HC4: Healthcare Comprehensive Commons Corpus
收藏arXiv2025-10-21 更新2025-10-23 收录
下载链接:
https://huggingface.co/datasets/m42-health/HC4
下载链接
链接失效反馈官方服务:
资源简介:
HC4是一个超过890亿tokens的新的、广泛校对的前训练数据集,专为医疗保健应用设计。它的创建涉及一个精心设计的从数据收集到预处理的流程,强调数据质量、多样性的来源(包括科学期刊、医学档案、教科书和临床指南)以及严格的文档级别的去重技术。HC4为社区提供了一个大规模的、公开可用的资源,它不仅是一个重大的贡献,还为我们所提出的偏见分析框架提供了一个关键的测试对象。数据集旨在支持医疗保健领域语言模型的公平性和安全性,并解决因数据偏差可能导致的不公平结果问题。
HC4 is a novel, extensively curated pre-training dataset with over 89 billion tokens, specifically tailored for healthcare applications. Its development involved a meticulously designed pipeline spanning from data collection to preprocessing, with emphasis on data quality, diverse source domains including scientific journals, medical archives, textbooks, and clinical guidelines, as well as strict document-level deduplication techniques. HC4 provides the research community with a large-scale, publicly accessible resource. It not only represents a significant academic contribution but also serves as a critical testbed for the bias analysis framework we propose. This dataset aims to support the fairness and safety of language models in the healthcare domain, and address the issue of unfair outcomes potentially caused by data biases.
提供机构:
M42,AbuDhabi
创建时间:
2025-10-21
原始信息汇总
HC4(Healthcare Comprehensive Commons Corpus)数据集概述
数据集基本信息
- 数据集名称:HC4(Healthcare Comprehensive Commons Corpus)
- 存储库:m42-health/HC4
- 数据规模:153GB(约650亿个词元)
- 样本数量:970万+文档
- 数据格式:
.parquet文件 - 许可证:每个数据样本均采用允许商业使用和重新分发的开放许可证
数据来源与组成
- 数据来源:来自多样化医疗相关来源,包括从PubMed Central、Semantic Scholar、OpenAlex存储库收集的同行评审科学文献
主要用途
- 目的:用于医疗应用的大语言模型预训练
相关研究
- 参考论文:"Building Trust in Clinical LLMs: Bias Analysis and Dataset Transparency"(EMNLP 2025)
- 研究内容:提出临床LLMs的全面偏倚分析方法,提供数据集组成和管理的透明度
组织信息
- 组织:M42(阿布扎比)
搜集汇总
数据集介绍
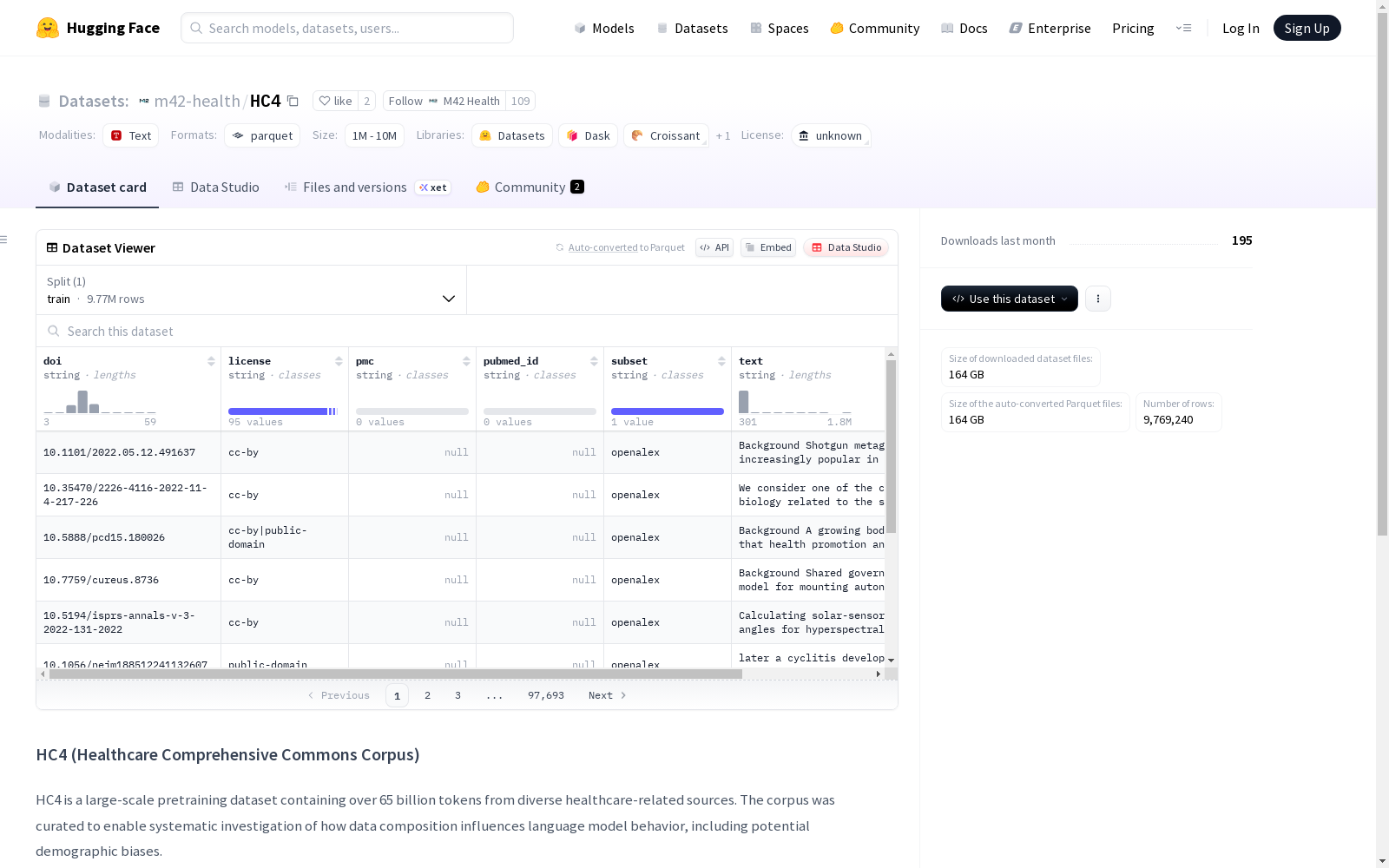
构建方式
