ImruQays/Quran-Classical-Arabic-English-Parallel-texts
收藏Hugging Face2023-12-29 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/ImruQays/Quran-Classical-Arabic-English-Parallel-texts
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含了《古兰经》的阿拉伯语文本(Imlaei和Uthmanic两种书写方式)以及17种不同的英语翻译版本。这些英语翻译并非《古兰经》本身,而是对《古兰经》文本意义的解释或翻译,旨在向不懂阿拉伯语的人传达其信息。数据集的任务类别为翻译,涉及的语言为阿拉伯语和英语,数据规模在10K到100K之间,使用的许可证为cc-by-nc-4.0。
该数据集包含了《古兰经》的阿拉伯语文本(Imlaei和Uthmanic两种书写方式)以及17种不同的英语翻译版本。这些英语翻译并非《古兰经》本身,而是对《古兰经》文本意义的解释或翻译,旨在向不懂阿拉伯语的人传达其信息。数据集的任务类别为翻译,涉及的语言为阿拉伯语和英语,数据规模在10K到100K之间,使用的许可证为cc-by-nc-4.0。
提供机构:
ImruQays
原始信息汇总
数据集概述
任务类别
- 翻译
语言
- 阿拉伯语
- 英语
数据集规模
- 10K<n<100K
许可
- cc-by-nc-4.0
简介
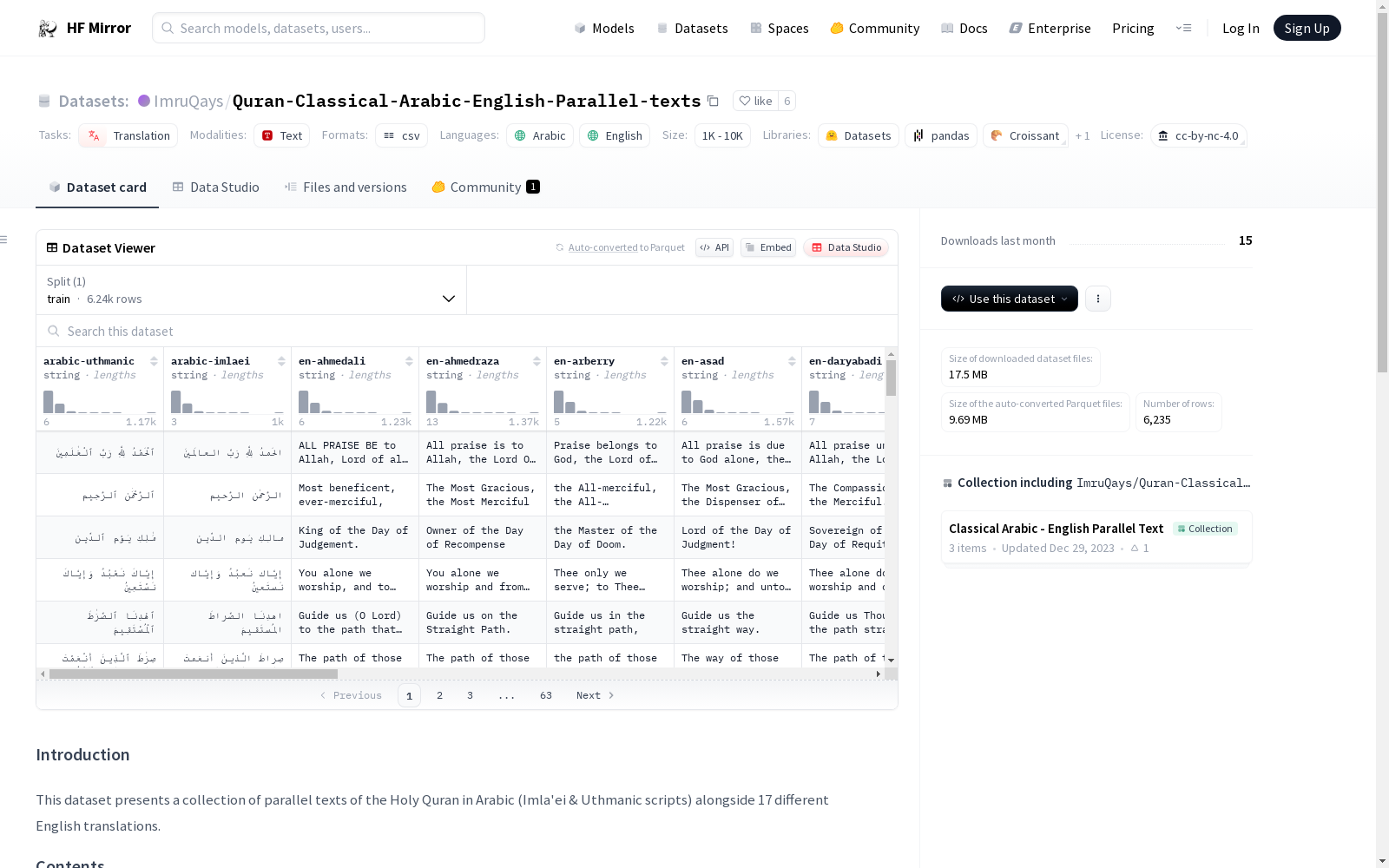
该数据集包含《古兰经》的阿拉伯语(Imlaei & Uthmanic 字体)与17种不同英语翻译的平行文本。
内容
数据集包括古典阿拉伯语的《古兰经》及其以下英语翻译:
- "al-Qur’ân: A Contemporary Translation" by Ahmed Ali
- "Kanz-ul-Iman" by Ahmed Raza Khan
- "The Koran Interpreted" by Arthur John Arberry
- "The Message of The Quran" by Muhammad Asad
- "Quran English Commentary" by Abdul Majid Daryabadi
- "Noble Quran" by Muhammad Muhsin Khan and Muhammad Taqi-ud-Din al-Hilali
- "Clear Quran" by Talal Itani
- "Tafheem ul Quran" by Abul Ala Maududi
- Translation by Safi-ur-Rahman al-Mubarakpuri
- Translation by Mohammed Marmaduke William Pickthall
- Translation by Ali Quli Qarai
- Translation by Hasan al-Fatih Qaribullah and Ahmad Darwish
- "Saheeh International"
- "The Arabic Text and English Translation" by Muhammad Sarwar
- "The Holy Quran" by M. H. Shakir (author disputed)
