LVOmniBench
收藏arXiv2026-03-20 更新2026-03-21 收录
下载链接:
https://kd-tao.github.io/LVOmniBench/
下载链接
链接失效反馈官方服务:
资源简介:
LVOmniBench是由浙江大学、西湖大学等机构联合创建的首个专注于长音频-视频跨模态理解的基准数据集。该数据集包含275个高质量长视频,时长介于10至90分钟,总时长140小时,覆盖娱乐、生活方式等五大领域,并严格筛选动态视听内容。通过人工标注构建了1,014个需跨模态推理的多选题,涵盖感知、理解、推理和逻辑四个认知维度。该数据集旨在解决现有评估对长视频(如影视、纪录片)理解不足的问题,推动全模态模型在复杂时空对齐和细粒度推理方面的研究。
LVOmniBench is the first benchmark dataset dedicated to long audio-visual cross-modal understanding, jointly created by institutions including Zhejiang University, Westlake University, and other relevant organizations. This dataset includes 275 high-quality long videos, with individual durations ranging from 10 to 90 minutes and a total cumulative duration of 140 hours, covering five major domains such as entertainment and lifestyle, with strictly curated dynamic audio-visual content. It features 1,014 multiple-choice questions requiring cross-modal reasoning, constructed via manual annotation, which cover four cognitive dimensions: perception, understanding, reasoning, and logic. This dataset is designed to address the gap in existing evaluations that lack sufficient assessment of long video (e.g., films and documentaries) understanding, and advance research on full-modal models in terms of complex spatio-temporal alignment and fine-grained reasoning.
提供机构:
浙江大学; 西湖大学; 蚂蚁集团; 上海创新研究院; 上海交通大学; 加州大学默塞德分校
创建时间:
2026-03-20
原始信息汇总
LVOmniBench 数据集概述
数据集基本信息
- 数据集名称: LVOmniBench
- 核心目标: 为全能模态大语言模型(OmniLLMs)在长音频-视频理解评估方面提供开创性的综合评估基准。
- 解决的问题: 当前评估主要针对10秒至5分钟的短音频和视频片段,无法反映现实应用中通常长达数十分钟的视频理解需求。
数据集构成
- 视频数量: 275个高质量视频。
- 视频时长范围: 10至90分钟。
- 视频平均时长: 2,069秒。
- 问答对数量: 1,014个手动构建的问答对。
- 问答对设计: 明确要求对音频和视觉模态进行联合推理。
