QAMPARI
收藏arXiv2023-05-29 更新2024-06-21 收录
下载链接:
https://samsam3232.github.io/qampari/
下载链接
链接失效反馈官方服务:
资源简介:
QAMPARI是一个针对开放领域问答(ODQA)的基准数据集,专注于处理多答案问题。该数据集由特拉维夫大学计算机科学学院创建,包含61,911个训练示例,旨在评估模型处理广泛问题类型的能力,包括单答案和多答案问题。QAMPARI通过从维基百科知识图谱和表格中生成问题,自动匹配答案与支持证据,并通过众包进行问题重述和答案验证。数据集的应用领域包括开发能够处理多种问题类型,尤其是多答案问题的问答系统。
QAMPARI is a benchmark dataset for open-domain question answering (ODQA) that focuses on multi-answer questions. Created by the School of Computer Science at Tel Aviv University, this dataset contains 61,911 training examples, and is designed to evaluate a model's capability to handle a wide range of question types, including both single-answer and multi-answer questions. QAMPARI generates questions from Wikipedia knowledge graphs and tables, automatically matches answers to their supporting evidence, and conducts question paraphrasing and answer validation via crowdsourcing. The dataset is targeted at developing question answering systems capable of handling diverse question types, especially multi-answer questions.
提供机构:
特拉维夫大学计算机科学学院
创建时间:
2022-05-25
搜集汇总
数据集介绍
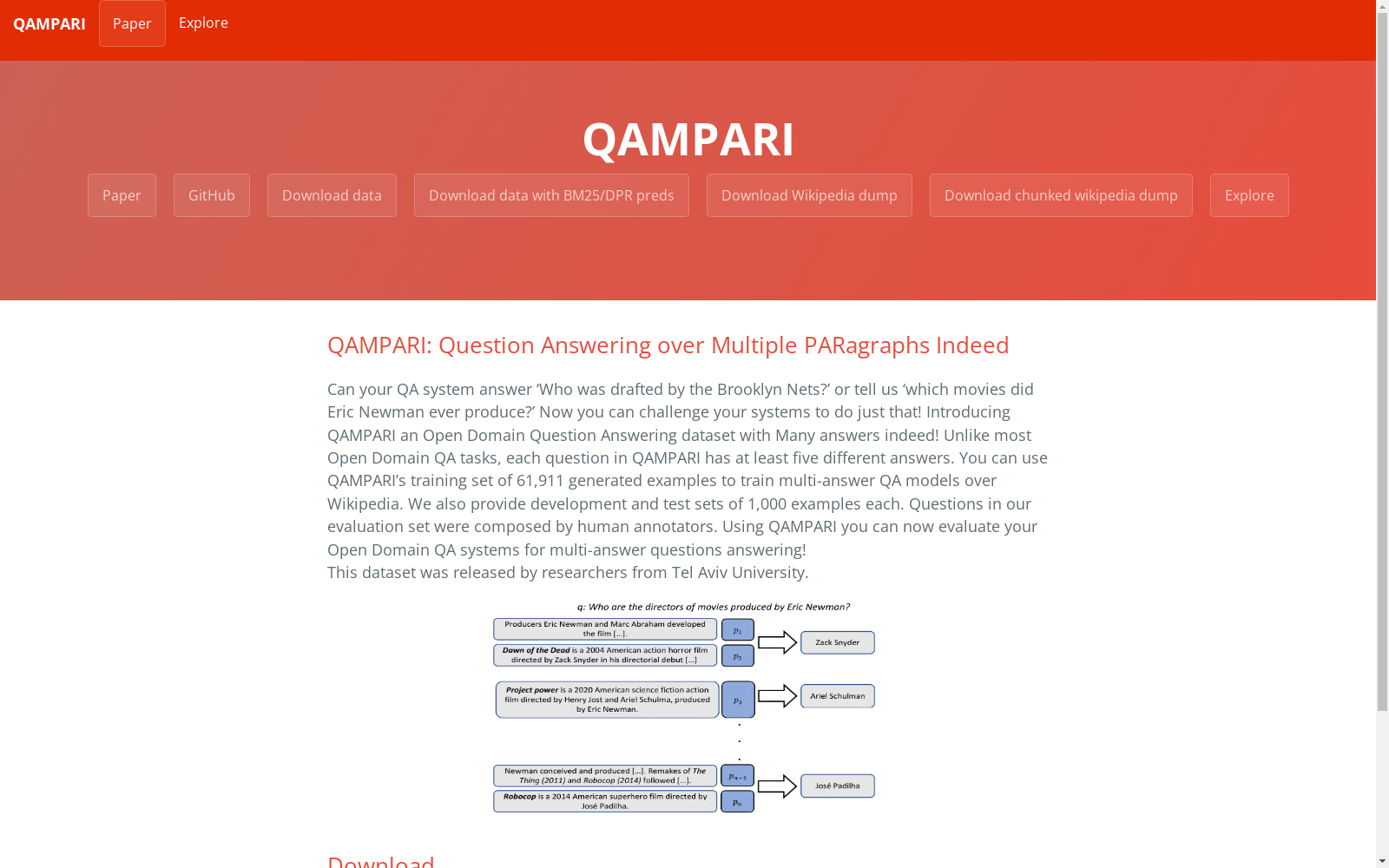
构建方式
在开放域问答研究领域,传统基准多聚焦于答案集中于单一文本片段的问题。为应对多答案、跨段落问题的挑战,QAMPARI数据集通过半自动化流程构建。其构建过程始于从维基数据知识图谱和维基百科表格中提取实体与关系,生成具有至少五个答案的初始查询。随后,利用远程监督方法,通过自然语言推理模型自动将答案与维基百科中的证据段落对齐,确保每个答案均有文本支撑。最后,通过众包平台对答案进行人工验证,并将模板生成的伪语言问题改写为自然语言表达,形成包含简单、交集与复合三种问题类型的完整数据集。
特点
QAMPARI数据集的核心特征在于其专注于多答案、跨段落的开放域问答场景。该数据集的问题平均拥有13个答案,且答案广泛分布于多个维基百科段落中,这要求模型具备从大规模语料中检索并整合分散信息的能力。数据集涵盖了从维基数据和维基百科表格衍生的多样化问题类型,包括简单查询、关系交集及关系复合问题,显著提升了问题的复杂性与多样性。此外,数据集采用基于关系的划分策略,确保训练集与测试集在关系层面上无重叠,有效防止模型通过记忆文本模式而非真正理解来回答问题,从而增强了评估的严谨性。
