WEBEmo
收藏arXiv2018-08-07 更新2024-06-21 收录
下载链接:
https://rpand002.github.io/emotion.html
下载链接
链接失效反馈官方服务:
资源简介:
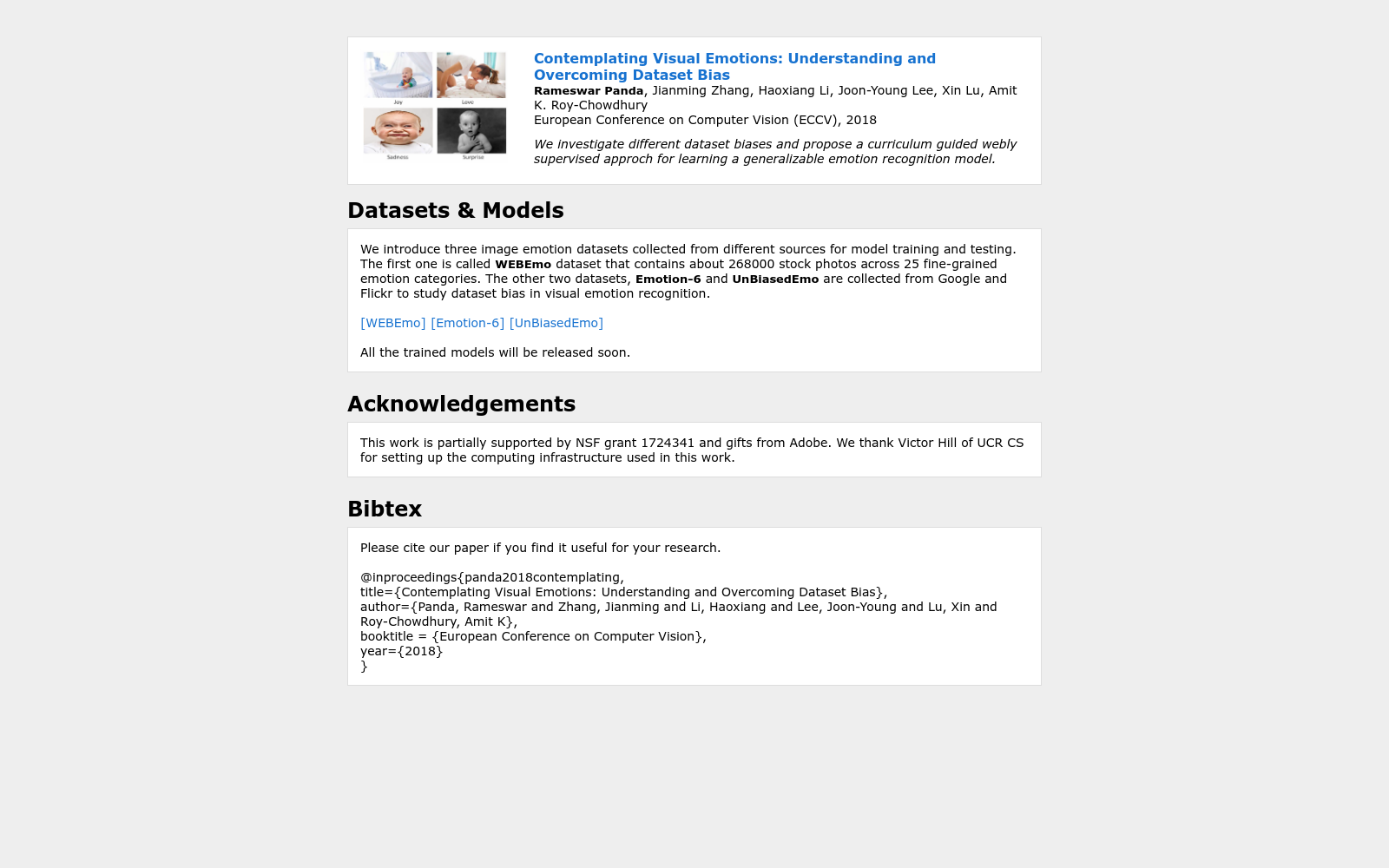
WEBEmo数据集是由加州大学河滨分校电气与计算机工程系的研究团队创建,包含约268,000张高质量的库存照片,覆盖25个细粒度的情感类别。该数据集通过使用一个库存网站检索网络图像,并利用这些图像进行无额外人工标注的学习。创建过程中,研究团队利用了心理学中的情感层次模型来指导学习,确保数据集的多样性和广泛性。WEBEmo数据集主要应用于视觉情感分析领域,旨在解决现有情感识别数据集中的偏差问题,提高模型的泛化能力。
The WEBEmo dataset was developed by a research team from the Department of Electrical and Computer Engineering at the University of California, Riverside. It contains approximately 268,000 high-quality stock photos spanning 25 fine-grained emotion categories. This dataset retrieves web images from a stock photo website and leverages these images for learning without additional manual annotations. During its development, the research team adopted the hierarchical emotion model in psychology to guide the learning process, ensuring the diversity and broad coverage of the dataset. The WEBEmo dataset is mainly applied in the field of visual emotion analysis, aiming to address the bias issues in existing emotion recognition datasets and improve the generalization ability of models.