评估维度与结果
- 难度等级: 低(Low)、中(Medium)、高(High)。
- 能力维度: 理解(Understanding)、感知(Perception)、推理(Inference)、逻辑(Logical)。
- 评估模型示例:
- Gemini-3.0-Pro (A + V): 平均得分65.8
- Gemini-3.0-Flash (A + V): 平均得分59.0
- Qwen3-VL-30B (V): 平均得分36.3
- Qwen2-Audio (A): 平均得分24.7
引用信息
-
引用格式:
@article{tao2026lvomnibench, title={LVOmniBench: Pioneering Long Audio-Video Understanding Evaluation for Omnimodal LLMs}, author={Keda Tao and Yuhua Zheng and Jia Xu and Wenjie Du and Kele Shao and Hesong Wang and Xueyi Chen and Xin Jin and Junhan Zhu and Bohan Yu and Weiqiang Wang and Jian Liu and Can Qin and Yulun Zhang and Ming-Hsuan Yang and Huan Wang}, journal={arXiv preprint arXiv:2603.19217}, year={2026} }
搜集汇总
数据集介绍
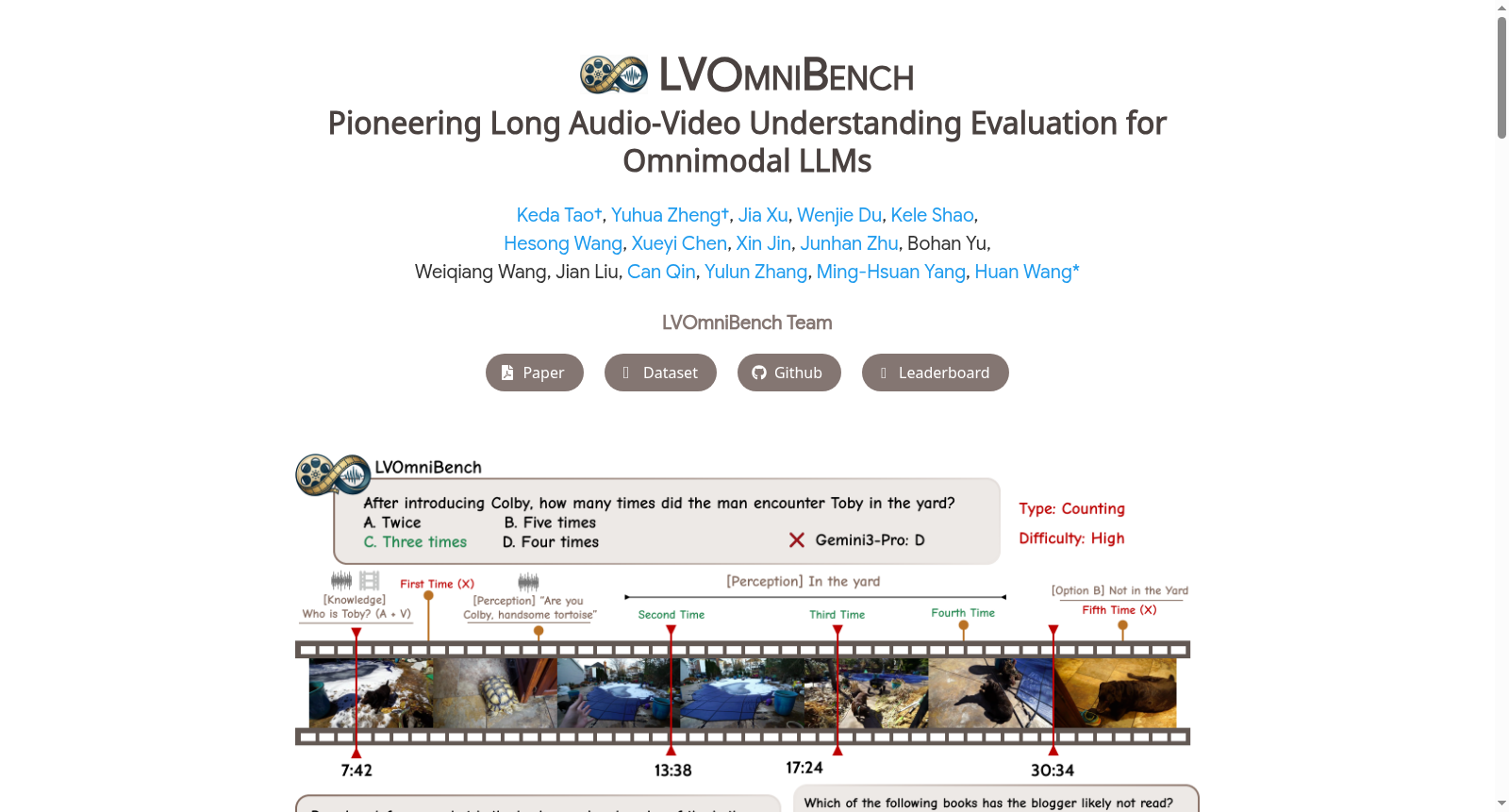
构建方式
在长音频视频理解领域,现有基准多聚焦于短片段,难以满足现实应用中对数十分钟级视频的分析需求。为填补这一空白,LVOmniBench通过严格的人工筛选与标注流程构建而成。研究团队从开放平台收集了超过3000个原始视频,依据创作共用许可确保合规性,并基于动态视听内容与丰富信息的原则,通过多轮人工过滤,最终精选出275个时长10至90分钟的高质量长视频。在此基础上,标注专家遵循跨模态推理必需、避免常识依赖、选项均衡等准则,手工构建了1014个高质量多项选择题对,确保每个问题均需联合音频与视觉信息才能解答。
特点
LVOmniBench的核心特点在于其针对长形式、跨模态理解的专门设计。数据集包含275个视频,总时长约140小时,平均视频长度超过34分钟,相比现有视听基准有6倍以上的时长扩展,更贴近真实场景的视频规模。其1014个问题被精心划分为感知、理解、推理与逻辑四大类型,并进一步细分为九个子类别,同时每个问题均标注了低、中、高三个难度等级,支持对模型能力进行分层评估。数据覆盖娱乐、生活、影视等五大领域共21个子类,确保了内容的多样性与泛化性。其构建完全依赖于人工筛选与标注,避免了自动生成方法可能带来的幻觉与偏差,保证了评估的高保真度与挑战性。
使用方法
LVOmniBench主要用于系统评估全模态大语言模型在长音频视频联合理解上的能力。使用时,模型接收完整的视频及其同步音频流作为输入,并回答对应的多项选择题。评估涵盖模型在长时记忆、时序定位、细粒度理解及多模态感知等多个维度的表现。研究已表明,当前开源模型在该基准上准确率普遍低于35%,而性能最佳的Gemini 3 Pro模型也仅达到约65%的准确率,揭示了处理长视听序列仍是重大挑战。该基准不仅可用于衡量模型整体性能,其分层难度与问题类型设计也支持针对性地分析模型在特定能力(如计数、音乐感知、时空推理)上的短板,从而为改进模型架构、优化长上下文处理与跨模态对齐技术提供明确的指导方向。
背景与挑战
背景概述
