BIFOLD-BigEarthNetv2-0/BigEarthNet.txt
收藏Hugging Face2026-04-01 更新2026-04-05 收录
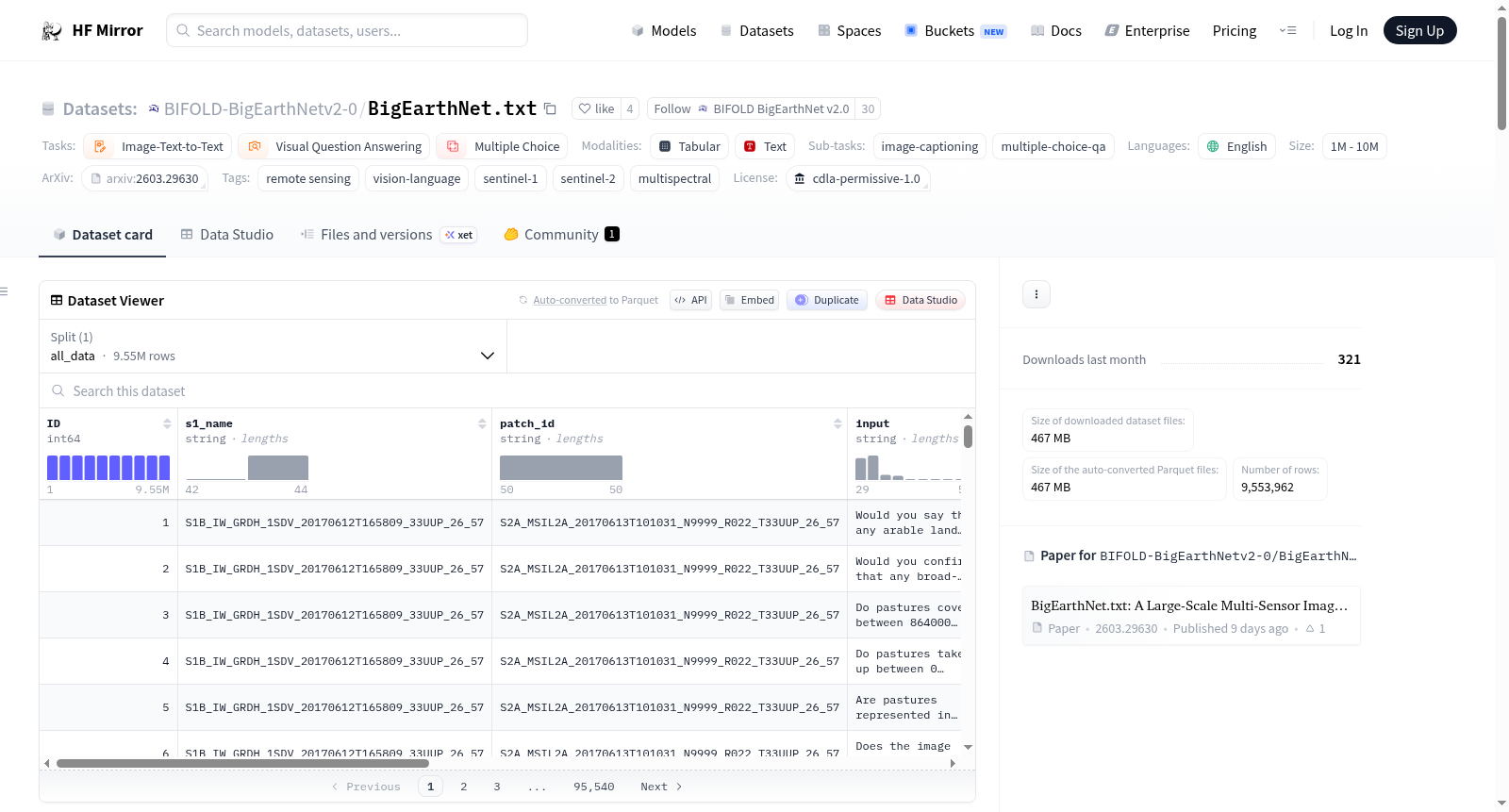
下载链接:
https://hf-mirror.com/datasets/BIFOLD-BigEarthNetv2-0/BigEarthNet.txt
下载链接
链接失效反馈官方服务:
资源简介:
---
license: cdla-permissive-1.0
task_categories:
- image-text-to-text
- visual-question-answering
- multiple-choice
task_ids:
- image-captioning
- multiple-choice-qa
language:
- en
pretty_name: BigEarthNet.txt
size_categories:
- 1M<n<10M
tags:
- remote sensing
- vision-language
- sentinel-1
- sentinel-2
- multispectral
configs:
- config_name: default
data_files:
- split: all_data
path: BigEarthNet.txt.parquet
default: true
---
<!-- CSS styling -->
<style>
.logo {
height: 50px;
}
table, td {
border: 1px solid black;
}
</style>
<!-- CSS styling End -->
<center>
<p style="display: flex; justify-content: space-between; width: 100%;">
<span style="display: flex; align-items: center; gap: 20px; margin-left: 20px">
<a href="https://bifold.berlin/">
<img src="./static/images/logos/BIFOLD_Logo_farbig.svg" alt="BIFOLD logo" class="logo">
</a>
<a href="https://www.tu.berlin/">
<img src="./static/images/logos/tu-berlin-logo-long-red.svg" alt="TU Berlin Logo" class="logo">
</a>
<a href="https://www.rsim.berlin/">
<img src="./static/images/logos/RSiM_Logo.png" alt="Remote Sensing Image Analysis Group Logo" class="logo">
</a>
</span>
<span style="display: flex; align-items: top; gap: 10px;">
<a href="https://txt.bigearth.net">
<img alt="Paper Website Badge" src="https://img.shields.io/badge/Paper-Website-%237FCCE0">
</a>
<a href="https://arxiv.org/abs/2603.29630">
<img alt="Paper arXiv Badge" src="https://img.shields.io/badge/Paper-arXiv-%23b31b1b">
</a>
<a href="https://cdla.dev/permissive-1-0/">
