v3xlrm1nOwo1/AnimeQuotes
收藏Hugging Face2024-02-21 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/v3xlrm1nOwo1/AnimeQuotes
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含来自各种动漫系列的鼓舞人心和令人难忘的名言,数据格式为字典列表,每个条目包含名言、角色和来源URL。数据集适用于文本生成、文本到文本生成和文本分类任务,主要语言为日语。
This dataset contains inspiring and memorable quotes sourced from various anime series. It is structured as a list of dictionaries, with each entry including the quote, the associated character, and the source URL. The dataset is applicable to text generation, text-to-text generation, and text classification tasks, and its primary language is Japanese.
提供机构:
v3xlrm1nOwo1
原始信息汇总
Anime Quotes Dataset ― アニメの名言データセット🎐
概述
该数据集包含从Anime Motivation网站收集的各种动漫系列中的精选鼓舞人心和难忘的语录。语录以字典列表的形式存储,便于访问进行分析、研究或个人欣赏。
数据格式
每个条目在数据集中由一个字典表示,包含以下字段:
Quote: 语录文本。Character: 说出语录的角色名称。URL: 语录的来源URL。
使用方法
python import datasets
加载数据集
dataset = datasets.load_dataset(v3xlrm1nOwo1/AnimeQuotes)
print(dataset)
输出示例: python DatasetDict({ train: Dataset({ features: [Quote, Character, URL], num_rows: 10388 }) })
贡献
我们欢迎贡献和反馈,以使Anime Quotes Dataset更加出色!无论是添加新语录、增强现有语录,还是提供宝贵反馈,您的意见都非常受重视。
致谢
特别感谢Anime Motivation为该数据集提供的灵感和语录。
许可证
该数据集在Apache License 2.0下提供,您可以自由使用、修改和分享。
搜集汇总
数据集介绍
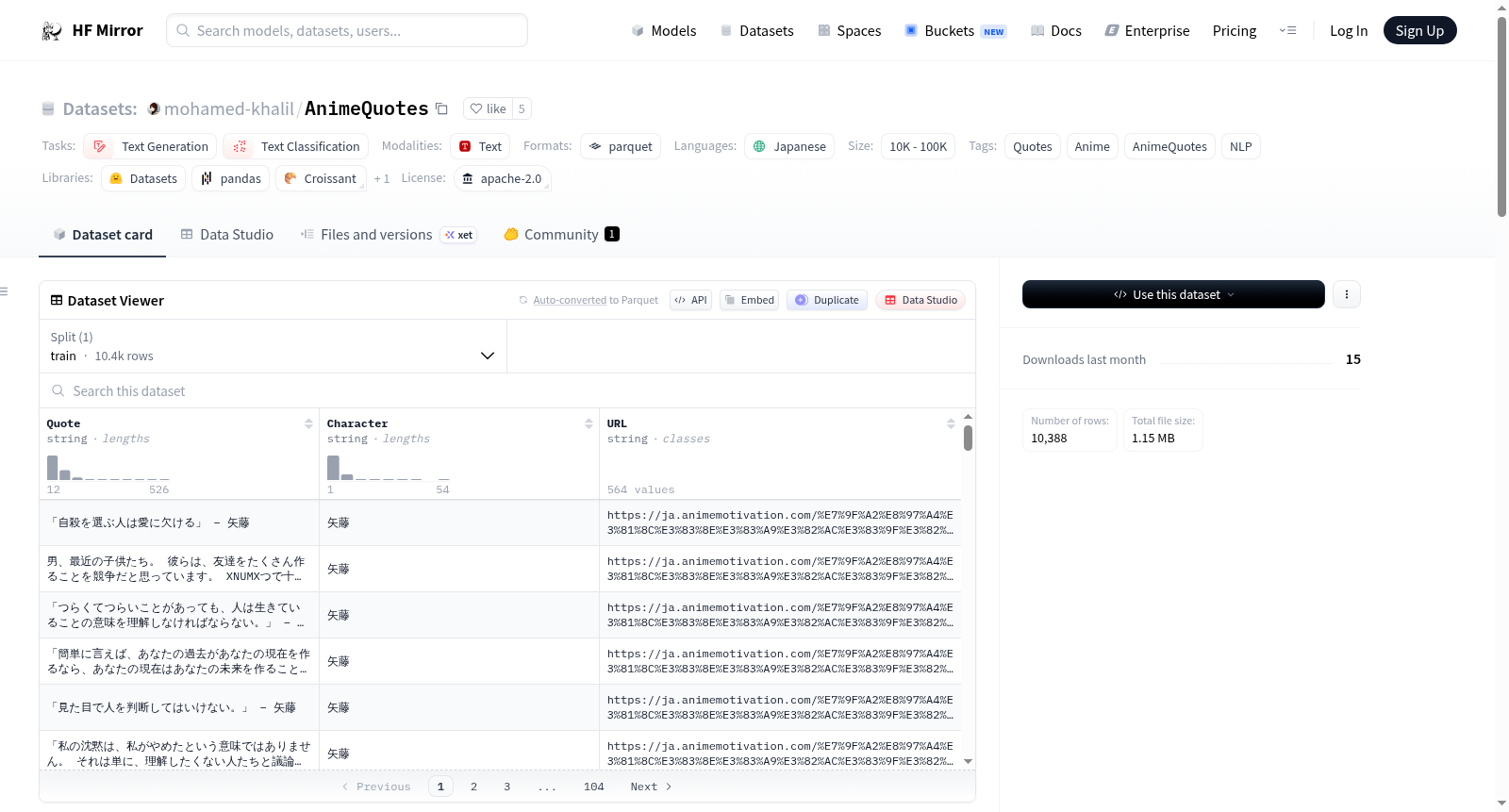
构建方式
在动漫文化研究领域,构建高质量的语言资源对于文本生成与情感分析至关重要。AnimeQuotes数据集通过系统化采集流程,从知名动漫激励网站Anime Motivation中提取了超过一万条经典语录。每条数据均以结构化字典形式保存,包含引文原文、角色名称及来源链接,确保了数据的完整性与可追溯性。这种基于权威来源的构建方式,为后续的学术研究提供了坚实的语料基础。