使用方法
QAMPARI数据集主要用于评估开放域问答模型处理多答案问题的能力。典型的使用方法遵循“检索-阅读”范式:首先,利用检索模型(如BM25或密集检索器DPR)从维基百科语料中检索出与问题相关的候选段落;随后,阅读模型(如独立解码的PIG或融合解码的FiD)基于检索到的段落生成答案列表。评估时,通过比较模型预测的答案集合与标注的黄金答案集合,计算精确率、召回率及F1分数等指标。研究亦可探索闭卷问答或零样本设置下的模型表现。该数据集鼓励与单答案基准(如Natural Questions)联合评估,以全面衡量模型应对不同问题类型的泛化能力。
背景与挑战
背景概述
在开放域问答研究领域,传统基准如Natural Questions和TriviaQA主要聚焦于答案集中于单一文本段落的简单问题。然而,现实世界中存在大量答案分散于多个段落的问题,例如“布鲁克林篮网队选中了哪些球员?”,这类问题要求模型具备从大规模语料库中检索并整合多源信息的能力。为填补这一研究空白,以色列特拉维夫大学的研究团队于2023年推出了QAMPARI数据集,该数据集专门针对多答案开放域问答任务设计,通过结合维基数据知识图谱与维基百科表格,半自动生成了包含至少五个答案的问题实例,平均每个问题对应13个答案,旨在推动模型处理复杂多答案问题的能力发展。
当前挑战
QAMPARI数据集所应对的核心领域挑战在于开放域问答中多答案问题的处理,这要求模型不仅能够从海量文档中精准检索出所有相关段落,还需具备跨段落推理与答案整合的能力。在构建过程中,研究团队面临两大主要挑战:一是答案验证的复杂性,需确保每个答案都能在维基百科文本中找到证据支持,这涉及使用自然语言推理模型进行远程监督对齐,并需应对知识图谱与文本对齐时产生的噪声问题;二是数据分割的设计难题,为避免模型记忆特定关系模式,团队采用了基于关系的数据分割策略,这增加了模型泛化能力的要求,同时也使得封闭书模型在该数据集上表现显著下降。
常用场景
经典使用场景
在开放域问答研究领域,QAMPARI数据集被广泛用于评估模型处理多答案复杂问题的能力。其典型应用场景是测试检索-阅读范式下的系统性能,要求模型从大规模文档库中检索分散于多个段落的大量实体答案。例如,针对“布鲁克林篮网队选中了哪些球员?”这类问题,模型需跨越不同文本片段整合信息,生成完整的答案列表。该场景深刻揭示了传统单答案问答系统在应对现实世界复杂查询时的局限性。
实际应用
在实际应用层面,QAMPARI所针对的多答案问答能力对智能搜索引擎、知识图谱补全和学术文献分析具有重要价值。例如在医疗领域,查询“对皮肤癌有效的药物有哪些?”需要系统从分散的临床研究报告、药品数据库和学术论文中提取完整列表;在商业分析中,追踪某公司所有子公司或专利成果同样需要跨文档信息聚合。该数据集训练的系统能够支持更全面的决策分析,为专业领域的信息整合提供技术基础。
衍生相关工作
QAMPARI的发布催生了多答案问答方向的系列研究。基于其构建的检索增强生成模型(如PIG与FiD架构对比研究)揭示了独立段落处理与联合推理的效能差异。同期工作RoMQA同样采用Wikidata构建多答案基准,但聚焦于维基百科子集对齐。后续研究进一步探索了基于大型语言模型的零样本多答案生成能力,以及针对罕见实体的稠密检索优化。这些工作共同推动了开放域问答系统向多粒度、多维度信息获取方向发展。
以上内容由遇见数据集搜集并总结生成