<img alt="Community Data License Agreement - Permissive - Version 1.0 License Badge" src="https://img.shields.io/badge/License-CDLA%201.0-blue.svg">
</a>
</span>
</p>
</center>
# BigEarthNet.txt: A Large-Scale Multi-Sensor Image-Text Dataset and Benchmark for Earth Observation
`BigEarthNet.txt` is a large-scale multi-sensor image–text dataset for Earth observation, designed to advance vision–language learning on remote sensing data. It comprises <b>464,044 co-registered Sentinel-1 (SAR) and Sentinel-2 (multispectral) image pairs</b> collected over Europe, paired with approximately <b>9.6 million textual annotations</b>. The textual annotations include geographically anchored captions describing land-use/land-cover (LULC) classes and their spatial relationships, diverse visual question answering (VQA) pairs (binary and multiple-choice), and referring expression instructions for LULC localization. In addition, the dataset provides a <b>manually verified benchmark split consisting of 1,082 image pairs with 15,029 textual annotations</b>, specifically designed for reliable evaluation of vision–language models on complex multi-sensor remote sensing tasks. For more details on the dataset, please see our [paper website](https://txt.bigearth.net).
<center>
<img src="./static/images/dataset.svg" width="80%" style="margin-bottom: 0">
<div style="font-size: 0.8em; color: gray; width: 80%; margin-top: 0">
The dataset supports 15 tasks (Presence, Area, Counting, Adjacency, Relative Position Country, Season, and Climate Zone, denoted as Pr, A, Cnt, Adj, RP, Loc, S, and Clt, respectively) across 4 broad categories.
</div>
</center>
<hr>
## Parquet File Structure
The `BigEarthNet.txt.parquet` file contains multiple attributes:
- `ID`: A unique identifier for each sample in the dataset.