特点
该数据集在动漫文本资源中展现出鲜明的专业特性。其收录的日文原版语录覆盖了多元动漫作品,每条记录均标注了明确的角色归属与原始出处,形成了层次分明的语义结构。数据规模介于一千至一万条之间,既保证了样本的丰富性,又维持了内容的精炼度。这种兼顾广度与深度的特征设计,使其特别适用于跨作品的语言风格分析与角色话语模式研究。
使用方法
在自然语言处理实践中,该数据集可通过HuggingFace生态便捷调用。研究者使用datasets库加载后,可直接获得包含万余条训练样本的结构化数据,每条记录均具备引文、角色、链接三个特征维度。这种即装即用的特性支持文本生成模型的微调训练,也为语录分类、角色话语分析等下游任务提供了标准化的数据接口,显著降低了动漫文本研究的工程门槛。
背景与挑战
背景概述
在自然语言处理领域,针对特定文化内容的文本资源构建日益受到重视。AnimeQuotes数据集由独立研究者v3xlrm1nOwo1于近期创建,其核心研究问题聚焦于日本动漫领域的名言文本收集与结构化。该数据集从Anime Motivation网站系统采集了逾万条动漫角色经典台词,涵盖了角色、原文及出处链接等多维信息。作为面向文本生成、文本转换及文本分类任务的专项语料,它不仅为动漫文化计算提供了基础数据支撑,亦为跨语言情感分析、角色对话建模等研究方向开辟了新的探索路径。
当前挑战
该数据集旨在应对动漫文本生成与语义理解中的独特挑战:动漫台词常蕴含高度语境化情感、文化隐喻及角色特定表达风格,这对模型的深层语义捕捉能力提出了严峻考验。在构建过程中,研究者面临数据源异构性整合的难题,需从非结构化网页中精准提取并清洗台词文本,同时确保角色归属与原始语境的对应关系。此外,日语特有的敬语体系、口语化表达以及动漫专属词汇的规范化标注,亦构成了数据质量保障的技术壁垒。
常用场景
经典使用场景
在自然语言处理领域,AnimeQuotes数据集为文本生成任务提供了丰富的语料资源。该数据集收录了来自日本动画的经典台词,涵盖了多样化的角色与语境,使得研究者能够基于这些富有情感和哲理的文本,训练生成模型以模仿动画角色的语言风格。通过分析台词中的情感倾向和叙事结构,该数据集在创意写作和对话系统开发中展现出独特价值,为生成具有文化特色的文本内容奠定了数据基础。
衍生相关工作
围绕该数据集衍生的经典工作主要集中在文本生成与角色分析领域。部分研究利用该数据集训练生成了具有动画风格的对话模型,探索了角色一致性在长文本生成中的保持方法。另有学者结合角色属性与台词情感特征,构建了动画角色人格计算模型,为虚拟角色智能体开发提供了理论框架。这些工作进一步拓展了流行文化文本在计算语言学中的应用边界。
数据集最近研究
最新研究方向
在自然语言处理领域,动漫文本数据因其独特的文化内涵和情感表达,逐渐成为情感计算与文本生成研究的热点素材。AnimeQuotes数据集汇集了丰富的动漫名言,为探索角色对话生成、情感分析及跨语言文化传播提供了宝贵资源。当前研究聚焦于利用该数据集训练生成式模型,以模拟动漫角色的语言风格,同时结合文本分类技术深入挖掘名言背后的情感倾向与主题特征。随着全球动漫文化的持续升温,此类数据集在推动个性化内容推荐、虚拟角色交互系统等前沿应用方面展现出深远影响,为人工智能理解人类情感与文化多样性开辟了新的路径。
以上内容由遇见数据集搜集并总结生成


