liaad/PtBrVId
收藏Hugging Face2025-08-15 更新2024-06-11 收录
下载链接:
https://hf-mirror.com/datasets/liaad/PtBrVId
下载链接
链接失效反馈官方服务:
资源简介:
PtBrVId数据集是一个由多个已有数据集组成的语料库,涵盖了文学、政治、新闻、社交媒体等多个领域,并且包含了葡萄牙语的不同变体(PT-PT和PT-BR)。数据集经过了预处理,包括去除NaN值、空文档、重复文档,以及使用clean_text库清理文本。数据集的类别分布不均衡,未来计划发布更均衡的版本。
PtBrVId dataset is a corpus composed of multiple existing datasets, covering multiple domains including literature, politics, news, social media, etc., and includes different variants of Portuguese (PT-PT and PT-BR). The dataset has been preprocessed, with operations including removing NaN values, empty documents and duplicate documents, as well as text cleaning using the clean_text library. The category distribution of the dataset is imbalanced, and a more balanced version is planned to be released in the future.
提供机构:
liaad
原始信息汇总
数据集概述
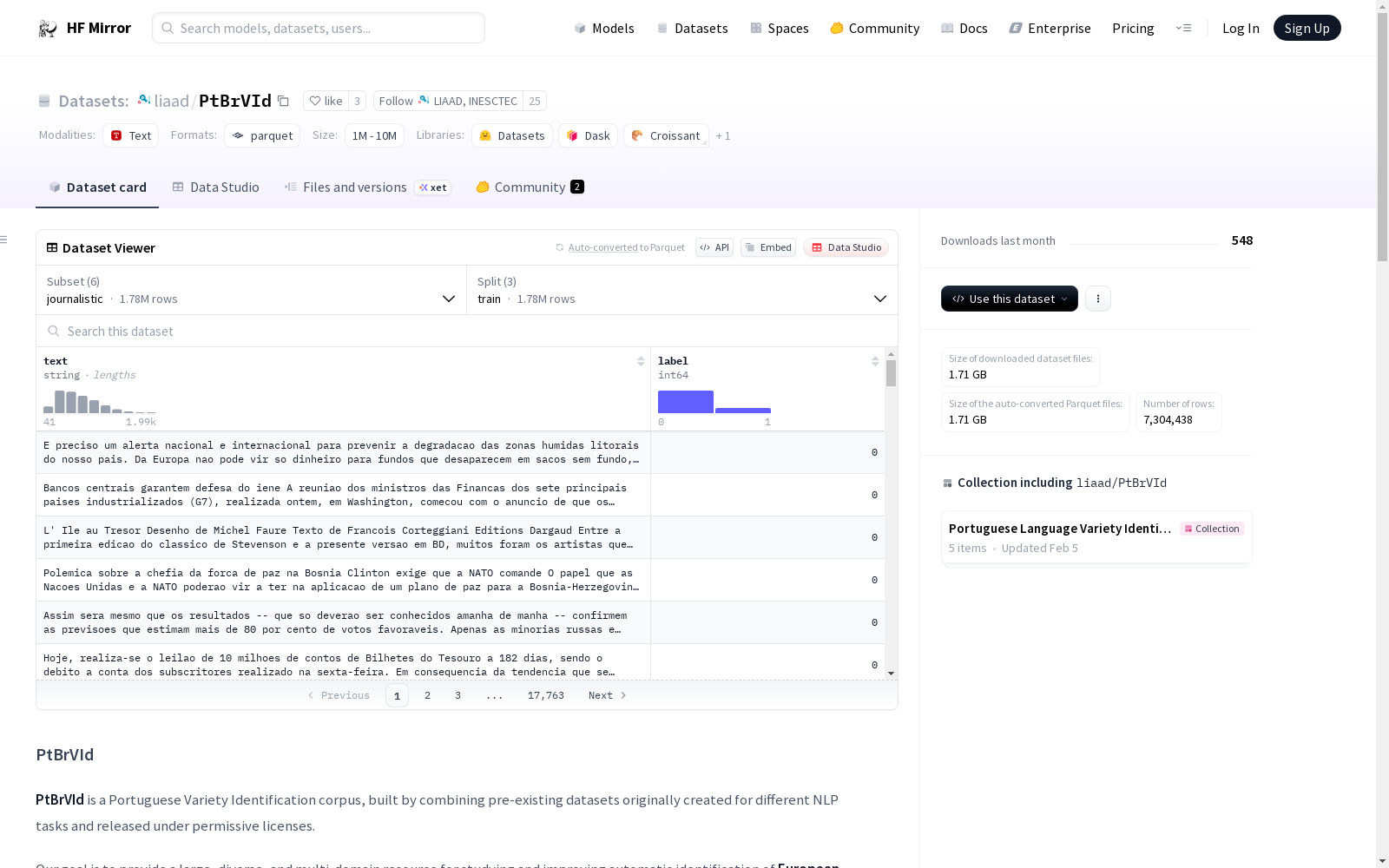
数据集配置
-
journalistic
- 特征:
text: 数据类型为stringlabel: 数据类型为int64
- 分割:
train: 包含1744753个示例,占用1174099478字节
- 下载大小: 790547389字节
- 数据集大小: 1174099478字节
- 特征:
-
legal
- 特征:
text: 数据类型为stringlabel: 数据类型为int64
- 分割:
train: 包含466434个示例,占用146574307字节
- 下载大小: 89418636字节
- 数据集大小: 146574307字节
- 特征:
-
literature
- 特征:
text: 数据类型为stringlabel: 数据类型为int64
- 分割:
train: 包含90526个示例,占用30417858字节
- 下载大小: 21226294字节
- 数据集大小: 30417858字节
- 特征:
-
politics
- 特征:
text: 数据类型为stringlabel: 数据类型为int64
- 分割:
train: 包含5810个示例,占用7970329字节
- 下载大小: 4605661字节
- 数据集大小: 7970329字节
- 特征:
-
social_media
- 特征:
text: 数据类型为stringlabel: 数据类型为int64
- 分割:
train: 包含2020928个示例,占用265857455字节
- 下载大小: 188356429字节
- 数据集大小: 265857455字节
- 特征:
-
web
- 特征:
text: 数据类型为stringlabel: 数据类型为int64
- 分割:
train: 包含140887个示例,占用278541298字节
- 下载大小: 165251198字节
- 数据集大小: 278541298字节
- 特征:
数据文件
- journalistic
train: 路径为journalistic/train-*
- legal
