wallpapers-cog-icl
收藏Hugging Face2024-06-29 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/panopstor/wallpapers-cog-icl
下载链接
链接失效反馈官方服务:
资源简介:
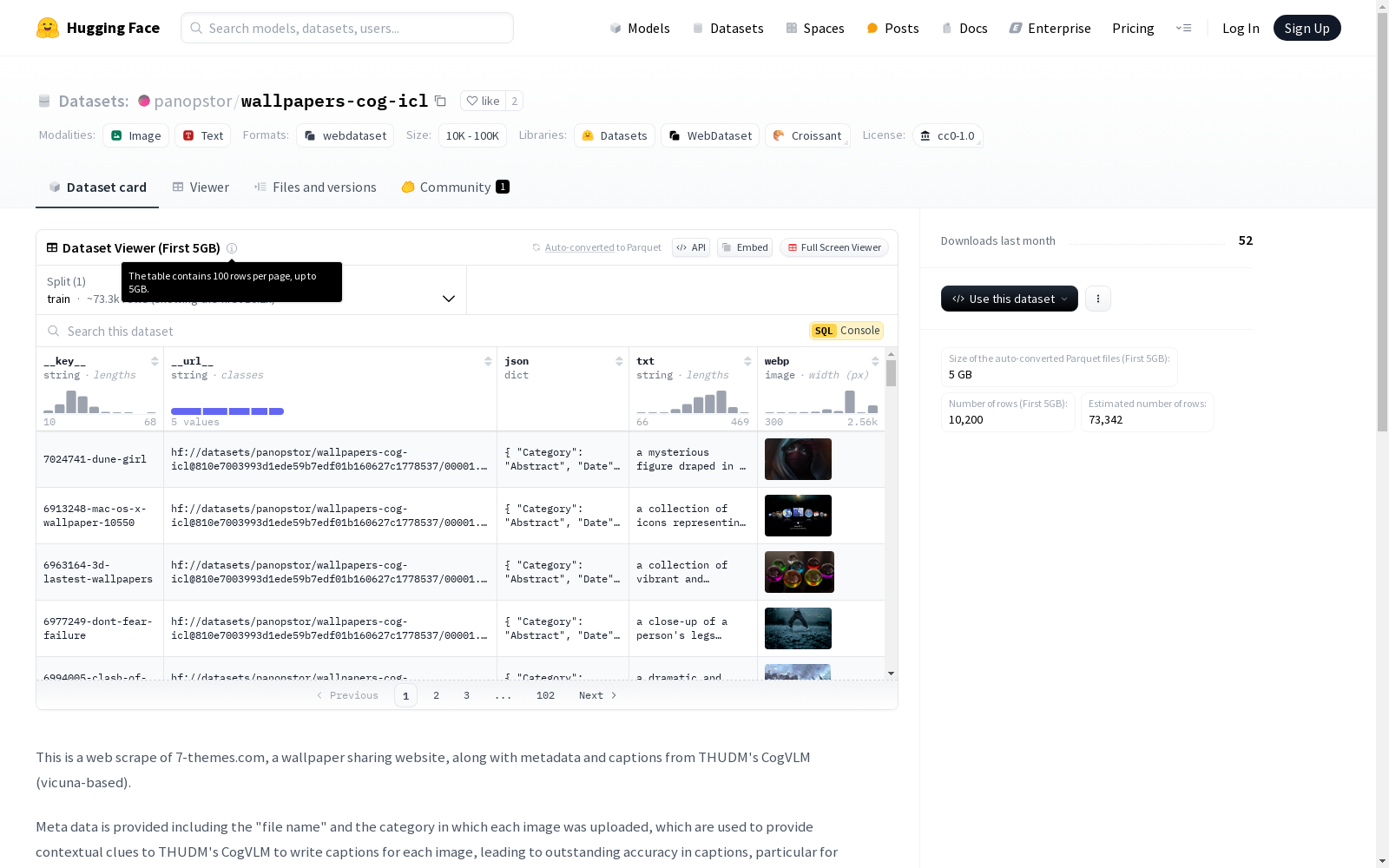
该数据集包含从7-themes.com网站抓取的壁纸图片及其元数据和来自THUDM的CogVLM的描述。元数据包括每个图像的文件名和上传类别,这些信息用于为CogVLM提供上下文线索,以编写每个图像的描述,特别适用于特定对象或角色的正确名称。图像文件被调整到最大尺寸2560x1440,并使用PIL库以WEBP格式质量95保存。附加的json文件包含每个图像着陆页的元数据,尽管只有文件名和类别用于驱动上下文学习。
创建时间:
2024-06-25
原始信息汇总
数据集概述
数据来源
- 数据集来自壁纸分享网站7-themes.com的网页抓取。
数据内容
- 包含图像文件及其元数据和来自THUDM的CogVLM(基于vicuna)的描述。
图像处理
- 图像文件被调整大小至最大2560x1440(如果超过),并使用PIL库以WEBP格式保存,质量为95。
元数据
- 元数据包括每个图像的“文件名”和上传类别,用于为CogVLM提供上下文线索,以生成图像描述。
- 附加的JSON文件包含每个图像落地页的元数据,但仅使用“文件名”和类别进行上下文学习。
描述生成
- 使用脚本进行描述生成,脚本链接:https://github.com/victorchall/EveryDream2trainer/blob/main/caption.py
- 脚本文档链接:https://github.com/victorchall/EveryDream2trainer/blob/main/doc/CAPTION_COG.md
- 命令行参数包括:
--prompt_plugin "from_image_json":触发读取每个图像的附加JSON文件,并将元数据插入到Cog模型的提示中。--exclude_keys "Uploaded by,Date,Image Size,File Size":排除非有用的元数据元素。--starts_with "This image shows"和--remove_starts_with:在输出中加入起始短语,但最终描述中会移除。
示例
-
实际提供给Cog的提示示例:
Hint: {"File Name": "John Lennon", "Category": "Celebrities"} Write a description.