随着全模态大语言模型在音频与视频理解领域的快速发展,现有评估基准主要聚焦于数秒至数分钟的短片段,难以反映现实世界中长达数十分钟的视频内容所带来的复杂挑战。为此,浙江大学、西湖大学与蚂蚁集团等机构的研究团队于2026年联合推出了LVOmniBench,这是首个专门针对长时音频-视频跨模态理解而设计的评估基准。该数据集精心筛选了275个时长10至90分钟的高质量视频,涵盖娱乐、生活、影视等多元场景,并手工标注了1014个需联合音视频推理的多选题对。LVOmniBench旨在系统评估模型在长时记忆、时序定位、细粒度感知及多模态推理等方面的能力,为全模态大语言模型在真实长视频场景下的性能提供了严谨的衡量标准,显著推动了音频-视频联合理解研究的前沿发展。
当前挑战
LVOmniBench所应对的核心领域挑战在于长时音频-视频的联合理解,这要求模型能够对长达数十分钟的连续音视频流进行精细化的跨模态对齐与深层语义推理。具体任务涉及长时记忆保持、复杂事件时序定位、非语音音频(如音乐、环境音)的细粒度感知以及跨模态逻辑推理等高阶认知能力。在数据集构建过程中,研究团队面临多重挑战:首先,需从开放平台海量视频中筛选出兼具音视频动态丰富性、内容多样性且符合版权要求的长视频资源;其次,为确保评估的严谨性,所有问题均需通过人工标注保证其必须依赖音视频联合信息方可解答,并需避免单一模态偏见或常识性知识干扰;此外,标注过程中还需严格控制时间戳等显式提示的使用,以防止模型通过简单匹配而非深层理解获得答案,这些严格的设计准则显著提升了数据集的构建难度与质量门槛。
常用场景
经典使用场景
在音频-视频多模态大语言模型的研究领域,LVOmniBench 作为首个专注于长时音频-视频内容理解的基准测试,其经典使用场景在于系统性地评估模型对长达10至90分钟视频的跨模态理解能力。该数据集通过精心筛选的275个高质量长视频和1014个人工标注的问答对,构建了涵盖感知、理解、推理与逻辑等多个维度的分层评估体系。研究者利用这一基准,能够深入探究模型在长时记忆、时序定位、细粒度感知及多模态对齐等核心任务上的表现,从而揭示现有模型在处理真实世界长视频内容时的瓶颈与局限。
衍生相关工作
LVOmniBench 的发布催生了一系列围绕长时音频-视频理解的衍生研究工作。在模型架构方面,研究者们开始设计专门用于处理超长音频-视频序列的神经网络,探索更高效的跨模态融合机制与长时上下文建模方法。在训练策略上,出现了针对长时记忆与时序对齐的预训练与微调技术。同时,该基准也激发了对于多模态token压缩、动态分辨率输入以及流式理解等高效推理方法的研究,以应对长视频带来的计算开销挑战。此外,基于LVOmniBench揭示的模型缺陷,如音乐感知、计数能力不足等,后续工作开始聚焦于提升模型对非语音音频的抽象理解能力与精细的空间-时间推理能力,推动了整个领域向更鲁棒、更实用的长时多模态系统迈进。
数据集最近研究
最新研究方向
随着全模态大语言模型在视听理解领域的快速发展,评估基准的构建正从短片段分析转向对长时域、高动态交织内容的深度考察。LVOmniBench作为首个专注于长音频-视频联合理解的基准,其前沿研究聚焦于模型在跨模态对齐、时序定位、细粒度感知及复杂逻辑推理等方面的能力评估。当前热点集中于探索模型在超长上下文(平均时长超30分钟)中处理语音、音乐与环境声音等多类音频信号时的性能瓶颈,尤其关注开源模型与闭源模型间存在的显著差距。这一研究方向不仅揭示了现有模型在长时视听序列建模、非语言音频理解以及跨模态语义融合等方面的根本性挑战,也为推动下一代全模态大语言模型在真实场景中的实用化演进提供了关键的评估范式和改进路径。
相关研究论文
- 1LVOmniBench: Pioneering Long Audio-Video Understanding Evaluation for Omnimodal LLMs浙江大学; 西湖大学; 蚂蚁集团; 上海创新研究院; 上海交通大学; 加州大学默塞德分校 · 2026年
以上内容由遇见数据集搜集并总结生成