在医疗人工智能领域,构建高质量预训练数据集对模型性能至关重要。HC4数据集通过系统化四阶段流程构建:数据收集阶段整合了来自语义学者开放研究语料库、PubMed Central、OpenAlex等权威生物医学文献平台的科学论文与临床指南;过滤阶段采用多层级筛选机制,包括语言识别、商业许可验证及领域相关性评估;清洗阶段运用GROBID机器学习算法提取文本并标准化格式;去重环节则采用MinHash局部敏感哈希技术,在5-gram层面实现文档级去重,最终形成包含890亿标记的纯净语料库。
特点
作为医疗领域的专用预训练资源,HC4数据集展现出显著特征优势。其语料规模达到890亿标记,涵盖科学期刊、医学档案、教科书和临床指南等多元来源,确保了内容的广度和深度。数据集特别注重医疗领域的专业性,通过严格的领域筛选机制保留具有PubMed或PubMed Central标识符的文献,并纳入临床指南等关键医疗实践文档。在数据质量方面,采用文档级去重技术实现1.85%的去重率,同时通过系统化清洗流程保持文本结构的完整性和规范性,为医疗语言模型训练提供了可靠的基础支撑。
使用方法
在医疗自然语言处理应用中,HC4数据集主要服务于语言模型的领域自适应预训练。研究人员可将该数据集作为基础训练资源,通过连续预训练方式使通用语言模型获得医疗领域专业知识。使用过程中需注意数据集的预处理要求,包括使用定制化的字节对编码分词器进行处理,词汇表规模设置为50,257。在实际应用中,该数据集支持多种模型架构的训练验证,已成功应用于GPT-2、Llama-3和Mistral等架构的医疗领域适配,为临床文本理解和医疗决策支持等任务提供底层语言能力支撑。
背景与挑战
背景概述
随着大型语言模型在医疗领域的应用日益广泛,构建高质量、专业化的预训练数据集成为推动临床人工智能发展的关键。HC4: Healthcare Comprehensive Commons Corpus 由 M42 机构的研究团队于2025年创建,旨在为医疗语言模型提供大规模、高质量的预训练语料。该数据集包含超过890亿标记,整合了来自生物医学文献、临床指南、教科书等多元来源,通过严格的去重和过滤流程确保数据质量。其核心研究问题聚焦于解决医疗数据中存在的偏见问题,特别是针对不同人口统计学群体(如种族、性别、年龄)的处方差异,为构建公平可靠的临床AI系统奠定基础。
当前挑战
在医疗领域,语言模型面临的核心挑战在于如何避免放大训练数据中固有的社会偏见,例如在阿片类药物处方中存在的种族、性别和年龄差异。HC4数据集构建过程中需应对多重挑战:首先,医疗数据的多样性和专业性要求极高的质量控制,包括从海量文献中筛选相关内容、处理复杂的医学术语结构;其次,数据去重和标准化流程需克服不同来源数据的异构性,如PDF解析中的格式不一致问题;此外,确保数据商业使用许可合规性也增加了构建复杂度。这些挑战直接影响模型在敏感医疗场景中的公平性和可靠性。
常用场景
经典使用场景
在医疗人工智能领域,HC4数据集作为专门针对临床语言模型预训练的大规模语料库,其经典使用场景主要体现在医疗文本理解与生成任务中。该数据集通过整合科学期刊、医学档案、教科书和临床指南等多元来源,为模型提供了丰富的医学知识背景。研究人员通常利用HC4进行领域自适应预训练,使通用语言模型能够掌握专业医学术语和临床推理逻辑,进而提升在医疗问答、病历分析和医学文献理解等任务中的表现。
解决学术问题
HC4数据集有效解决了医疗自然语言处理领域的关键学术问题,特别是针对临床语言模型存在的偏见放大问题。通过系统性的数据去重和质量过滤流程,该数据集显著降低了训练数据中的地理和人口统计偏差。其创新性的偏见评估框架,包括针对阿片类药物处方差异的分析方法,为量化模型在种族、性别和年龄维度上的公平性提供了科学依据,推动了医疗AI领域偏见检测与缓解技术的前沿探索。
衍生相关工作
HC4数据集催生了多项医疗AI领域的创新研究,其衍生工作主要集中在偏见评估框架的扩展应用和领域专用模型的开发。基于HC4构建的Net Bias Prescription Score方法已被应用于其他医疗场景的公平性评估,而结合该数据集训练的Meditron等模型则展示了领域自适应预训练在专业医疗任务中的优势。这些工作共同推动了医疗语言模型从通用能力向专业精准方向的演进,为构建可信赖的临床AI系统奠定了数据基础。
以上内容由遇见数据集搜集并总结生成