train: 路径为legal/train-*
- literature
train: 路径为literature/train-*
- politics
train: 路径为politics/train-*
- social_media
train: 路径为social_media/train-*
- web
train: 路径为web/train-*
搜集汇总
数据集介绍
构建方式
PtBrVId 数据集的构建基于多个领域的数据集,旨在为研究并提高自动识别欧洲葡萄牙语(PT-PT)和巴西葡萄牙语(PT-BR)的能力提供大规模、多样化和多领域的资源。该数据集通过结合预存在的、最初为不同NLP任务创建并发布在许可协议下的数据集而构建。为确保数据的单一变体内容,数据集从多个领域进行选择。目前发布的版本是银标签和无监督的,意味着不能完全保证所有文档严格单一变体。未来版本将包括一个经过细化的注释方案,该方案将结合自动和手动验证。
特点
PtBrVId 数据集的特点在于其多样性和多领域性,它包含了来自文学、政治、新闻、社交媒体和网页等多个领域的数据。每个领域的数据都尽可能地确保单一变体内容。数据集的规模庞大,例如在新闻领域,训练集包含约177万个示例。此外,数据集是银标签和无监督的,虽然不能完全保证所有文档的单一变体,但为研究提供了宝贵资源。
使用方法
使用 PtBrVId 数据集的方法包括以下几个步骤:首先,用户需要下载适合其研究需求的配置,例如新闻、法律等。然后,用户可以从训练集、验证集或测试集中选择所需的数据。数据集提供了文本和标签两个特征,其中文本是以字符串形式存储的,标签是以整数64位形式存储的。用户可以使用 Python 等编程语言对数据进行处理和分析。
背景与挑战
背景概述
PtBrVId 数据集是一个葡萄牙语变体识别语料库,旨在提供一个大型的、多样化的和多领域的资源,以研究和提高自动识别欧洲葡萄牙语(PT-PT)和巴西葡萄牙语(PT-BR)的能力。该数据集由已知主要包含单一变体葡萄牙语文本的数据源组合而成,并采用了宽松的许可协议。PtBrVId 的创建是为了满足自然语言处理领域中识别不同葡萄牙语变体的需求,这对于跨语言理解和翻译至关重要。该数据集的创建时间为 2025 年,由 Hugo Sousa、Rúben Almeida 等研究人员开发,并发表于 AAAI 会议。PtBrVId 对相关领域产生了深远的影响,为葡萄牙语自然语言处理研究和应用提供了宝贵的数据资源。
当前挑战
PtBrVId 数据集在构建过程中面临的主要挑战包括:1) 保证数据集中文本的单一变体特性,尽管数据来源已选择性地包含单一变体内容,但仍需确保语料的纯度;2) 数据集的标注工作,目前版本为银级标注且为无监督,无法完全保证所有文档的变体标签准确性,未来版本将引入自动标注和人工验证相结合的策略以提高标注质量;3) 数据集的预处理,包括去除 NaN 值、空文档、重复文档,以及应用 `clean-text` 库去除非相关内容等步骤,确保数据质量;4) 数据集的规模和多样性,尽管 PtBrVId 包含大量数据,但仍需不断扩充和更新以适应不断变化的语言使用情况。
常用场景
经典使用场景
PtBrVId 数据集是一个用于研究自动识别欧洲葡萄牙语(PT-PT)和巴西葡萄牙语(PT-BR)的语料库。该数据集包含来自不同领域的数据集,旨在提供一个大规模、多样化的多领域资源。经典的使用场景包括使用该数据集来训练和评估机器学习模型,以便自动识别文本中的葡萄牙语变体。
解决学术问题
PtBrVId 数据集解决了自动识别葡萄牙语变体的学术研究问题。通过提供大规模、多样化的数据集,PtBrVId 有助于改进和评估自动识别模型,从而提高模型的准确性和可靠性。这对于语言处理和自然语言理解等领域的研究具有重要意义。
衍生相关工作
PtBrVId 数据集衍生了一些相关的经典工作。例如,可以使用 PtBrVId 数据集来训练和评估用于语言识别的模型,以便自动识别文本中的葡萄牙语变体。此外,PtBrVId 数据集还可以用于研究和改进机器翻译模型,以便更好地翻译葡萄牙语文本。
以上内容由遇见数据集搜集并总结生成


