amaai-lab/MusicBench
收藏Hugging Face2025-03-20 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/amaai-lab/MusicBench
下载链接
链接失效反馈官方服务:
资源简介:
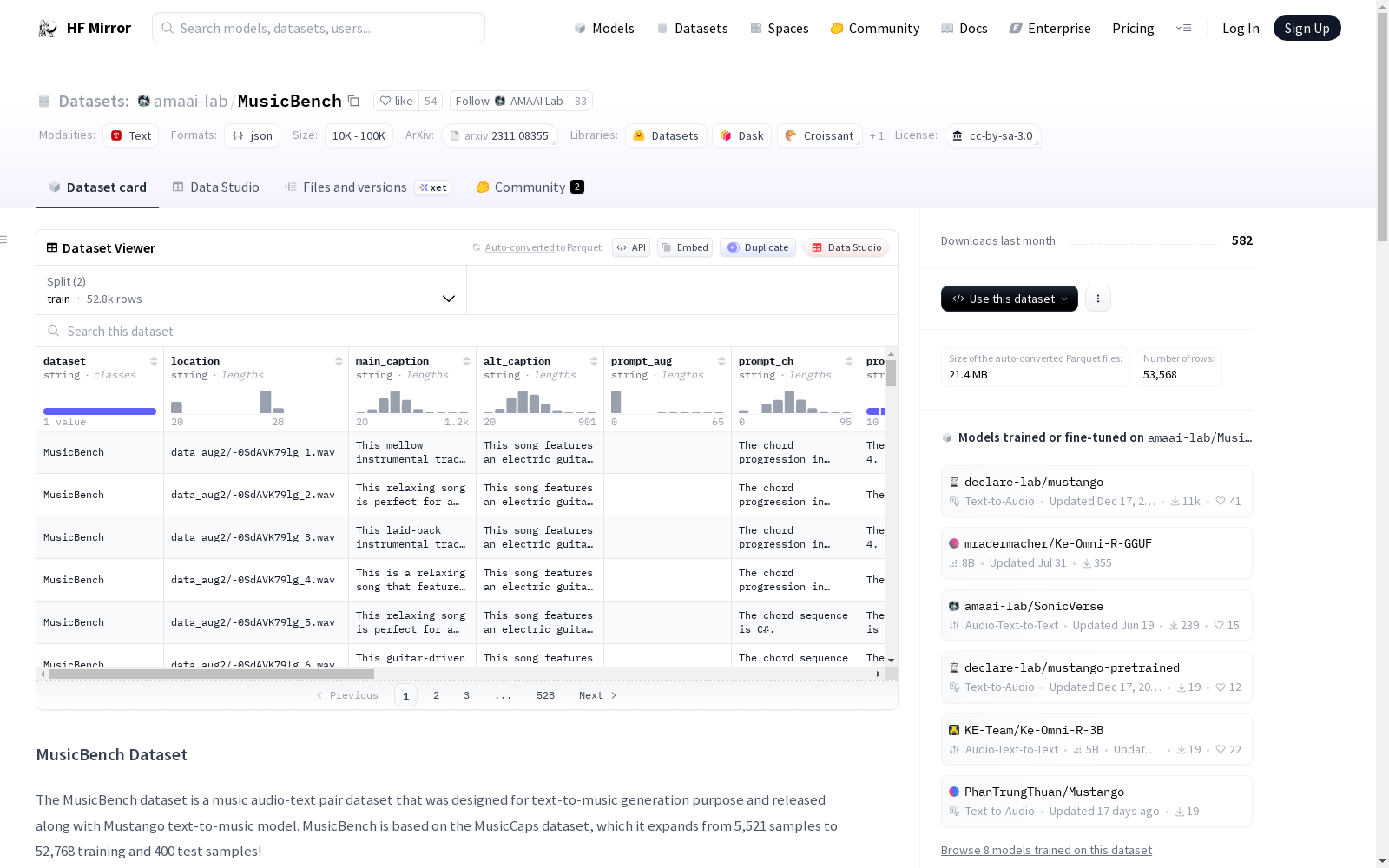
MusicBench数据集是一个音乐音频-文本配对数据集,旨在用于文本到音乐的生成任务。它基于MusicCaps数据集,通过添加音乐特征(如和弦、节拍、速度和调性)并使用文本模板描述这些特征,从而增强了原始文本提示。此外,数据集通过进行音乐上有意义的增强(如半音调音、速度变化和音量变化)扩展了音频样本的数量。训练集包含52,768个样本,测试集包含400个样本。数据集包含3个JSON文件和附带的音频文件(.tar.gz格式)。训练集包含音频增强样本和增强的标题,还提供了ChatGPT重新表述的标题。测试集分为TestA和TestB,TestB包含所有4种可能的控制句子,而TestA则不包含控制句子。FMACaps评估数据集由1000个样本组成,这些样本从Free Music Archive中提取,并通过伪标注生成。大多数样本长度为10秒,部分样本长度在5到10秒之间。数据集包含1000个音频文件和3个JSON文件,JSON文件的结构与MusicBench类似,但所有标题都位于“main_caption”列中。
The MusicBench dataset is a music audio-text paired dataset intended for text-to-music generation tasks. Built upon the MusicCaps dataset, it enhances the original text prompts by adding musical features such as chords, beats, tempo, and tonality, and describing these features using text templates. Additionally, the dataset expands the number of audio samples through music-meaningful augmentations, including semi-tone tuning, tempo variations, and volume changes. The training set contains 52,768 samples, while the test set includes 400 samples. The dataset includes 3 JSON files and accompanying audio files in .tar.gz format. The training set contains audio-augmented samples and enhanced captions, and also provides captions rephrased by ChatGPT. The test set is divided into TestA and TestB: TestB contains all 4 possible control sentences, whereas TestA does not include any control sentences. The FMACaps evaluation dataset consists of 1000 samples extracted from the Free Music Archive and generated via pseudo-annotations. Most samples have a duration