OpenGVLab/MM-NIAH
收藏Hugging Face2024-06-17 更新2024-06-15 收录
下载链接:
https://hf-mirror.com/datasets/OpenGVLab/MM-NIAH
下载链接
链接失效反馈官方服务:
资源简介:
Needle In A Multimodal Haystack (MM-NIAH) 是一个综合基准,旨在系统评估现有多模态大语言模型(MLLMs)在理解长多模态文档方面的能力。该基准要求模型根据散布在多模态文档中的关键信息回答特定问题。MM-NIAH的评估数据包含三个任务:检索、计数和推理。关键信息(称为needles)被插入到文档的文本或图像中,插入到文本中的称为文本needles,插入到图像中的称为图像needles。实验结果表明,现有的MLLMs在处理图像关键信息时表现不佳。
Needle In A Multimodal Haystack (MM-NIAH) is a comprehensive benchmark designed to systematically evaluate the capabilities of existing multimodal large language models (MLLMs) in understanding long multimodal documents. This benchmark requires models to answer specific questions based on key information scattered across the multimodal documents. The MM-NIAH benchmark encompasses three evaluation tasks: retrieval, counting, and reasoning. Key information, dubbed "needles", is inserted into either the textual or visual content of the documents; those inserted into text are termed textual needles, while those inserted into images are called visual needles. Experimental results demonstrate that existing MLLMs perform poorly when handling key information embedded in images.
提供机构:
OpenGVLab
原始信息汇总
数据集概述
基本信息
- 许可证:MIT
- 任务类别:问答
- 语言:英语
- 数据量:10K<n<100K
配置详情
- 配置名称:val
- 数据文件:
- 分割:val
- 路径:mm_niah_val/annotations/reasoning-text.jsonl
- 分割:test
- 路径:mm_niah_test/annotations/reasoning-text.jsonl
- 分割:val
数据集介绍
- 名称:Needle In A Multimodal Haystack (MM-NIAH)
- 目的:评估现有多模态大型语言模型(MLLMs)理解长多模态文档的能力。
- 任务类型:包含三个任务,分别是
检索、计数和推理。 - 数据结构:文档中插入的“针”可以是文本或图像,分别称为
文本针和图像针。
主要发现
- 最先进的MLLMs(如Gemini-1.5)在理解多模态文档方面仍有困难。
- 所有MLLMs在图像针上的表现都很差。
- MLLMs无法准确识别文档中图像的数量。
- 在图像-文本交错数据上预训练的模型并未表现出更好的性能。
- 在背景文档上训练并不能提高MM-NIAH上的表现。
- MLLMs中也存在“中间迷失”问题。
- LLMs的长上下文能力并未在MLLMs中保留。
- RAG提高了文本针检索的性能,但未提高图像针检索的性能。
- 将问题置于上下文之前并不能提高模型性能。
- 人类在MM-NIAH上的表现接近完美。
实验结果
- 评估指标:
- 检索和推理任务:使用准确性(Accuracy)作为评估指标。
