mmlongbench-text-only
收藏Hugging Face2026-05-09 更新2026-05-10 收录
下载链接:
https://huggingface.co/datasets/luoojason/mmlongbench-text-only
下载链接
链接失效反馈官方服务:
资源简介:
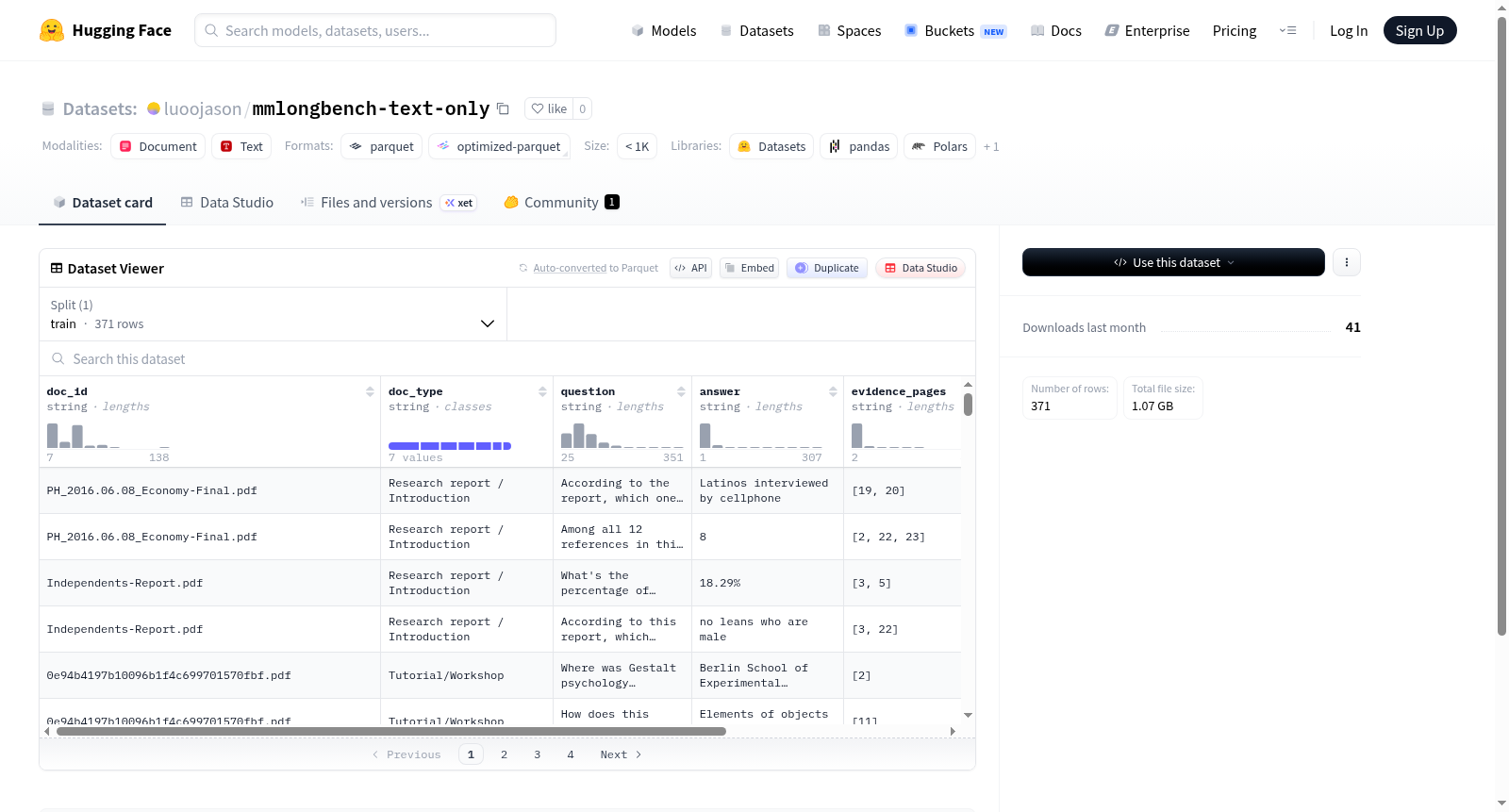
该数据集包含371个训练样本,总大小为81,114字节。每个样本包含7个字段:文档ID(doc_id)、文档类型(doc_type)、问题(question)、答案(answer)、证据页(evidence_pages)、证据来源(evidence_sources)和答案格式(answer_format)。数据集采用单一训练集划分,未提供验证或测试集。从字段命名推断,该数据集可能适用于问答系统或信息检索任务,特别是需要证据支持答案的场景,但具体用途需结合实际数据内容进一步确认。
创建时间:
2026-05-02
原始信息汇总
根据您提供的数据集详情页面 README 文件内容,以下是该数据集的概述:
数据集概述
数据集名称:mmlongbench-text-only
数据集地址:https://huggingface.co/datasets/luoojason/mmlongbench-text-only
数据集特征
该数据集包含以下字段:
- doc_id:文档标识符(字符串类型)
- doc_type:文档类型(字符串类型)
- question:问题内容(字符串类型)
- answer:答案内容(字符串类型)
- evidence_pages:证据所在页面(字符串类型)
- evidence_sources:证据来源(字符串类型)
- answer_format:答案格式(字符串类型)
数据集划分
- 训练集(train):包含 371 个样本,占用 81,114 字节。
数据集大小
- 下载大小:37,250 字节
- 数据集总大小:81,114 字节
配置信息
- 默认配置(default):数据文件路径为
data/train-*,对应训练集分割。
搜集汇总
数据集介绍
构建方式
MMLongBench-Text-Only数据集专注于纯文本场景下的长文本理解与推理任务,其构建过程强调真实性与多样性。数据来源于多种文本领域,涵盖学术文献、技术报告、法律文档及新闻文章等,以模拟复杂的长文本应用环境。每条样本包含文档标识符、文档类型、问题、答案、证据页面与证据来源字段,确保任务可追溯且具备可解释性。采用人工与半自动相结合的方式生成问答对,其中证据页面明确标记关键信息所在位置,使得模型在生成答案时需依赖对全文的长程依赖与精确定位能力。数据集共包含371条训练样本,规模虽小但质量较高,旨在作为长文本理解的基准测试而非大规模预训练语料。
使用方法
研究者可通过HuggingFace Datasets库轻松加载该数据集,默认配置为'default',仅包含训练集。加载时需指定路径至'train-*'文件,并可通过字段名访问'question'、'answer'及'evidence_pages'等关键属性。在模型评估中,推荐采用zero-shot或少样本设置,以检验预训练模型对长文本的泛化能力。由于提供了证据来源,可进一步设计精细化评估指标,如计算答案覆盖的证据页面与模型注意力分布之间的匹配度。此外,数据集适合与检索增强生成(RAG)流水线结合,验证检索模块在长文档中的定位准确性。对于需要微调的场景,建议划分验证集以监控过拟合,并利用其小规模特点快速迭代模型架构或训练策略。
