Seoul World Model (SWM) Dataset
收藏arXiv2026-03-17 更新2026-03-18 收录
下载链接:
https://seoul-world-model.github.io
下载链接
链接失效反馈官方服务:
资源简介:
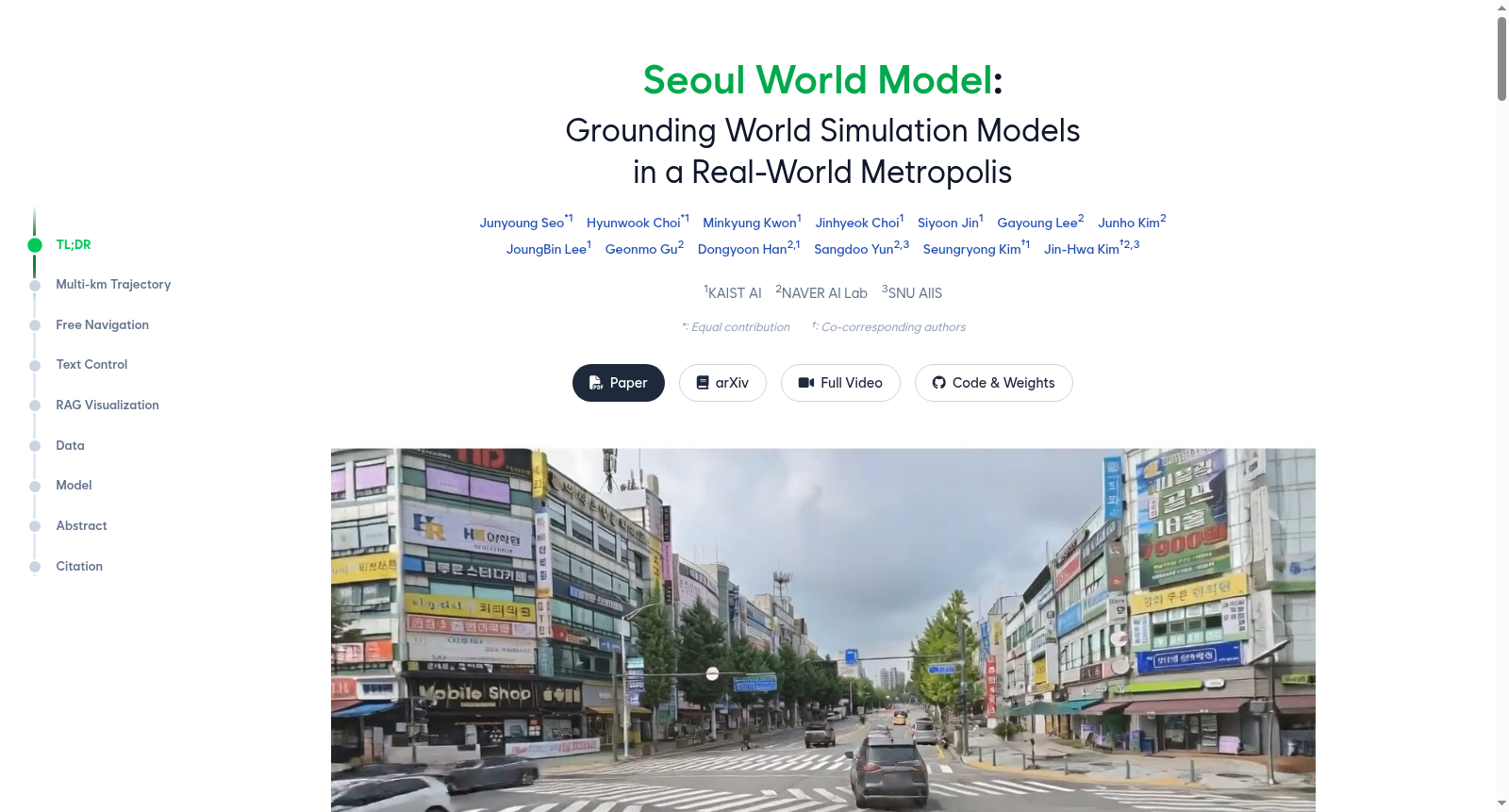
首尔世界模型(SWM)数据集是由韩国科学技术院、NAVER AI实验室等机构联合构建的城市级仿真数据集,旨在实现真实城市环境下的视频生成。该数据集包含44万条首尔街景图像,辅以合成驾驶视频(12.7K条)及公开驾驶数据集,覆盖431,500平方米城市区域。数据通过跨时间配对策略消除瞬时内容干扰,并采用间歇冻结帧技术解决街景稀疏性问题。其核心应用为自动驾驶场景生成、城市规划和沉浸式导航,通过地理检索增强生成技术将视频内容锚定真实城市几何结构,支持数百米轨迹的连贯生成。
The Seoul World Model (SWM) Dataset is an urban-scale simulation dataset jointly developed by entities including the Korea Advanced Institute of Science and Technology (KAIST) and NAVER AI Lab, aimed at generating videos within realistic urban environments. This dataset comprises 440,000 street view images of Seoul, supplemented by 12.7K synthetic driving videos and public driving datasets, covering an urban area of 431,500 square meters. It eliminates transient content disturbances through a cross-temporal pairing strategy, and addresses the sparsity issue of street view data using the intermittent freeze-frame technique. Its core applications cover autonomous driving scenario generation, urban planning and immersive navigation. By leveraging geographic retrieval-augmented generation technology, it anchors video content to real-world urban geometric structures, enabling coherent generation of trajectories spanning hundreds of meters.
