HATIE
收藏arXiv2025-05-01 更新2025-05-03 收录
下载链接:
https://github.com/SuhoRyu/HATIE
下载链接
链接失效反馈官方服务:
资源简介:
HATIE是一个大规模的文本引导图像编辑基准数据集,旨在解决当前图像编辑模型评估缺乏标准化方法的难题。该数据集基于GQA数据集,包含18,226张图像和19,933个可编辑对象,覆盖76个COCO类别。HATIE提供了丰富的编辑查询,包括对象添加、移除、替换、属性更改和背景风格变化等,并采用自动化和多方面的评估指标,如图像质量、对象保真度、背景保真度、对象一致性和背景一致性等,以与人类感知相一致。HATIE的创建为文本引导图像编辑领域的研究提供了可靠、客观和易于复现的评估方法。
HATIE is a large-scale text-guided image editing benchmark dataset developed to address the pressing challenge of lacking standardized evaluation methodologies for contemporary image editing models. Built upon the GQA dataset, HATIE comprises 18,226 images and 19,933 editable objects, covering 76 COCO categories. HATIE offers a wide range of editing queries, including object addition, removal, replacement, attribute modification, background style alteration, and more. It employs automated and multi-faceted evaluation metrics such as image quality, object fidelity, background fidelity, object consistency, and background consistency to align with human perceptual preferences. The creation of HATIE provides a reliable, objective, and readily reproducible evaluation framework for research in the field of text-guided image editing.
提供机构:
首尔国立大学数据科学研究生院
创建时间:
2025-05-01
原始信息汇总
HATIE数据集概述
基本信息
- 数据集名称: HATIE (Human-aligned Benchmark for Text-guided Image Editing)
- 发布会议: CVPR 25 Highlight
- GitHub地址: https://github.com/SuhoRyu/HATIE
- arXiv论文: https://arxiv.org/abs/2505.00502
研究团队
- 主要作者:
- Suho Ryu
- Kihyun Kim
- Eugene Baek
- Dongsoo Shin
- Joonseok Lee (VIPLab, Seoul National University)
数据集特点
- 研究领域: 文本引导的图像编辑
- 目标: 建立可扩展的人类对齐基准
当前状态
- 代码和数据集: 即将发布
搜集汇总
数据集介绍
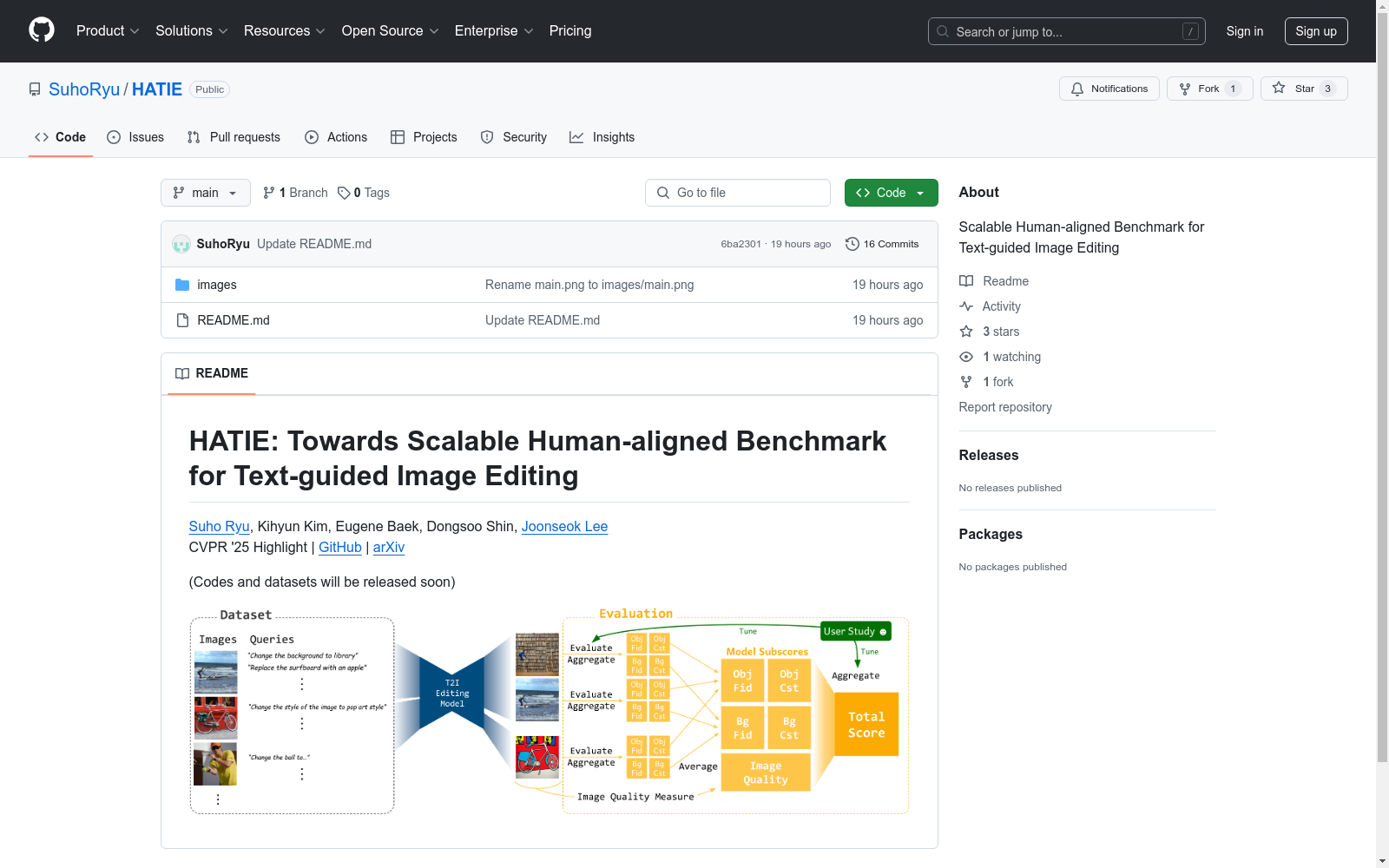
构建方式
HATIE数据集的构建基于GQA数据集,通过精细的数据过滤和增强流程确保数据质量。首先,筛选出尺寸适中、未被遮挡且完整的对象,确保编辑任务的可行性。随后,利用实例分割模型验证对象的可检测性,仅保留检测置信度高于阈值的样本。最终数据集包含18,226张图像,涵盖76个COCO类别,每张图像均经过512×512的统一尺寸处理,以保证模型输入的兼容性。编辑查询通过统计分析和LLM生成,确保多样性与合理性,共生成49,840条编辑指令,覆盖对象增删改、属性调整及背景风格变换等任务。