- Translation by Wahiduddin Khan
- "The Holy Quran: Text, Translation and Commentary" by Abdullah Yusuf Ali
关于英语翻译的说明
英语翻译不视为《古兰经》本身,《古兰经》仅以阿拉伯语存在。这些翻译旨在向不懂阿拉伯语的人传达《古兰经》的信息,提供宝贵见解但不能替代原始阿拉伯语文本,后者在伊斯兰传统中具有独特地位,被视为神的直接话语。
原始编译
该数据集的原始编译由 M-AI-C 完成,似乎源自 Tanzil。
修改
添加了Imlaei字体并移除了tafseers。
搜集汇总
数据集介绍
构建方式
该数据集的构建采取了对《古兰经》这一伊斯兰教核心经典的阿拉伯语原文(包括Imla'ei和Uthmanic两种书写脚本)与17种不同英文翻译的并行文本进行整合的方式。这种构建方式不仅保留了原文的风貌,同时也为非阿拉伯语使用者提供了理解经典的途径。
特点
该数据集的特点在于其丰富的翻译版本,涵盖了多个翻译家的不同翻译风格和解读,从而为研究者提供了全面而深入的文本分析资源。此外,数据集遵循cc-by-nc-4.0版权协议,确保了其内容的开放性和共享性。
使用方法
用户在使用该数据集时,可以依据不同的翻译版本对《古兰经》进行跨语言的研究和比较分析。数据集的并行结构便于进行文本对照,而其开放版权则允许用户在遵守协议的前提下,自由地使用和分享数据集内容。
背景与挑战
背景概述
ImruQays/Quran-Classical-Arabic-English-Parallel-texts数据集是一项涉及宗教文本翻译的重要成果,该数据集汇集了《古兰经》的阿拉伯文本(Imla'ei & Uthmanic脚本)与17种不同的英文翻译版本。它不仅体现了语言的跨文化转换,也映射了宗教文献在不同文化语境中的传播与解读。该数据集的创建旨在为研究者提供丰富的文本资源,以便于进行宗教文本的对比分析、翻译研究以及语言学探索。该数据集由M-AI-C团队原始编译,并可能源自Tanzil项目,其诞生为伊斯兰学研究以及跨文化交流领域带来了新的研究视角和工具。
当前挑战
在数据集构建过程中,研究者面临了如何准确传达《古兰经》文本深层含义的挑战,特别是在不同文化和语言之间架起理解的桥梁。此外,数据集的构建还涉及了技术层面的挑战,如Imla'ei脚本的添加和注释的去除。在研究领域,该数据集的使用者需谨慎对待翻译版本的权威性和准确性问题,因为英文翻译仅为《古兰经》意义的解释或表达,而非《古兰经》本身。这些翻译版本虽提供了宝贵的洞察,但不能替代具有神圣地位的阿拉伯原文。
常用场景
经典使用场景
在当今翻译研究领域,ImruQays/Quran-Classical-Arabic-English-Parallel-texts数据集被广泛运用于经典的使用场景,即作为平行语料库进行机器翻译训练。该数据集包含《古兰经》的阿拉伯文本及其十七种英文翻译版本,为研究者提供了丰富的翻译对齐资源,从而能够有效提升翻译模型的准确性和流畅性。
解决学术问题
该数据集解决了学术研究中对于宗教文献翻译质量评估的难题,为学者提供了基准数据,有助于开展翻译质量对比分析和翻译策略研究。同时,它也为语言学研究中的语义学和语用学领域提供了珍贵的多语言平行文本,促进了跨语言语义对应和语用适应性的深入探讨。
衍生相关工作
基于此数据集,学术界衍生出了众多经典工作,如翻译质量评估模型、跨语言信息检索算法以及多语言自然语言处理工具。这些工作不仅推动了翻译技术的发展,也为相关领域的理论研究提供了实证基础。
以上内容由遇见数据集搜集并总结生成