提供机构:
加州大学河滨分校电气与计算机工程系
创建时间:
2018-08-07
搜集汇总
数据集介绍
构建方式
在视觉情感识别领域,WEBEmo数据集的构建采用了网络监督学习策略,以应对传统数据集存在的显著偏差问题。该数据集通过从专业图库网站检索图像,利用Parrott情感层次模型中的关键词进行查询,收集了约268,000张高质量图像,覆盖25种细粒度情感类别。构建过程中,研究者避免了人工标注,直接利用查询关键词作为弱标签,并通过去重和筛选非英语标签等步骤确保数据质量,从而实现了大规模、多样化的情感图像覆盖。
特点
WEBEmo数据集的核心特点在于其规模宏大且情感层次丰富,包含从基本正负情感到六种次级情感,再到25种细粒度情感的三级结构。这一设计基于心理学中的情感轮模型,增强了模型的解释性和学习能力。数据集中图像视觉概念多样,有效减少了传统数据集中常见的正负集偏差,例如通过涵盖广泛场景和对象,避免了情感与特定视觉元素的强关联,从而提升了模型的泛化性能。
使用方法
使用WEBEmo数据集时,研究者可采用课程引导训练策略,逐步从简单到复杂的情感类别进行模型学习。具体而言,首先在基本正负情感级别上微调预训练网络,随后过渡到六种次级情感,最终学习25种细粒度情感。这种方法通过顺序注入信息,帮助模型在早期捕获粗粒度特征,后期学习细粒度细节,有效应对了情感识别中的歧义性和网络数据的标签噪声。训练后的模型可直接用于图像情感分类,或通过特征提取支持视频情感分析、情感摘要等下游任务。
背景与挑战
背景概述
视觉情感识别作为计算机视觉领域的新兴研究方向,旨在通过算法解析图像所传达的情感内涵。2018年,由加州大学河滨分校与Adobe研究院联合发布的WEBEmo数据集,标志着该领域在数据规模与质量上的重要突破。该数据集基于Parrott的情感层次理论,通过从图库网站大规模爬取约26.8万张高质量图像,构建了涵盖25种细粒度情感类别的资源库,其核心研究问题聚焦于克服传统情感数据集中存在的显著偏差,以提升模型的泛化能力。WEBEmo的推出不仅为视觉情感分析提供了前所未有的数据支持,更通过课程引导的弱监督学习策略,推动了情感识别模型从依赖有限标注数据向利用网络弱标签数据的重要范式转变。
当前挑战
视觉情感识别领域面临的核心挑战在于情感本身的主观性与复杂性,导致模型难以从有限且带有偏差的数据中学习到普适性特征。具体而言,现有数据集的构建常受限于正负样本偏差,例如特定物体或场景与情感类别的强关联,致使模型过度依赖表面视觉线索而忽视情感本质。此外,数据收集过程中,人工标注成本高昂且难以覆盖多样化的情感概念,进一步加剧了数据偏差问题。WEBEmo数据集的构建虽通过大规模网络数据缓解了部分偏差,但仍需应对弱标签噪声、细粒度情感歧义性以及跨域泛化能力不足等挑战,这些因素共同制约着情感识别模型在实际应用中的鲁棒性与准确性。
常用场景
经典使用场景
在视觉情感识别领域,WEBEmo数据集常被用于训练和评估能够从自然图像中理解复杂情感的深度学习模型。其核心应用场景在于解决传统小规模情感数据集因视觉概念单一而导致的模型泛化能力不足问题。通过提供海量且多样化的网络图像,该数据集使研究者能够构建更鲁棒的情感识别系统,特别是在跨域情感概念迁移和细粒度情感分类任务中展现出显著优势。
解决学术问题
WEBEmo数据集主要解决了视觉情感识别中因数据集偏差而引发的模型过拟合与泛化能力弱化问题。传统数据集往往因规模有限和标注范式单一,导致模型学习到的是数据集的特定模式而非普适的情感语义。该数据集通过引入大规模网络监督学习,有效缓解了正负样本集的偏差,为构建不受特定视觉概念束缚的情感识别模型提供了数据基础,推动了领域内对数据集偏差问题的系统性反思与方法论革新。
衍生相关工作
围绕WEBEmo数据集衍生的经典工作主要集中在课程引导的弱监督学习框架及其扩展应用上。研究者受其启发,进一步探索了基于情感层次结构的渐进式学习策略,以应对细粒度情感分类中的标签噪声问题。同时,该数据集也促进了跨数据集泛化评估协议的形成,催生了一系列针对情感识别中偏差检测与缓解方法的研究。这些工作共同推动了视觉情感分析从依赖小规模标注数据向利用大规模网络数据范式的转变。
以上内容由遇见数据集搜集并总结生成