of 10 seconds, while some samples range from 5 to 10 seconds in length. This dataset contains 1000 audio files and 3 JSON files. The structure of the JSON files is similar to that of MusicBench, but all captions are located in the "main_caption" column.
提供机构:
amaai-lab
原始信息汇总
MusicBench Dataset 概述
数据集基本信息
- 名称: MusicBench Dataset
- 目的: 用于文本到音乐的生成
- 基础数据集: 基于 MusicCaps 数据集,从 5,521 样本扩展至 52,768 训练样本和 400 测试样本
数据集扩展内容
- 音乐特征提取: 包括和弦、节拍、速度和调性
- 文本描述增强: 使用文本模板描述音乐特征,增强原始文本提示
- 音频样本扩增: 通过半音音高移位、速度变化和音量变化进行音乐意义增强
数据集结构
- 训练集大小: 52,768 样本
- 测试集大小: 400 样本
- 文件格式: 包含 3 个 .json 文件和 .tar.gz 格式的音频文件
训练集详情
- 音频增强样本: 包含
- 增强标题: 包含
- ChatGPT 重述标题: 包含于所有音频样本
测试集详情
- TestA 和 TestB: 音频内容相同,但 TestB 在所有样本的标题中包含所有 4 种可能的控制句子,而 TestA 不包含控制句子
.json 文件结构
- location: 文件解压后的位置
- main_caption: 增强后的文本提示(TestB 包含控制句子,训练集包含 ChatGPT 重述标题)
- alt_caption: TestB 中不包含任何控制句子的标题
- prompt_aug: 与音量变化增强相关的控制句子
- prompt_ch: 描述和弦序列的控制句子
- prompt_bt: 描述节拍计数的控制句子
- prompt_bpm: 描述速度的控制句子
- prompt_key: 与提取的音乐调性相关的控制句子
- beats: 节拍和强拍时间戳
- bpm: 速度特征,以数字形式保存
- chords: 音轨中的和弦序列
- chords_time: 检测到的和弦时间戳
- key: 检测到的调性的根和类型
- keyprob: 检测到的调性的置信度分数
- is_audioset_eval_mcaps: 样本是否属于 Audioset (MusicCaps) 评估集
FMACaps 评估数据集
- 数据来源: 从 Free Music Archive (FMA) 提取的 1000 样本
- 数据大小: 1,000 样本
- 采样率: 16 kHz
- 文件包含: 1000 个音频文件和 3 个 .json 文件,分别包含不同控制句子的标题
数据集使用
- 训练 Mustango 模型: 使用 beats、chords 和 chords_time 作为输入
- 控制性评估: 使用 FMACaps_B 文件进行 Mustango 的控制性评估
- 音频质量客观评估: 使用 FMACaps_C 文件进行 Mustango 的音频质量客观评估
搜集汇总
数据集介绍
构建方式
在音乐信息检索领域,高质量音频-文本配对数据对于文本到音乐生成任务至关重要。MusicBench数据集以MusicCaps为基础,通过系统化扩展构建而成。其构建过程首先从原始音频中提取和弦、节拍、速度和调性等音乐特征,并利用文本模板将这些特征转化为结构化描述,从而增强原始文本提示。随后,通过音高移位、速度变化和音量调整等音乐性增强手段,对音频样本进行有意义的数据扩充,最终将样本规模从5,521个扩展至52,768个训练样本和400个测试样本,显著提升了数据多样性和覆盖范围。
