Visuelle 2.0
收藏arXiv2022-11-30 更新2024-06-21 收录
下载链接:
https://humaticslab.github.io/forecasting/visuelle
下载链接
链接失效反馈官方服务:
资源简介:
Visuelle 2.0是由意大利著名公司Nuna Lie与维罗纳大学合作创建的,旨在解决快时尚行业的多样化预测问题。该数据集包含5355件服装产品的数据,涵盖6个时尚季节,每件产品配有高清图像和多模态信息。数据集创建过程中,特别关注了短观察期新产品销售预测问题,利用图像数据和深度网络提高预测性能。Visuelle 2.0的应用领域主要集中在快时尚公司的新产品需求预测、销售预测和产品推荐,通过结合图像数据和时间序列分析,提升预测准确性。
Visuelle 2.0 was developed in collaboration between the renowned Italian firm Nuna Lie and the University of Verona, aiming to address diversified forecasting challenges in the fast fashion industry. This dataset contains data on 5,355 clothing products spanning 6 fashion seasons, with each product equipped with high-definition images and multimodal information. During the dataset construction process, special focus was placed on the sales forecasting problem of new products with short observation periods, leveraging image data and deep networks to improve forecasting performance. The main application scenarios of Visuelle 2.0 cover new product demand forecasting, sales forecasting and product recommendation for fast fashion companies, where it enhances forecasting accuracy by combining image data and time series analysis.
提供机构:
维罗纳大学
创建时间:
2022-04-14
搜集汇总
数据集介绍
构建方式
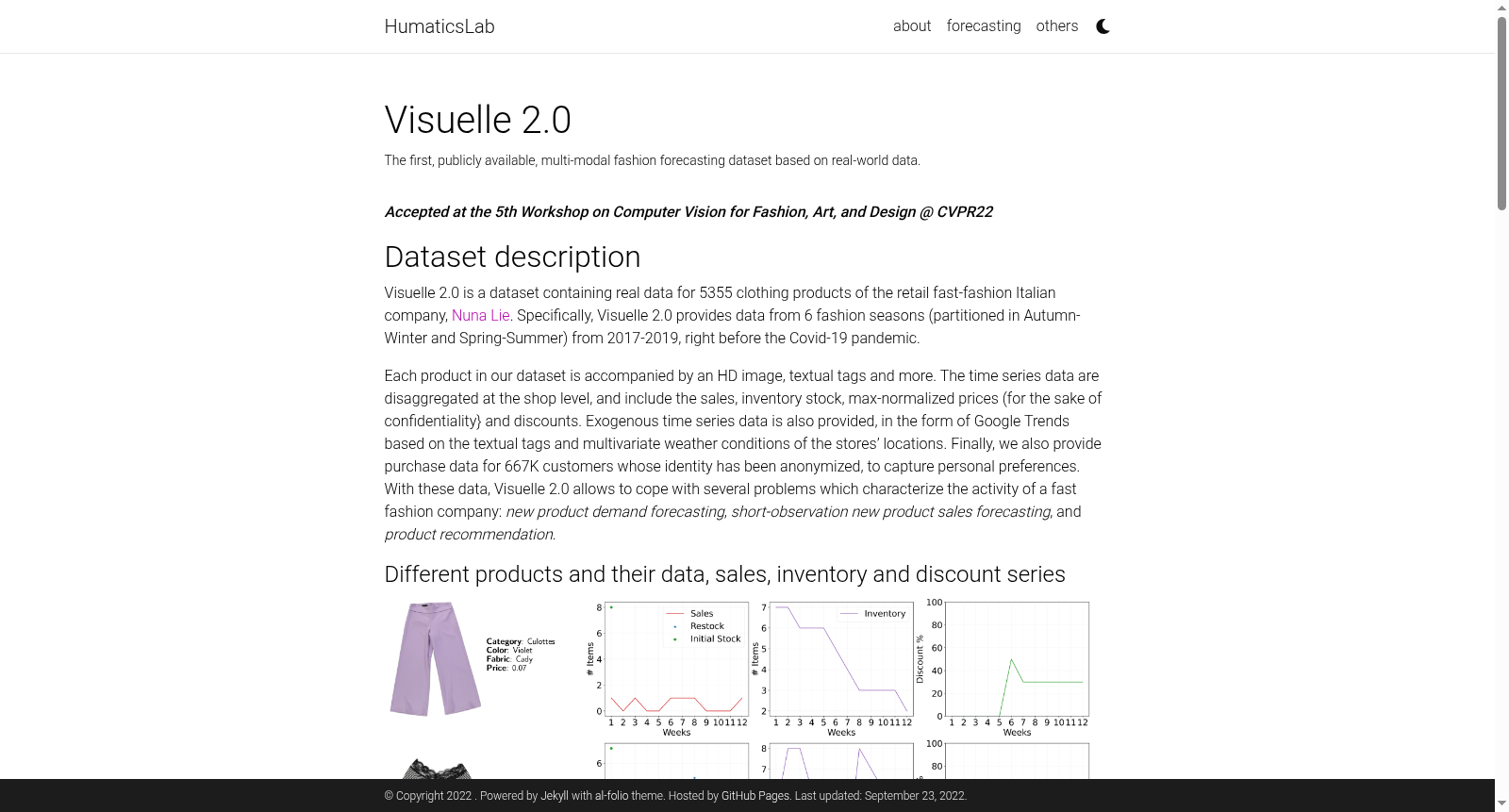
在时尚零售领域,精准预测新产品的销售表现对于库存管理和市场策略至关重要。Visuelle 2.0数据集的构建基于意大利快时尚品牌Nuna Lie的实际运营数据,涵盖了2016年至2019年间的六个季节,共包含5355种服装产品在110家店铺的销售记录。数据采集以周为单位,详细记录了每个产品在每家店铺的销售数量、库存水平、价格折扣以及补货标志。为确保数据的纯净性,研究团队剔除了因缺货导致的零销售记录,仅保留反映产品真实市场表现的合法销售信号。此外,数据集还整合了高分辨率产品图像、文本标签(如类别、颜色和面料)、匿名化的顾客购买历史,以及基于Google Trends的流行度数据和店铺所在地的天气报告,形成了多模态、细粒度的时尚零售数据资源。
特点
Visuelle 2.0数据集的核心特点在于其多模态与细粒度的数据架构。它不仅提供了传统的销售时间序列,还融合了视觉、文本和外部环境信息,为计算机视觉与时间序列分析的交叉研究提供了丰富素材。数据以产品-店铺对为单位进行分解,使得研究者能够深入探究地理和店铺特异性对销售的影响。图像数据以高清形式呈现,背景纯净,便于视觉特征提取;文本标签经过专业团队验证,确保了语义的准确性。此外,数据集引入了短期观测新产品销售预测(SO-fore)这一新颖任务,聚焦于仅凭数周销售历史进行长期预测的挑战,突显了视觉相似性在弥补数据稀疏性方面的价值。外部数据如天气和网络趋势的加入,进一步增强了数据集的现实复杂性与预测潜力。