- 计数任务:使用软准确性(Soft Accuracy),定义为$frac{1}{N} sum_{i=1}^{N} frac{m_i}{M_i}$,其中$m_i$是预测列表与真实列表在相应位置匹配的元素数量,$M_i$是真实列表中第$i$个样本的元素数量。
评估方法
- 计算分数:
- 准备模型响应的jsonl格式文件,然后执行脚本
calculate_scores.py以获取热图和分数。 - 示例命令:
python calculate_scores.py --outputs-dir /path/to/your/responses
- 准备模型响应的jsonl格式文件,然后执行脚本
数据格式
- 数据结构:
- id:从0开始的整数,每个任务类型有独立的ID。
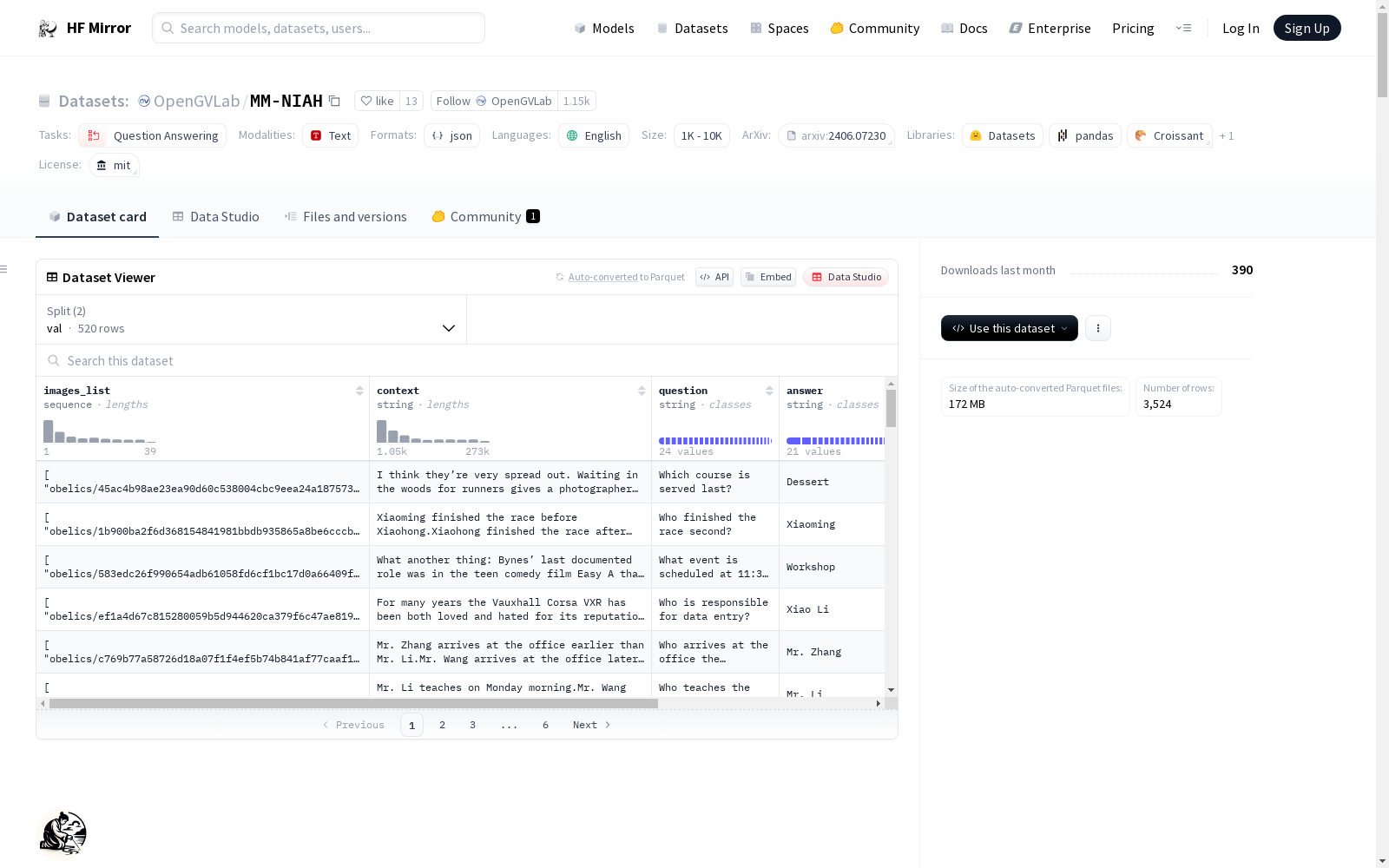
- images_list:包含N个元素的列表,每个元素是图像的相对路径。
- context:多模态文档,使用
<image>作为图像占位符。 - question:问题。
- answer:标准答案,可以是字符串、整数或列表。
- meta:记录各种统计信息,包括放置深度、上下文长度、文本和图像令牌数量、图像数量、插入的针、候选文本和图像答案等。
注意事项
- 注意1:上下文和问题中的
<image>数量等于images_list的长度。 - 注意2:保存为jsonl文件,每行是一个字典。
搜集汇总
数据集介绍
构建方式
OpenGVLab/MM-NIAH数据集的构建,旨在系统性地评估现有大型多模态语言模型(MLLMs)对长篇多模态文档的理解能力。该数据集通过在文档中的文本或图像中嵌入关键信息(称为'针'),要求模型根据文档中散布的关键信息回答具体问题,从而形成了一个包含三种任务类型——检索、计数和推理——的评测基准。
特点
MM-NIAH数据集的特点在于其综合性和系统性,它不仅涵盖了文本信息,还包括了图像信息,形成了一个多模态的挑战环境。数据集中的'针'可以是文本形式的,也可以是图像形式的,分别称为文本针和图像针。此外,该数据集揭示了当前最先进MLLMs在理解多模态文档方面的不足,特别是在处理图像针时表现出的性能低下。
使用方法
使用MM-NIAH数据集,研究者需要准备模型响应的jsonl格式文件,然后使用提供的脚本计算模型在各项任务上的得分。提交至排行榜的结果应按照规定的文件组织结构,并通过指定邮箱提交。此外,数据集还提供了可视化工具和详尽的文档,以便研究者更好地理解和利用这一资源。
背景与挑战
背景概述
OpenGVLab/MM-NIAH数据集,于2024年6月发布,是由OpenGVLab团队精心设计的一种全面评估现有大型多模态语言模型(MLLMs)对长篇多模态文档理解能力的基准。该数据集的核心研究问题在于如何使MLLMs能够根据散布在多模态文档中的关键信息回答具体问题。MM-NIAH的评估数据包含三种任务:检索、计数和推理,其难点在于针(needle)被插入到文档的文本或图像中,对模型的理解能力提出了挑战。该数据集的发布对相关领域产生了重要影响,为MMLMs的研究与评估提供了新的视角和工具。
当前挑战
MM-NIAH数据集在构建和评估过程中面临的挑战主要包括:1) 所解决的领域问题是大型多模态语言模型在理解长篇多模态文档方面的能力不足,特别是对图像针的识别能力差;2) 构建过程中的挑战包括如何确保文档中的文本和图像针信息分布合理,以及如何评价模型在长篇多模态文档中的表现。实验结果表明,即使是先进的MLLMs,在理解长篇多模态文档方面也存在困难,尤其是在图像针的检索和计数任务上表现不佳。
常用场景
经典使用场景
在探索多模态文档理解领域,OpenGVLab/MM-NIAH数据集提供了一个独特的视角,其经典使用场景在于评估大型语言模型(LLMs)对于长篇多模态文档的综合理解能力。数据集通过插入被称为'针'的信息(文本或图像),要求模型根据文档中的关键信息回答特定问题,从而检验模型在检索、计数和推理任务上的表现。
实际应用
实际应用中,MM-NIAH数据集可被用于改进多模态搜索系统,提升智能问答系统的准确性,尤其是在处理含有丰富图像和文本信息的文档时。它为开发能够处理复杂多模态信息的应用提供了重要的基准。
衍生相关工作
MM-NIAH数据集的发布激发了后续一系列研究工作,如对现有模型的改进,针对特定任务的定制化模型设计,以及多模态学习理论的发展。这些衍生工作进一步拓宽了多模态文档理解的研究领域,为构建更高效的多模态智能系统奠定了基础。
以上内容由遇见数据集搜集并总结生成