- `s1_name`: The name of the Sentinel-1 patch from `BigEarthNet v2.0`.
- `patch_id`: The name of the Sentinel-2 patch from `BigEarthNet v2.0`.
- `input`: The instruction or question for the VLM.
- `output`: The reference answer.
- `type`: The broader task-type of the sample, i.e., `binary`, `mcq`, `captioning`, or `bounding box`.
- `category`: The more fine-grained task-type. See [here](https://huggingface.co/datasets/BIFOLD-BigEarthNetv2-0/BigEarthNet.txt/sql-console/KzrmYgF) for all type-category combinations.
- `split`: The associated split of the sample, i.e., `train`, `validation`, `test`, or `bench`.
- `latitude`: The latitude coordinates of the center of the image patch.
- `longitude`: The longitude coordinates of the center of the image patch.
- `country`: The acquisition country of the image patch. See [here](https://huggingface.co/datasets/BIFOLD-BigEarthNetv2-0/BigEarthNet.txt/sql-console/yn1wpPS) for all available values.
- `season`: The acquisition season of the image patch. See [here](https://huggingface.co/datasets/BIFOLD-BigEarthNetv2-0/BigEarthNet.txt/sql-console/m59YuRc) for all available values.
- `climate_zone`: The associated [Köppen-Geiger](https://www.nature.com/articles/s41597-023-02549-6) climate zone. See [here](https://huggingface.co/datasets/BIFOLD-BigEarthNetv2-0/BigEarthNet.txt/sql-console/SUU1DwA) for all available values.
<hr>
## How to use
We show the recommended way to prepare the image and text data to be jointly used in the form of a custom [PyTorch Dataset](https://docs.pytorch.org/tutorials/beginner/basics/data_tutorial.html) `BENTxTDataset` or [DataLoader](https://docs.pytorch.org/tutorials/beginner/basics/data_tutorial.html) `BENTxTDataModule` provided in [ben_txt_datamodule.py](ben_txt_datamodule.py).
#### 1. Download `BigEarthNet.txt.parquet`
Download using Git.
```bash
git clone https://huggingface.co/datasets/BIFOLD-BigEarthNetv2-0/BigEarthNet.txt
```
#### 2. Download the Image Data
Download the Sentinel-1 and Sentinel-2 image data from the [BigEarthNet v2.0 website](https://bigearth.net/).
#### 3. Preprocess the Image Data
Convert the Sentinel-1 and Sentinel-2 image data to `safetensors` stored in an `LMDB` database for higher throughput using [rico-hdl](https://github.com/rsim-tu-berlin/rico-hdl). Follow the installation instructions on [GitHub](https://github.com/rsim-tu-berlin/rico-hdl), then execute the following command to convert the Sentinel-1 and Sentinel-2 image data downloaded to `<S1_ROOT_DIR>` and `<S2_ROOT_DIR>`.
```bash
rico-hdl bigearthnet --bigearthnet-s1-dir <S1_ROOT_DIR> --bigearthnet-s2-dir <S2_ROOT_DIR> --target-dir Encoded-BigEarthNet
```
#### 4. Load the Data
Install [uv](https://docs.astral.sh/uv/getting-started/installation/). Install the required packages via uv using the command below. You can specify if you want to use the PyTorch CPU version or PyTorch with CUDA 12.6 by choosing `cpu` or `cu126` as the `<option>`.
```bash
uv sync --extra <option>
```
<hr>
The following examples show how to jointly load text samples from `BigEarthNet.txt` with the respective image data from `BigEarthNet v2.0`.
After executing the suggested steps above, you should be able to run the following [file from this repository](https://huggingface.co/datasets/BIFOLD-BigEarthNetv2-0/BigEarthNet.txt/blob/main/example_data_loading.py):
```bash
uv run example_data_loading.py
```
or load the data manually using the [provided datamodule](https://huggingface.co/datasets/BIFOLD-BigEarthNetv2-0/BigEarthNet.txt/blob/main/ben_txt_datamodule.py) as shown in the following two examples:
This example shows how to load the Red (B04), Green (B03), and Blue (B02) band from the Sentinel-2 image data using the `BENTxTDataset` Datasets class. More details about the custom Dataset are provided in [ben_txt_datamodule.py](ben_txt_datamodule.py).