使用方法
Visuelle 2.0数据集适用于多种时尚零售分析任务,尤其侧重于短期观测新产品销售预测(SO-fore)。研究者可利用数据集中的销售时间序列、图像和文本标签,构建多模态预测模型,例如结合注意力机制的循环神经网络,以探索视觉信息在提升长期销售预测精度中的作用。数据可按季节、店铺或产品类别进行划分,支持训练集与测试集的时序分离,确保模型评估的时效性。对于SO-fore任务,典型的设置包括以两周观测窗口预测未来十周销售(SO-fore2-10)或以两周观测预测单周销售(SO-fore2-1),这有助于模拟快时尚行业中的快速补货决策场景。此外,数据集还可用于需求预测、产品推荐等任务,通过整合顾客购买历史和外部趋势数据,深化对消费者行为与市场动态的理解。
背景与挑战
背景概述
在时尚零售与计算机视觉交叉领域,Visuelle 2.0数据集由意大利维罗纳大学与Humatics公司等机构于2022年联合发布,标志着快时尚行业首次公开多模态销售预测基准。该数据集聚焦于短观测新产品销售预测这一核心研究问题,涵盖2016至2020年间意大利知名品牌Nuna Lie的5355款服装产品,整合了店铺级销售时序、高清图像、文本属性及天气趋势等外生数据。其创新性在于通过视觉相似性弥补新品历史数据缺失的局限,为多模态深度学习模型在时尚预测中的应用提供了实证基础,推动了运营研究与计算机视觉的深度融合。
当前挑战
Visuelle 2.0所针对的短观测销售预测问题,面临历史数据稀疏性与时尚趋势动态性的双重挑战:新品上市仅有两周观测窗口,却需预测长达十周的销售走势,传统时序方法因信息有限而性能受限。构建过程中的挑战则体现在多源异构数据的对齐与标准化上,包括跨110家店铺的销售信号去库存化处理、图像与文本属性的语义关联标注,以及顾客购买记录在匿名化前提下的可用性保障。此外,外生数据如谷歌趋势与天气报告的时空匹配,亦增加了数据集构建的复杂度。
常用场景
经典使用场景
在时尚零售领域,快速响应市场变化是企业的核心挑战之一。Visuelle 2.0数据集通过整合多模态数据,为短观察期新产品销售预测(SO-fore)提供了经典应用场景。该场景聚焦于时尚季开始后,新产品上架仅数周内,基于有限的销售历史数据,预测未来十周或单周的销售趋势。这一过程不仅依赖时间序列分析,还深度融合了产品图像、文本属性及外部因素如天气和谷歌趋势数据,从而在缺乏长期统计信息的情况下,通过视觉相似性捕捉历史模式,优化库存管理和补货策略。
实际应用
在实际应用中,Visuelle 2.0数据集被广泛用于支持快速时尚公司的运营决策。企业可利用该数据集构建智能预测系统,实时监控新产品上市初期的销售动态,从而优化库存分配和补货计划。例如,在SO-fore2-10场景中,系统能基于两周销售数据预测十周需求,帮助公司减少库存积压或缺货风险;而在SO-fore2-1场景中,则支持每周调整补货策略,适应超快时尚供应链的敏捷需求。此外,数据集中的客户购买数据还可用于个性化推荐,提升消费者体验和销售转化率,体现了数据驱动决策在时尚零售中的实际价值。
衍生相关工作
Visuelle 2.0数据集催生了多项经典研究工作,尤其是在多模态预测模型的创新方面。基于该数据集,研究者开发了交叉注意力循环神经网络等架构,这些模型通过融合图像、文本和时间序列数据,显著提升了销售预测的精度。后续工作进一步扩展了外生变量的应用,如整合谷歌趋势和天气报告数据,以捕捉产品流行度和环境因素的影响。此外,数据集还激发了需求预测和产品推荐领域的新探索,例如利用深度学习技术进行新产品需求预估,以及基于客户历史购买行为的协同过滤推荐系统。这些衍生工作不仅丰富了时尚预测的研究范畴,也为产业实践提供了可扩展的解决方案。
以上内容由遇见数据集搜集并总结生成


