Fineweb-Edu-Chinese-V2.2
收藏Hugging Face2026-02-01 更新2026-02-02 收录
下载链接:
https://huggingface.co/datasets/opencsg/Fineweb-Edu-Chinese-V2.2
下载链接
链接失效反馈官方服务:
资源简介:
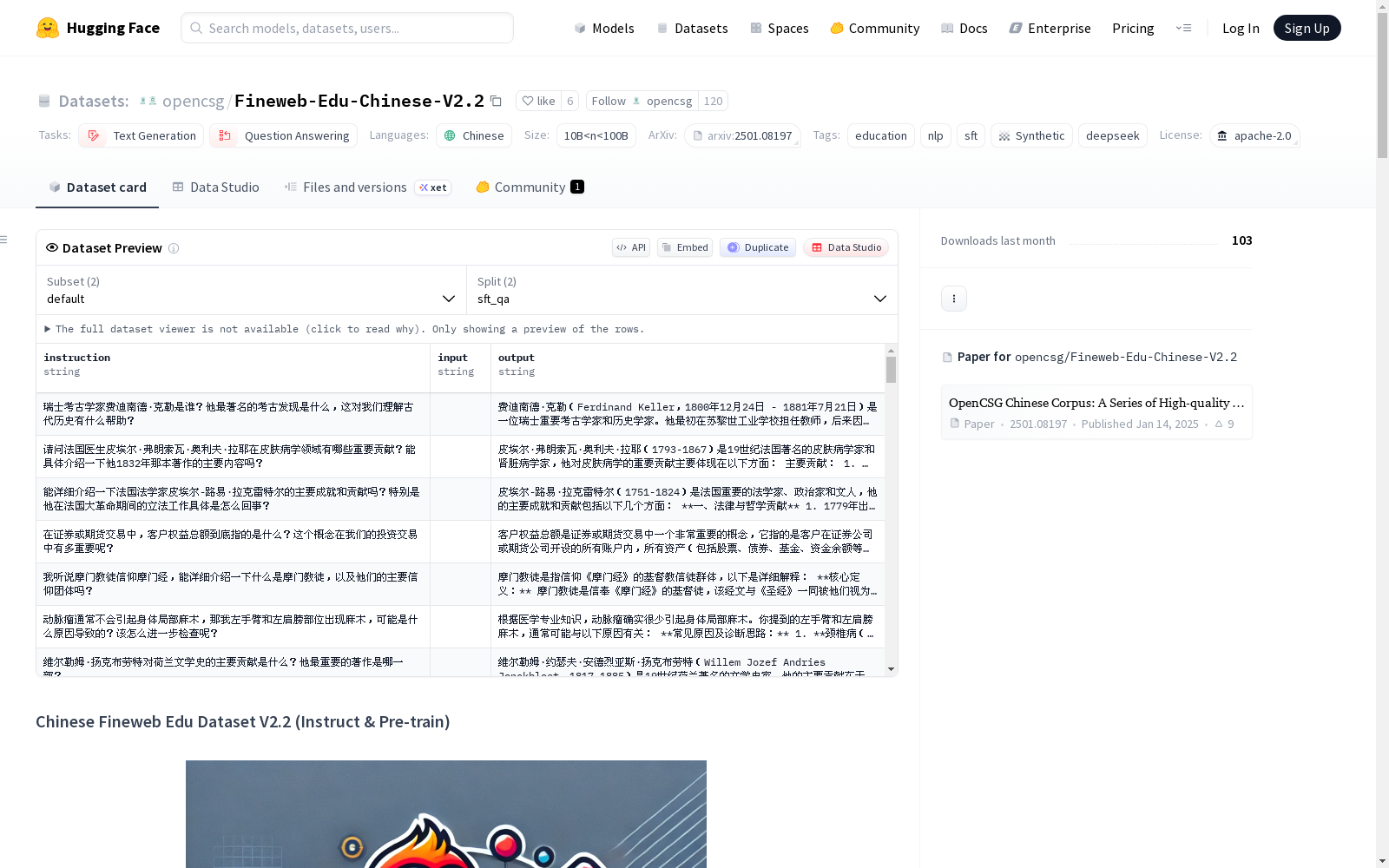
Chinese Fineweb Edu Dataset V2.2 是一个专为中文教育领域大模型开发的高质量数据集系列,旨在解决当前大模型研发中高质量中文教育语料稀缺的问题。该数据集包含预训练(Pre-train)和指令微调(SFT)数据,特别关注教育领域的垂直需求。
数据集的核心价值在于其高质量的数据筛选和生成过程。通过使用教育奖励模型(Educational Reward Model)对种子数据进行严格评分,仅保留知识密度高、逻辑连贯、学术严谨的内容(Top 0.1%-0.5%)。随后,利用DeepSeek V3.2生成具有教学逻辑的问答对,模拟人类教师的思维链条。
数据集分为两个主要部分:
1. **Full Context SFT**(143.7万条,14.6GB):包含原始种子文本和生成的问答,适合RAG训练。
2. **Pure QA SFT**(143.7万条,3.4GB):仅包含问答对,适合直接微调。
此外,V2.1版本的预训练数据仍可供使用,分为三个质量层级(Tier 1-3),支持课程学习策略。
该数据集适用于指令微调、对齐、RAG及基座模型预训练等场景,遵循OpenCSG Community License和Apache 2.0协议。
Chinese Fineweb Edu Dataset V2.2 is a high-quality dataset series specifically developed for Chinese educational domain large language models (LLMs), aiming to alleviate the shortage of high-quality Chinese educational corpora in current LLM research and development. This dataset includes pre-training (Pre-train) and instruction fine-tuning (SFT) data, with a dedicated focus on the vertical needs of the educational domain.
The core value of the dataset lies in its high-quality data filtering and generation process. Through strict scoring of seed data using an Educational Reward Model, only content with high knowledge density, logical coherence, and academic rigor (Top 0.1%–0.5%) is retained. Subsequently, DeepSeek V3.2 is utilized to generate question-answer pairs with pedagogical logic, simulating the thinking chain of human educators.
The dataset is divided into two main sections:
1. **Full Context SFT** (1.437 million entries, 14.6 GB): Contains original seed texts and generated question-answer pairs, suitable for RAG training.
2. **Pure QA SFT** (1.437 million entries, 3.4 GB): Only contains question-answer pairs, suitable for direct fine-tuning.
In addition, the pre-training data from the V2.1 version remains accessible, which is categorized into three quality tiers (Tier 1–3) to support curriculum learning strategies.
This dataset is suitable for scenarios including instruction fine-tuning, alignment, RAG, and base model pre-training, and is licensed under the OpenCSG Community License and Apache 2.0 License.