提供机构:
韩国科学技术院·人工智能实验室; NAVER AI实验室; 首尔国立大学·人工智能与系统研究所
创建时间:
2026-03-17
搜集汇总
数据集介绍
构建方式
在构建Seoul World Model (SWM)数据集的过程中,研究团队采用了多源数据融合的策略,以解决城市尺度世界模型在真实环境中的时空对齐挑战。数据集的核心构建基于首尔地区的440,000张街景图像,这些图像通过跨时间配对技术进行处理,确保参考图像与目标序列在时间戳上存在差异,从而鼓励模型区分场景中的持久结构与瞬态内容。此外,为了弥补真实街景数据在轨迹覆盖和时间连续性上的不足,团队利用基于Unreal Engine的模拟器生成了大规模合成城市数据集,提供了包括行人、车辆和自由相机在内的多样化轨迹。同时,通过视图插值管道,将稀疏的街景关键帧合成为时间连贯的训练视频,进一步增强了数据的时空一致性。
特点
SWM数据集的特点在于其独特的真实世界锚定能力与时空动态建模的融合。数据集通过跨时间配对机制,有效解耦了场景中的静态几何结构与动态对象,使得模型能够专注于学习城市环境的持久特征。合成数据的引入极大地丰富了相机轨迹的多样性,涵盖了从驾驶视角到行人路径的多种运动模式,提升了模型对不同运动类型的适应性。此外,数据集还整合了几何与语义参考系统,通过深度估计和相机姿态信息,为生成视频提供了精确的空间布局和外观细节条件,确保了生成内容与真实城市环境在几何和视觉上的一致性。
使用方法
SWM数据集的使用方法围绕其检索增强的生成框架展开。在模型推理阶段,用户需提供起始地理坐标、相机运动轨迹和文本提示,系统会从地理索引的街景数据库中检索邻近的参考图像。这些图像通过虚拟前瞻锚点机制被动态引入,作为未来位置的稳定锚定,以缓解长时域生成中的误差累积问题。同时,几何参考通过深度重投影将参考图像的空间布局信息注入目标视角,而语义参考则直接注入原始外观细节,两者互补确保了生成视频的空间忠实性和视觉保真度。该框架支持教师强制和自强制两种训练配置,能够适应不同的生成场景和效率需求。
背景与挑战
背景概述
首尔世界模型数据集由KAIST AI、NAVER AI Lab及SNU AIIS的研究团队于2026年提出,旨在解决视频世界仿真模型在真实城市环境中的落地问题。该数据集以韩国首尔为地理锚点,通过整合44万张街景图像、真实驾驶视频与合成城市数据,构建了城市尺度的视频生成基准。其核心研究问题在于如何将自回归视频生成与真实世界的地理几何结构对齐,从而支持城市规划可视化、自动驾驶场景生成等应用,推动了物理世界仿真与生成式人工智能的交叉领域发展。
当前挑战
该数据集面临的挑战主要集中于两方面:在领域问题层面,需克服真实城市环境中视频生成的时空对齐难题,包括动态场景与静态街景参考之间的时间错位,以及长距离生成中的误差累积问题;在构建过程层面,数据稀疏性与轨迹多样性不足构成显著障碍,街景图像以稀疏间隔采集,缺乏连续视频数据,且车辆采集的轨迹类型有限。研究团队通过跨时间配对、大规模合成数据集与视图插值流水线等方法,有效缓解了这些挑战。
常用场景
经典使用场景
在计算机视觉与生成式人工智能领域,首尔世界模型数据集为城市级视频世界模拟提供了关键基准。该数据集最经典的应用场景在于训练和评估能够基于真实城市地理信息进行视频生成的模型。研究人员利用其包含的数十万张首尔街景图像、合成城市数据及驾驶视频,构建起连接虚拟生成与物理世界的桥梁,使模型能够依据地理坐标、相机轨迹和文本提示,生成长达数百米、空间一致且动态连贯的城市环境视频。这一场景深刻体现了从纯粹想象环境向真实物理世界仿真的范式转变。
解决学术问题
该数据集有效解决了生成式世界模型长期面临的几个核心学术难题。首先,它通过检索增强的街景图像条件化,攻克了将视频生成锚定在特定真实地理环境中的挑战,确保了生成内容的空间真实性。其次,其设计的跨时间配对策略缓解了参考图像与动态生成场景之间的时间错位问题,促使模型学会区分场景的持久结构与瞬时内容。此外,通过合成数据增强与虚拟前瞻锚点机制,该数据集显著改善了长时程生成中的误差累积与轨迹覆盖有限问题,为构建稳定、可控且可泛化的城市级世界模拟提供了系统性的数据解决方案。
衍生相关工作
首尔世界模型数据集的发布,催生并推动了围绕真实世界接地视频生成的一系列相关研究工作。其核心的检索增强生成、几何与语义参考机制,为后续如UrbanWorld、Streetscapes等城市规模生成模型提供了重要的设计灵感。数据集所强调的跨城市泛化能力(如在釜山、安娜堡的测试),激励了研究社区探索世界模型在未见城市上的零样本适应性问题。同时,其针对长时程生成稳定性提出的虚拟前瞻锚点技术,也与同期在对话头像生成等领域发展的前瞻锚定方法形成了有益的交叉与互鉴,共同促进了生成模型在时序一致性方面的进步。
以上内容由遇见数据集搜集并总结生成


