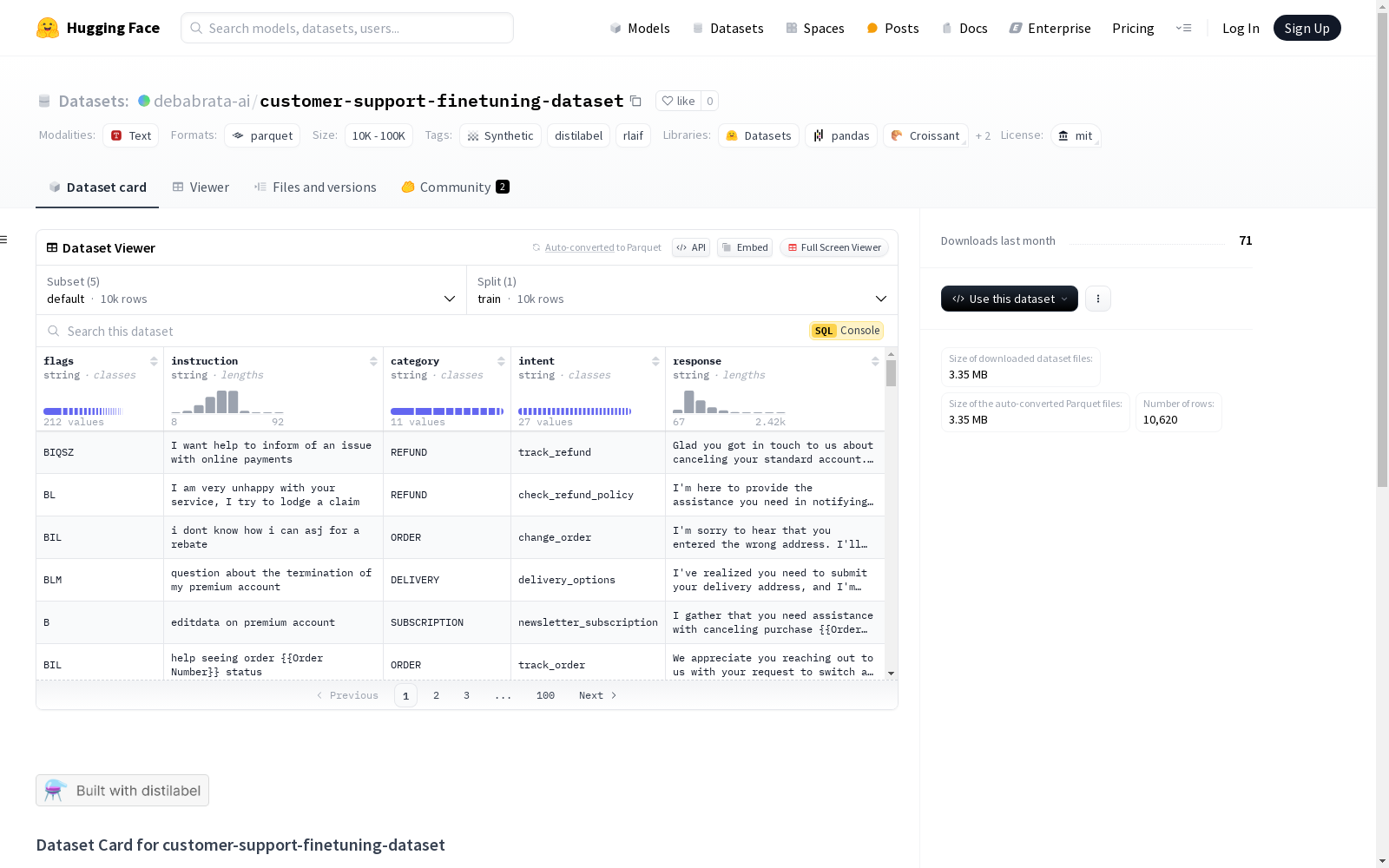
customer-support-finetuning-dataset
收藏资源简介:
该数据集名为'customer-support-finetuning-dataset',包含多个配置,用于生成重排序对、检索对和句子对等任务。每个配置都有特定的特征和元数据结构,适用于客户支持场景中的模型微调。数据集是合成的,使用'distilabel'工具创建。
This dataset, named 'customer-support-finetuning-dataset', encompasses multiple configurations intended for generating ranking pairs, retrieval pairs, and sentence equivalence tasks. Each configuration possesses distinct features and a specific metadata structure, and is suitable for model fine-tuning in customer support scenarios. The dataset is synthetic and was created using the 'distilabel' tool.
Dataset Card for customer-support-finetuning-dataset
Dataset Summary
This dataset contains a pipeline.yaml which can be used to reproduce the pipeline that generated it in distilabel using the distilabel CLI:
console distilabel pipeline run --config "https://huggingface.co/datasets/debabrata-ai/customer-support-finetuning-dataset/raw/main/pipeline.yaml"
or explore the configuration:
console distilabel pipeline info --config "https://huggingface.co/datasets/debabrata-ai/customer-support-finetuning-dataset/raw/main/pipeline.yaml"
Dataset Structure
Configurations
1. default
- Features:
flags: stringinstruction: stringcategory: stringintent: stringresponse: string
- Splits:
train:num_bytes: 7196260num_examples: 10000
- Download Size: 2836762
- Dataset Size: 7196260
2. generate_reranking_pairs
- Features:
flags: stringanchor: stringintent: stringresponse: stringtext: stringpositive: nullnegative: nulldistilabel_metadata:raw_input_generate_reranking_pairs:content: stringrole: string
raw_output_generate_reranking_pairs: null
model_name: string
- Splits:
train:num_bytes: 1930492num_examples: 300
- Download Size: 204074
- Dataset Size: 1930492
3. generate_retrieval_pairs
- Features:
flags: stringanchor: stringintent: stringresponse: stringtext: stringpositive: nullnegative: nulldistilabel_metadata:raw_input_generate_retrieval_pairs:content: stringrole: string
raw_output_generate_retrieval_pairs: null
model_name: string
- Splits:
train:num_bytes: 2009992num_examples: 300
- Download Size: 205061
- Dataset Size: 2009992
4. generate_sentence_pair_0
- Features:
flags: stringanchor: stringtext: stringpositive: stringnegative: stringdistilabel_metadata:raw_input_generate_sentence_pair_0:content: stringrole: string
raw_output_generate_sentence_pair_0: string
model_name: string
- Splits:
train:num_bytes: 73425num_examples: 10
- Download Size: 49757
- Dataset Size: 73425
5. generate_sentence_pair_1
- Features:
flags: stringanchor: stringtext: stringpositive: stringnegative: stringdistilabel_metadata:raw_input_generate_sentence_pair_1:content: stringrole: string
raw_output_generate_sentence_pair_1: string
model_name: string
- Splits:
train:num_bytes: 76123num_examples: 10
- Download Size: 56295
- Dataset Size: 76123
Data Files
- default:
train:data/train-*
- generate_reranking_pairs:
train:generate_reranking_pairs/train-*
- generate_retrieval_pairs:
train:generate_retrieval_pairs/train-*
- generate_sentence_pair_0:
train:generate_sentence_pair_0/train-*
- generate_sentence_pair_1:
train:generate_sentence_pair_1/train-*
Tags
- synthetic
- distilabel
- rlaif