```python
from ben_txt_datamodule import BENTxTDataset
ds_rgb = BENTxTDataset(
lmdb_file = "Encoded-BigEarthNet/",
metadata_file = "BigEarthNet.txt.parquet",
bands = ("B04", "B03", "B02"),
img_size = 120
)
sample = ds_rgb[0]
print(f"RGB input image: {sample['image_input'].shape}")
print(f"Text input: {sample['text_input']}")
print(f"Reference output: {sample['reference_output']}")
```
This example shows how to load the 10m and 20m spatial resolution bands from Sentinel-1 and Sentinel-2 using the `BENTxTDataModule` Lightning DataModule class. In this example we apply multiple metadata filters on `BigEarthNet.txt`, more details about the custom DataModule are provided in [ben_txt_datamodule.py](ben_txt_datamodule.py).
```python
from ben_txt_datamodule import BENTxTDataModule
# Lightning DataModule example using the 10m and 20m spatial resolution bands from Sentinel-1 and Sentinel-2 and multiple metadata filters.
# The datamodule will create 4 dataloaders: train, val, test, and bench.
dm = BENTxTDataModule(
image_lmdb_file = "Encoded-BigEarthNet/",
metadata_file = "BigEarthNet.txt.parquet",
bands = 'S1S2-10m20m',
img_size = 120,
batch_size = 1,
num_workers_dataloader = 0,
types = ['mcq'],
categories = ['climate zone'],
countries = ['Portugal', 'Finland'],
seasons = ['Summer'],
climate_zones = None,
point_token = ['<point>', '</point>'],
ref_token = ['<ref>', '</ref>']
)
dm.setup()
train_dl = dm.train_dataloader()
for batch in train_dl:
print(f"Batch image input shape: {batch['image_input'].shape}")
print(f"First batch sample text input: {batch['text_input'][0]}")
print(f"First batch sample text reference output: {batch['reference_output']}")
break
```
<hr>
### Citation
If you use the `BigEarthNet.txt` dataset, please cite:
```
J. Herzog, M. Adler, L. Hackel, Y. Shu, A. Zavras, I. Papoutsis, P. Rota, B. Demir,
"BigEarthNet.txt: A Large-Scale Multi-Sensor Image-Text Dataset and Benchmark for Earth Observation",
Arxiv Preprint arXiv:2603.29630, 2026.
```
```bibtex
@article{Herzog2026BigEarthNetTXT,
title={BigEarthNet.txt: A Large-Scale Multi-Sensor Image-Text Dataset and Benchmark for Earth Observation},