特点
该数据集的核心特征体现在其多层次的结构化设计。它不仅提供增强后的文本描述,还包含ChatGPT重新表述的标题,丰富了语言表达的多样性。测试集分为TestA和TestB两个版本,前者不含控制语句,后者则包含全部四种音乐特征的控制语句,便于进行可控性评估。数据集中的每个样本均附有详细的音乐特征标注,包括和弦序列、节拍时间戳、速度数值和调性信息,这些结构化数据为模型训练提供了丰富的监督信号。此外,数据集还附带FMACaps评估集,包含从自由音乐档案馆提取的1,000个样本,进一步扩展了评估场景。
使用方法
在应用层面,MusicBench数据集主要用于训练和评估文本到音乐生成模型,如Mustango。研究人员可依据训练集中的音频增强样本和增强标题进行模型训练,利用提供的和弦、节拍等特征作为条件输入,以实现对生成音乐的结构化控制。评估时,可分别使用TestA和TestB测试集,前者用于评估基本生成质量,后者则用于测试模型对特定音乐特征的响应能力。FMACaps评估集提供了不同控制语句配置的标题,支持对生成音频质量和可控性的客观评估。数据集以JSON格式组织,配合压缩的音频文件,便于直接加载和处理。
背景与挑战
背景概述
在人工智能与音乐信息检索的交叉领域,文本到音乐生成技术正成为研究热点。MusicBench数据集由AMAAI实验室于2024年伴随Mustango模型发布,其核心研究问题在于解决音乐生成任务中音频与文本对齐的精确性与可控性。该数据集基于MusicCaps构建,通过引入和弦、节拍、速度及调性等多维度音乐特征,并利用文本模板增强描述,将样本规模扩展至52,768个训练样本与400个测试样本,显著提升了生成音乐的结构丰富度与语义连贯性,为可控音乐合成研究提供了关键数据支撑。
当前挑战
MusicBench数据集旨在应对文本到音乐生成中音乐结构控制的根本挑战,即如何将抽象文本指令转化为具备特定和弦、节奏与调性的复杂音频信号。构建过程中的挑战包括:从原始音频中高精度提取多层次音乐特征(如和弦序列与节拍时间戳),确保特征与文本描述的一致性;通过音高偏移、速度变化等数据增强手段扩展样本时,需维持音乐语义的完整性;此外,利用ChatGPT重构文本提示时,需平衡自然语言表达与音乐术语的准确性,以构建高质量、可泛化的音频-文本对。
常用场景
经典使用场景
在音乐信息检索与生成领域,MusicBench数据集以其丰富的音乐音频-文本配对结构,为文本到音乐生成任务提供了标准化的训练与评估基准。该数据集通过整合和弦、节拍、速度及调性等音乐特征,并采用文本模板进行描述,极大地增强了原始文本提示的语义丰富度。研究者通常利用其52,768个训练样本和400个测试样本,构建端到端的生成模型,以探索自然语言描述与音乐音频之间的复杂映射关系,推动可控音乐生成技术的发展。
衍生相关工作
MusicBench数据集催生了多项重要的衍生研究,其中最突出的成果是Mustango文本到音乐生成模型,该模型利用数据集中的音乐特征控制语句实现了高可控性的音乐合成。后续工作进一步探索了基于该数据集的跨模态表示学习、音乐风格迁移及自动编曲等方向。例如,研究者借助其丰富的标注信息开发了音乐结构分析算法,并在音乐情感识别、自动伴奏生成等任务中取得了显著进展,持续拓展了音乐人工智能的应用边界。
数据集最近研究
最新研究方向
在音乐信息检索与生成领域,MusicBench数据集作为MusicCaps的扩展,正推动文本到音乐生成的前沿探索。该数据集通过整合和弦、节拍、速度及调性等结构化音乐特征,并利用文本模板增强描述,为可控音乐生成模型如Mustango提供了关键训练基础。当前研究聚焦于多模态音乐表征学习,旨在提升模型对音乐语义与风格的控制能力,同时结合ChatGPT重述的文本提示,探索生成音乐的多样性与创造性。此外,伴随发布的FMACaps评估数据集进一步促进了生成模型在可控性与音频质量方面的客观评测,为音乐人工智能的实用化发展注入了新动力。
以上内容由遇见数据集搜集并总结生成


