自导师。
- MessageString:消息内容。
- TalkMovePrediction:导师支持学生数学思维的标签。
- 数据量:
- 训练集:55,322条,4,674,549字节。
- 测试集:13,395条,1,138,842字节。
配置2:dq-question-metadata
- 特征:
- QuestionId_DQ:诊断问题的唯一标识符。
- InterventionId:干预的唯一标识符。
- MetaDataId:元数据的唯一标识符。
- Text:问题的提取文本。
- Sequence:文本的呈现顺序。
- MetaDataTagId:与标签列的一对一映射。
- Label:提取文本的标签。
- 数据量:
- 训练集:10,857条,1,129,952字节。
数据集来源
- 数据生产者:Eedi平台上的导师和学生。
- 学生统计:
- 唯一学生数:1,073
- 唯一导师数:25
- 唯一干预数:1,971
- 总消息数:68,717
使用场景
- 直接用途:用于非商业研究,改善学习成果。
- 范围外用途:识别个人或高风险决策。
数据集创建
- 数据收集:2021年11月至2025年2月。
- 处理步骤:
- 初始过滤:至少20条消息,学生和导师各至少7条。
- 内容审核:使用OpenAI模型筛选安全类别。
- 导师同意:仅包含25位同意研究的导师的对话。
- 降采样:保留2,000个对话。
- 手动审查:移除29个不安全或无教育价值的对话。
- 匿名化:使用PIIvot工具匿名化潜在PII。
注释
- Talk Moves:用于降采样的GPT分类模型标签。
- 潜在PII:使用PIIvot和人工注释匿名化。
偏见与风险
- 局限性:
- 主要针对英国学生。
- 导师可能同时管理多个学生。
- 学生对AI聊天机器人的怀疑。
- 学生隐私限制个体级详细信息。
引用
- 状态:待发表,联系Matthew.Zent@eedi.co.uk获取引用信息。
联系人
- 作者:Matthew Zent
- 邮箱:Matthew.Zent@eedi.co.uk
搜集汇总
数据集介绍
构建方式
QATD2k数据集的构建采用了PIIvot框架进行匿名化处理,该框架通过潜在PII标注任务简化了PII检测问题,并利用LLM生成上下文准确的替代内容以保持数据完整性。数据集筛选自一个覆盖19,000所学校的英国在线学习平台,包含学生与专家导师的对话,经过初始过滤和谈话策略降采样,最终形成1971个对话。
使用方法
该数据集适用于数学辅导对话建模、教学策略分析等研究场景。使用者可通过Hugging Face平台获取,需遵守CC-BY-NC-SA 4.0许可协议,仅限非商业研究用途。建议结合数据集提供的元数据(如诊断问题信息)和谈话策略标签进行分析,同时注意匿名化处理可能对某些研究任务造成的影响。
背景与挑战
背景概述
QATD2k数据集由Eedi团队于2025年发布,是当前最大的开源真实世界辅导对话数据集,专注于数学教育领域。该数据集由Matthew Zent等研究者构建,旨在支持高质量教育对话数据的需求,特别是在大规模在线数学辅导场景中。QATD2k包含1971个对话和46249个对话轮次,源自英国一个覆盖19000所学校的在线学习平台,其独特之处在于通过PIIvot匿名化框架处理敏感信息,同时保留了对话的教学价值。这一数据集的发布填补了真实教育场景数据稀缺的空白,为研究对话建模、教学策略分析和模型校准提供了重要资源,对推动教育技术尤其是数学辅导领域的发展具有显著意义。
当前挑战
QATD2k面临的核心挑战主要体现在两个方面:在领域问题层面,数学辅导对话涉及复杂的教学策略和学生认知过程,如何准确捕捉和标注这些教学互动(如谈话行为分类)是一大难题,特别是当对话涉及虚构情境时,教学策略的标注容易产生歧义;在构建过程层面,匿名化处理面临严峻挑战,包括平衡隐私保护与数据可用性、处理数学问题中的LaTeX格式元数据时命名实体识别性能下降、确保匿名化后的对话保持连贯性,以及从海量对话中筛选具有教学价值的样本时如何定义和量化'有效教学事件'。这些挑战需要通过创新的匿名化算法和严格的数据筛选流程来解决。
常用场景
经典使用场景
QATD2k数据集作为当前最大规模的开源真实世界辅导对话数据集,其经典使用场景主要集中在数学教育领域的研究中。该数据集通过记录学生与导师围绕诊断性问题展开的对话,为研究者提供了分析教学策略、对话建模和学习效果评估的丰富素材。特别是在探究高剂量在线辅导的有效性时,该数据集能够支持对辅导对话中教学行为的细粒度分析。
解决学术问题
该数据集有效解决了教育技术领域多个关键学术问题:首先突破了真实教育数据因隐私问题难以共享的瓶颈,通过PIIvot匿名化框架实现了敏感信息的安全处理;其次弥补了现有辅导对话数据集规模小、质量受限的缺陷,为研究真实教学场景中的对话动态提供了可靠数据基础;最重要的是支持了数学推理领域的研究,为分析LLM在数学辅导中的表现提供了基准数据。
实际应用
在实际应用层面,QATD2k数据集已被广泛应用于智能辅导系统的开发与优化。教育科技公司利用该数据集训练对话模型,提升系统识别学生误解的能力;研究人员通过分析对话模式,改进在线辅导的教学策略;此外,该数据集还支持开发隐私保护技术,为教育数据的合规使用提供了实践范例。
数据集最近研究
最新研究方向
QATD2k数据集作为当前最大规模的开源真实世界教学对话数据集,其最新研究聚焦于两大前沿方向:一是基于PIIvot轻量化框架的隐私保护技术创新,通过将PII检测重构为潜在标识标注任务并利用LLM生成语境化替代内容,在数学辅导领域实现了隐私保护与数据效用的平衡;二是该数据集推动的教育对话系统研究,特别是针对低信息量对话场景的实时响应策略优化,弥补了现有合成数据在消息长度和交互真实性方面的缺陷。相关研究正与LLM赋能的规模化教育干预、认知结果分析等热点领域深度融合,为构建符合教育伦理的智能辅导系统提供了关键数据支撑。
相关研究论文
- 1PIIvot: A Lightweight NLP Anonymization Framework for Question-Anchored Tutoring DialoguesEedi · 2025年
以上内容由遇见数据集搜集并总结生成