背景与挑战
背景概述
在自然语言处理领域,长文档理解与推理能力的评测一直是研究热点。MMLongBench-Text-Only数据集应运而生,由华南理工大学等机构的研究人员于近年创建,旨在填补现有基准中缺乏对长文本、多文档复杂推理场景的评测空白。该数据集聚焦于跨文档问答任务,要求模型在大量无关信息中精准定位关键证据并生成结构化答案,其影响力体现在推动了长上下文模型在金融、法律等专业领域的实用化进程。
当前挑战
该数据集所解决的领域核心挑战在于长文本中多跳推理与证据追踪的困难,现有模型常因上下文过长导致注意力分散或信息遗忘,难以从超长文本中连贯地整合分散线索。构建过程中,数据标注面临两大挑战:一是需要人工从数百页文档中标注精确的跨文档证据链,耗时且易产生歧义;二是需设计统一的答案格式以兼容不同文档类型,确保评估的公平性与可复现性,这对数据质量把控提出了极高要求。
常用场景
经典使用场景
在自然语言处理与信息检索的交叉领域中,长文本理解与推理始终是极具挑战性的课题。MMLongBench-Text-Only数据集专为纯文本场景下的多文档、长文本问答而设计,其经典用法聚焦于评估模型在跨越数十至数百个文档片段时,精准定位证据来源并生成简洁答案的能力。研究者借助该数据集考察模型在复杂信息整合、跨文档指代消解及长距离依赖建模上的表现,从而推动对大规模语言模型在密集文本环境中的鲁棒性与效能进行系统性检验。
解决学术问题
该数据集针对现有基准在长文本推理任务中证据分散、答案格式多样且缺乏细粒度评估的短板,系统性地解决了如何设计高质量多文档问答评测框架的学术难题。通过引入证据页与证据来源的显式标注,MMLongBench-Text-Only促使研究者关注模型在噪声文本中挖掘关键信息的准确度,以及生成答案时对格式要求的遵循程度。这一设计不仅提升了评测的透明度和可重复性,还揭示了当前语言模型在长程语义推理与事实一致性方面的深层瓶颈,为改进模型架构与训练策略提供了重要参照。
实际应用
在现实场景中,诸如法律卷宗摘要、医疗文献综述、科研论文整合等任务均要求系统具备从海量纯文本文档中快速提炼核心答案的能力。MMLongBench-Text-Only的实例直接模拟了这些应用中的关键环节:用户提供一组相关文档与一个具体问题,模型须输出格式规范的答案并附带引用依据。因此,该数据集可用于验证智能问答系统在企业知识库、学术辅助平台或政务信息检索中的实用性,帮助开发者在部署前评估其产品对长文本支撑的可靠性与效率。
数据集最近研究
最新研究方向
在长文本理解与推理的前沿探索中,mmlongbench-text-only数据集正成为评估大语言模型超长上下文处理能力的基石。随着文档智能与知识密集型问答领域的迅猛发展,该数据集聚焦于多文档、长篇幅的文本分析,引导研究者攻克模型在复杂证据链整合与精准答案抽取中的瓶颈。其精细化的字段设计——如证据页与来源标注——为深入探究模型对长程依赖关系的把握提供了规范化基准,近期研究多围绕如何提升模型在真实场景下的长文档问答性能展开,对推动高效、可信的智能文本处理系统具有深远意义。
以上内容由遇见数据集搜集并总结生成