author={Johann-Ludwig Herzog and Mathis Jürgen Adler and Leonard Hackel and Yan Shu and Angelos Zavras and Ioannis Papoutsis and Paolo Rota and Begüm Demir},
journal={Arxiv Preprint arXiv:2603.29630},
year={2026},
}
```
提供机构:
BIFOLD-BigEarthNetv2-0
搜集汇总
数据集介绍
构建方式
BigEarthNet.txt 数据集构建于欧洲区域,通过整合哨兵一号合成孔径雷达与哨兵二号多光谱影像,实现了大规模多传感器遥感数据的对齐。其构建过程涉及从BigEarthNet v2.0中提取约46.4万对经过地理配准的图像,并在此基础上生成了近960万条文本注释,涵盖地理锚定描述、视觉问答及指代表达等多种任务类型。为确保评估的可靠性,数据集还专门划分出一个包含1082对图像和15029条注释的手动验证基准子集,为复杂多传感器遥感任务提供了坚实的评估基础。
使用方法
使用BigEarthNet.txt数据集需遵循多步骤流程,首先需通过Git克隆获取文本注释的Parquet文件,随后从BigEarthNet v2.0官网下载对应的哨兵一号与二号原始影像数据。为提升数据读取效率,建议利用rico-hdl工具将影像转换为safetensors格式并存储于LMDB数据库中。用户可通过提供的PyTorch Dataset或Lightning DataModule类加载数据,支持灵活选择光谱波段、应用元数据过滤及配置数据加载参数,从而适配不同的视觉-语言模型训练与评估需求。
背景与挑战
背景概述
BigEarthNet.txt数据集由柏林工业大学、BIFOLD及遥感图像分析组等机构于2026年联合构建,旨在推动地球观测领域的视觉-语言学习研究。该数据集整合了覆盖欧洲区域的464,044对Sentinel-1合成孔径雷达与Sentinel-2多光谱影像,并配以约960万条文本标注,涵盖地理锚定描述、视觉问答及指代表达等多种任务。其核心研究问题聚焦于如何利用多模态数据提升对土地利用与土地覆盖的自动化理解与分析能力,为遥感影像的智能解译提供了大规模、高质量的基础资源,显著促进了遥感与人工智能的交叉学科发展。
当前挑战
该数据集致力于解决地球观测中多传感器影像与自然语言关联的复杂问题,其挑战在于如何精准建模遥感影像中的空间语义关系,并支持多样化的下游任务如目标定位与场景问答。在构建过程中,研究人员面临多源数据配准、大规模标注质量控制以及跨模态对齐等难题,需协调Sentinel-1与Sentinel-2的数据特性差异,并确保文本注释的地理一致性与任务覆盖的完备性。
常用场景
经典使用场景
在遥感与人工智能交叉领域,BigEarthNet.txt数据集为多模态学习提供了关键支撑。其经典应用场景集中于训练和评估视觉-语言模型,以处理来自Sentinel-1和Sentinel-2卫星的多传感器遥感图像与文本注释的联合理解。研究者利用该数据集进行图像描述生成、视觉问答及土地覆盖分类等任务,通过模型学习从多光谱与合成孔径雷达图像中提取特征,并与描述土地覆盖类型、空间关系及地理属性的文本进行对齐,从而推动遥感图像自动解译技术的发展。
解决学术问题
该数据集有效应对了遥感领域长期存在的多模态数据融合与语义理解挑战。它通过提供大规模、高质量的多传感器图像-文本对,解决了遥感视觉-语言模型训练数据稀缺的问题,支持对复杂土地覆盖类别及其空间关系的细粒度建模。其标注体系涵盖十五种任务类型,促进了模型在存在性判断、面积估算、相对位置推理等多维度性能的评估,为遥感图像理解提供了统一的基准,显著提升了该领域研究的可复现性与可比性。
实际应用
在实际应用中,BigEarthNet.txt数据集为环境监测、精准农业和城市规划等提供了技术基础。基于该数据集训练的模型能够自动化分析卫星影像,识别作物类型、监测森林变化或评估城市扩张,辅助决策者进行资源管理和灾害评估。其包含的地理位置、季节与气候带元数据,使得模型能够结合时空上下文进行更精准的分析,将先进的视觉-语言学习能力转化为可服务于可持续发展目标的具体工具。
数据集最近研究
最新研究方向
在遥感与人工智能交叉领域,BigEarthNet.txt数据集正推动多模态学习的前沿探索。其整合了Sentinel-1合成孔径雷达与Sentinel-2多光谱影像,并配以近千万条文本标注,为地理空间视觉语言模型提供了前所未有的训练资源。当前研究聚焦于利用该数据集开发能够理解复杂地表覆盖关系、执行视觉问答及目标定位的先进模型,以应对气候变化监测、精准农业和城市动态分析等全球性挑战。这一大规模多传感器标注基准的建立,不仅加速了地球观测领域多任务学习的进展,也为实现可解释、可泛化的地理空间人工智能系统奠定了关键基础。
以上内容由遇见数据集搜集并总结生成