特点
HATIE的核心特点在于其多维度的评估体系与人类感知对齐的设计理念。数据集涵盖6类对象中心编辑和2类非对象中心编辑任务,通过5项评估指标(图像质量、对象/背景保真度、对象/背景一致性)全面量化模型性能。其创新性体现在:1) 采用CLIP、LPIPS等多模型融合评分策略,避免单一指标偏差;2) 通过用户研究校准指标权重,使自动化评估与人类评判的Pearson相关系数达0.8以上;3) 提供细粒度的任务分类评估,支持对模型优缺点的定向分析。数据分布的均衡性(76类对象、27种背景、10种风格)进一步保障了评估的公正性。
使用方法
使用HATIE需遵循其模块化评估流程。首先加载待测模型,输入原始图像和编辑指令生成结果。评估阶段自动执行:1) 图像质量检测(FID指标);2) 对象级分析(通过实例分割提取目标区域,计算CLIP对齐度与检测置信度);3) 背景一致性验证(LPIPS/DINO特征比对)。用户可选择整体评分或特定维度分析,如单独考察OBJECT_ADDITION任务中的位置准确性。数据集提供标准化的JSON格式标注,包含对象边界框、属性及场景图信息,支持快速集成到现有评估管道。对于研究新型编辑模型,建议同时测试不同超参数组合,利用HATIE的敏感性分析功能寻找最优配置。
背景与挑战
背景概述
HATIE(Human-Aligned benchmark for Text-guided Image Editing)是由首尔国立大学数据科学研究生院的Suho Ryu、Kihyun Kim、Eugene Baek、Dongsoo Shin和Joonseok Lee等人于2025年提出的一个大规模文本引导图像编辑基准数据集。该数据集的提出背景源于近年来基于扩散模型的图像生成技术的快速发展,如Imagic、Prompt-toPrompt和SDEdit等模型的涌现,这些模型在文本引导图像编辑任务上取得了显著进展。然而,由于图像编辑任务的主观性和多样性,缺乏一个广泛接受的标准化评估方法,研究者们往往依赖于人工用户研究,这限制了评估的规模和可重复性。HATIE的创建旨在解决这一问题,通过提供一个覆盖广泛编辑任务的大规模基准集,并结合全自动、多角度的评估流程,以实现可靠、客观且与人类感知一致的模型评估。HATIE的推出为文本引导图像编辑领域的研究提供了重要的评估工具,推动了该领域的进一步发展。
当前挑战
HATIE数据集面临的挑战主要包括两个方面:领域问题的挑战和构建过程中的挑战。在领域问题方面,文本引导图像编辑任务本身具有高度主观性,同一编辑指令可能对应多个合理的输出结果,这使得客观评估变得困难。例如,"在客厅场景中添加一张桌子"的指令可以通过多种形状和风格的桌子实现,而像素级的细节更是无限多样。此外,编辑任务需要同时满足多个方面的要求,如编辑后的图像应真实可行、正确反映指令要求的变化,同时不改变未指定的部分,这种多面性增加了评估的复杂性。在构建过程中,HATIE团队面临如何自动化生成大量真实可行的编辑查询、如何设计全面且与人类感知一致的评估指标等挑战。例如,为确保查询的可行性,需要统计分析对象间的空间关系和属性分布;为对齐人类感知,需通过用户研究校准多个评估指标的权重组合。这些挑战使得构建一个全面、可靠的评估基准变得尤为复杂。
常用场景
经典使用场景
在文本引导的图像编辑领域,HATIE数据集被广泛用于评估和比较不同编辑模型的性能。其经典使用场景包括对象添加、对象替换、对象属性修改、背景更改和风格转换等多种编辑任务。通过提供大规模、多样化的编辑查询和自动化评估流程,HATIE能够全面测试模型在各种复杂场景下的表现,从而为研究人员提供可靠的性能基准。
实际应用
HATIE数据集在实际应用中具有广泛的潜力。例如,在广告设计和内容创作中,它可以用于测试和优化图像编辑工具,确保生成的图像既符合用户需求又保持高质量。此外,在虚拟现实和增强现实领域,HATIE的评估框架可以帮助开发者验证图像编辑算法的真实感和一致性。其自动化评估能力还使其成为工业界快速迭代和优化模型的有力工具。
衍生相关工作
HATIE数据集衍生了许多相关研究和工作。例如,基于HATIE的评估框架,研究人员开发了多种改进的文本引导图像编辑模型,如MagicBrush和InstructPix2Pix。此外,HATIE的自动化评估方法也被其他领域借鉴,用于开发类似的基准测试工具。其多指标评估思想还启发了后续研究,推动了图像编辑领域评估标准的进一步发展。
以上内容由遇见数据集搜集并总结生成