输出:
John Lennon, a legendary musician and member of the Beatles. He is captured in a candid moment, wearing his signature round sunglasses and a striped shirt. The background features a grassy field, suggesting an outdoor setting.
搜集汇总
数据集介绍
构建方式
wallpapers-cog-icl数据集通过爬取7-themes.com壁纸分享网站的图像及其元数据构建而成。每张图像的元数据包括文件名和上传类别,这些信息被用于为THUDM的CogVLM模型提供上下文线索,以生成图像描述。图像文件被调整为最大2560x1440分辨率,并以WEBP格式保存,质量设置为95。此外,每个图像的元数据通过JSON文件存储,仅使用文件名和类别信息驱动上下文学习。
使用方法
使用该数据集时,可以通过提供的Python脚本调用CogVLM模型生成图像描述。脚本支持从JSON文件中读取元数据,并将其嵌入到模型的提示中,从而生成更具上下文相关性的描述。用户可以通过调整参数如`--prompt_plugin`和`--exclude_keys`来优化描述生成过程。生成的描述以自然语言形式呈现,适合用于图像理解、内容生成等任务。
背景与挑战
背景概述
wallpapers-cog-icl数据集源于对7-themes.com壁纸分享网站的网页抓取,结合了THUDM的CogVLM模型生成的元数据和描述。该数据集的核心研究问题在于通过上下文学习生成高质量的图像描述,特别是针对特定对象或角色的名称。数据集中的图像文件经过调整,最大分辨率限制在2560x1440,并以WEBP格式保存。THUDM的CogVLM模型通过结合图像文件名和类别信息,生成具有高准确度的描述,显著提升了图像描述生成的质量。该数据集为图像描述生成领域提供了新的研究资源,推动了多模态学习的发展。
当前挑战
wallpapers-cog-icl数据集在构建过程中面临多重挑战。首先,图像描述的生成依赖于CogVLM模型的上下文学习能力,如何有效利用图像文件名和类别信息生成精准描述是一个关键问题。其次,数据集的构建需要对大量图像进行预处理,包括分辨率调整和格式转换,这对计算资源和存储空间提出了较高要求。此外,模型在生成描述时需避免无关信息的干扰,例如上传者、日期等元数据,这对提示工程的设计提出了挑战。最后,如何确保生成的描述在多样性和准确性之间取得平衡,也是该数据集需要解决的核心问题。
常用场景
经典使用场景
在计算机视觉与自然语言处理的交叉领域,wallpapers-cog-icl数据集被广泛应用于图像描述生成任务。通过结合图像元数据与THUDM的CogVLM模型,该数据集能够生成高度准确的图像描述,尤其擅长识别特定对象或人物的名称。这一特性使其成为研究图像理解与文本生成之间关系的理想工具。
解决学术问题
该数据集有效解决了图像描述生成中的上下文理解问题。传统方法往往难以准确捕捉图像中的细节与背景信息,而wallpapers-cog-icl通过引入元数据驱动的上下文学习机制,显著提升了描述的准确性与丰富性。这一突破为图像理解与自然语言生成的融合研究提供了新的思路与数据支持。
实际应用
在实际应用中,wallpapers-cog-icl数据集被广泛用于智能图像检索、内容推荐系统以及辅助视觉障碍人士的图像描述生成。其高精度的描述能力使得用户能够通过文本快速定位目标图像,同时为个性化推荐系统提供了丰富的语义信息。此外,该数据集还为无障碍技术提供了重要的技术支持。
数据集最近研究
最新研究方向
在计算机视觉与自然语言处理的交叉领域,wallpapers-cog-icl数据集的研究方向主要集中在图像描述生成(Image Captioning)的优化与上下文学习(In-context Learning)的应用。通过结合THUDM的CogVLM模型,该数据集利用图像元数据(如文件名和类别)作为上下文提示,显著提升了图像描述的准确性和细节丰富度,尤其是在特定对象或人物的命名上表现出色。当前研究热点包括如何进一步优化提示工程(Prompt Engineering)以增强模型的上下文理解能力,以及探索多模态学习在图像描述任务中的潜力。这一方向不仅推动了图像描述技术的进步,也为多模态人工智能的发展提供了新的研究视角。
以上内容由遇见数据集搜集并总结生成


