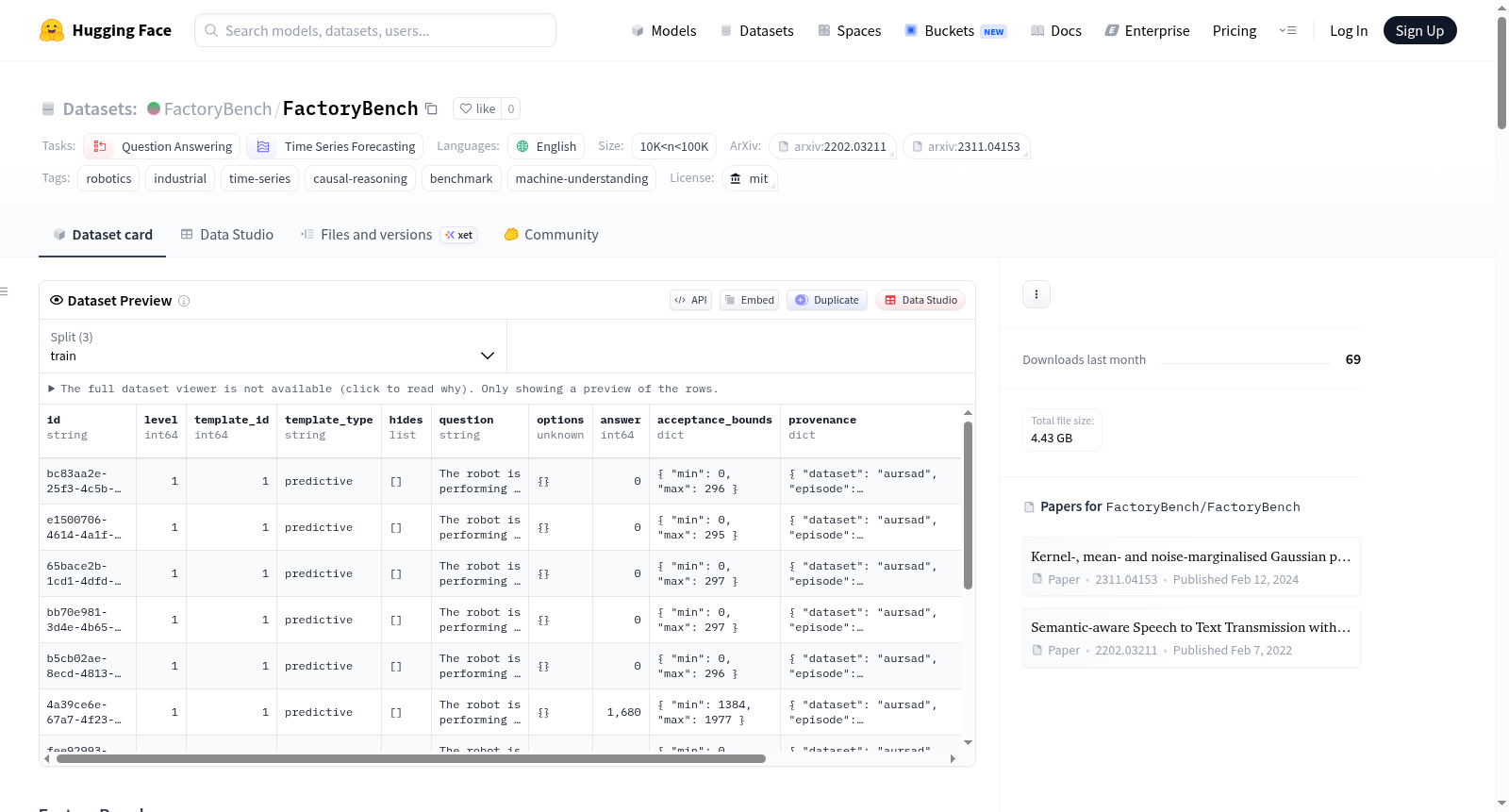
FactoryBench
收藏FactoryBench 数据集概述
FactoryBench 是一个用于评估机器行为推理能力的基准测试数据集,主要针对时间序列模型和大语言模型在工业机器人遥测数据上的表现。
核心特点
- 总规模:包含 70,918个问答对,分布在训练集、验证集和测试集中。
- 问答层级:基于 Pearl 因果层次模型的四个层级组织:
- L1 — 状态:从原始信号中识别运行状态
- L2 — 干预:预测干预措施的效果
- L3 — 反事实:推理替代历史情景
- L4 — 决策:工程决策(故障排查与优化)
- 答案格式:五种格式,包括单选题、多选题、排序、张量/数值、自由文本(由 LLM 投票协议评判)。
数据来源
数据基于 FactoryWave 数据集构建,这是一个密集的多变量遥测数据集,包含:
- UR3 协作机器人(125 Hz 采样)
- KUKA KR10 工业机械臂(83 Hz 采样)
- AURSAD 和 voraus-AD 开源数据集
系统性地注入了 27种原子故障机制,涵盖拾取-放置、拧螺丝和销孔装配任务。
仓库结构
FactoryBench/ ├── factorybench_qa/ # 问答对 │ ├── level_1/{train,validation,test}.jsonl │ ├── level_2/{train,validation,test}.jsonl │ ├── level_3/{train,validation,test}.jsonl │ └── level_4/{train,validation,test}.jsonl ├── knowledge_graph/ # 组合知识图谱 │ ├── knowledge_graph.json │ └── SCHEMA.md └── factorywave/ # 底层遥测数据与元数据 ├── episodes.parquet # 9,728个episode元数据 ├── flow.parquet # 任务流程定义 ├── kuka_signals.parquet # KUKA KR10信号(约83 Hz,1,428 episodes) ├── ur_signals.parquet # UR3信号(约125 Hz,3,076 episodes) ├── ur_signals_10hz.parquet # UR3信号(10 Hz,3,984 episodes) └── ur_screwdriver_signals.parquet # UR3螺丝刀子集(约125 Hz,1,240 episodes)
问答对数量统计
| 层级 | 训练集 | 验证集 | 测试集 | 总计 |
|---|---|---|---|---|
| L1 | 12,674 | 1,338 | 1,309 | 15,321 |
| L2 | 33,311 | 3,428 | 3,487 | 40,226 |
| L3 | 2,353 | 265 | 321 | 2,939 |
| L4 | 9,949 | 1,251 | 1,232 | 12,432 |
| 总计 | 58,287 | 6,282 | 6,349 | 70,918 |
问答对字段说明
每个问答对包含以下字段:
id:唯一标识符level:因果层级(1-4)template_id:问题模板IDtemplate_type:答案格式类型hides:向模型隐藏的通道/字段question:自然语言问题options:答案选项(仅限选择题/排序模板)answer:真实答案root_cause:潜在故障/原因(仅L4)acceptance_bounds:数值答案的容差范围provenance:来源信息context:暴露给模型的时间序列和元数据上下文
预期用途与限制
预期用途:评估LLM和时间序列模型在结构化工业问答推理任务(状态、干预、反事实、决策)上的表现。
局限性:
- 领域特定,局限于工厂和工业机器人场景
- 故障为原子化,来自27种物理注入机制的封闭目录
- 层级2和层级3之间存在规模不平衡
不适用场景:不适用于安全关键、医疗、法律或金融决策系统。
许可证
采用 MIT 许可证。