创建时间:
2026-01-30
搜集汇总
数据集介绍
构建方式
在中文教育大模型的发展进程中,高质量语料的构建始终是核心挑战。Fineweb-Edu-Chinese-V2.2数据集的构建采用了多阶段精炼策略,首先利用一个经过训练的教育奖励模型,对海量原始文本进行0-5分的质量评分,该评分综合考量了知识密度、逻辑连贯性与学术严谨度。随后,仅筛选出评分最高的约150万条顶级文本作为种子数据,这些数据涵盖了STEM、人文社科及百科知识等教育核心领域。最终,借助DeepSeek V3.2模型强大的推理与指令遵循能力,将这些静态的优质文本动态重构为包含详尽逻辑步骤的教学问答对,从而实现了从知识注入到行为对齐的数据闭环。
特点
该数据集最显著的特征在于其严格的质量分层与明确的应用导向。其预训练部分依据质量评分划分为三个层级,为课程学习策略提供了清晰的数据蓝图,使研究者能根据算力与目标灵活调配。指令微调部分则进一步细分为包含完整上下文的版本与纯问答对版本,分别精准服务于检索增强生成训练与高效的模型微调场景。所有数据均源于经过严苛筛选的顶级教育文本,并经由先进大模型转化,确保了内容的高准确性、强逻辑性与教学针对性,有效降低了模型在教育领域产生幻觉的风险。
使用方法
对于希望利用该数据集的研究者,Hugging Face的`datasets`库提供了便捷的访问接口。若目标是指令微调以塑造模型的交互与教学能力,可加载`sft_qa`分割获取轻量化的纯问答对数据。若需进行检索增强生成相关的训练,则应选择`sft_context`分割,该部分数据保留了原始的种子文本与生成的问答,有助于模型学习上下文关联。而对于基座模型的预训练任务,用户可以根据课程学习策略,按质量评分分层加载对应的预训练语料文件,例如优先使用评分在4-5分之间的高质量语料进行关键阶段的训练。
背景与挑战
背景概述
在人工智能与教育技术深度融合的时代背景下,高质量、领域专用的中文教育语料成为制约大语言模型向专业化、精细化方向发展的关键瓶颈。Chinese Fineweb Edu Dataset V2.2 由 OpenCSG 社区于2026年1月正式发布,其核心研究目标在于系统性地填补中文教育大模型在预训练与指令微调阶段的数据空白。该数据集旨在解决通用网络语料在教育场景下存在的知识密度低、逻辑混乱及“幻觉”频发等问题,通过引入 DeepSeek V3.2 的高阶推理能力,将静态的教科书级文本转化为动态的、具备教学逻辑的问答对,从而为模型提供从知识注入到行为对齐的全流程数据解决方案,对推动教育垂直领域大模型的研发与应用具有里程碑意义。
当前挑战
该数据集致力于应对教育领域大模型面临的核心挑战:如何确保模型在复杂学科知识问答中保持高度的准确性与逻辑连贯性,同时有效抑制“幻觉”现象。在构建过程中,团队面临多重技术挑战:首先是从海量原始数据中精准筛选出知识密度高、学术严谨的优质种子文本,这依赖于一个训练有素的教育奖励模型进行精细化的质量评分与分层;其次是将筛选出的顶级文本转化为高质量教学对话,这一过程要求生成模型不仅能提取核心知识点,还需模拟人类教师的解释性与引导性思维链条,确保生成的问答对具备教学深度与逻辑步骤。整个构建流程体现了从粗放语料收集到精细化知识重构的显著跨越。
常用场景
经典使用场景
在中文教育大模型研发领域,高质量指令微调数据的稀缺长期制约着模型教学能力的提升。Fineweb-Edu-Chinese-V2.2数据集通过集成海量预训练语料与精心构建的SFT问答对,为模型后训练阶段提供了经典范例。其核心应用场景在于利用DeepSeek V3.2生成的多轮逻辑对话,模拟人类教师的教学思维链条,有效训练模型在STEM、人文社科等垂直领域进行知识推导与解释性回答,从而将静态知识转化为动态教学交互。
实际应用
在实际部署中,该数据集支持多样化的教育技术场景。其纯问答格式适用于快速指令微调,可集成至LLaMA-Factory等框架,高效构建学科辅导或知识问答系统;包含原文的完整上下文数据则专为检索增强生成设计,能够训练模型精准识别相关教学材料并生成依据充分的解答。这些能力使得数据集能够赋能智能教学助手、个性化学习平台以及教育内容自动生成工具,切实提升数字化教育的智能化水平。
衍生相关工作
围绕该数据集衍生的经典工作主要集中在高质量教育语料构建与模型优化路径上。其采用的教育奖励模型打分机制,启发了后续研究对文本知识密度与逻辑连贯性的量化评估;基于课程学习的数据分层策略,为资源受限下的高效模型训练提供了可复现的范式。此外,数据集作为开源社区中规模领先的中文教育语料库,已成为众多学术研究对比实验的基准,持续推动着教育大模型在事实性、推理链与教学逻辑等方面的性能突破。
以上内容由遇见数据集搜集并总结生成


