keremberke/license-plate-object-detection
收藏Hugging Face2023-01-18 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/keremberke/license-plate-object-detection
下载链接
链接失效反馈官方服务:
资源简介:
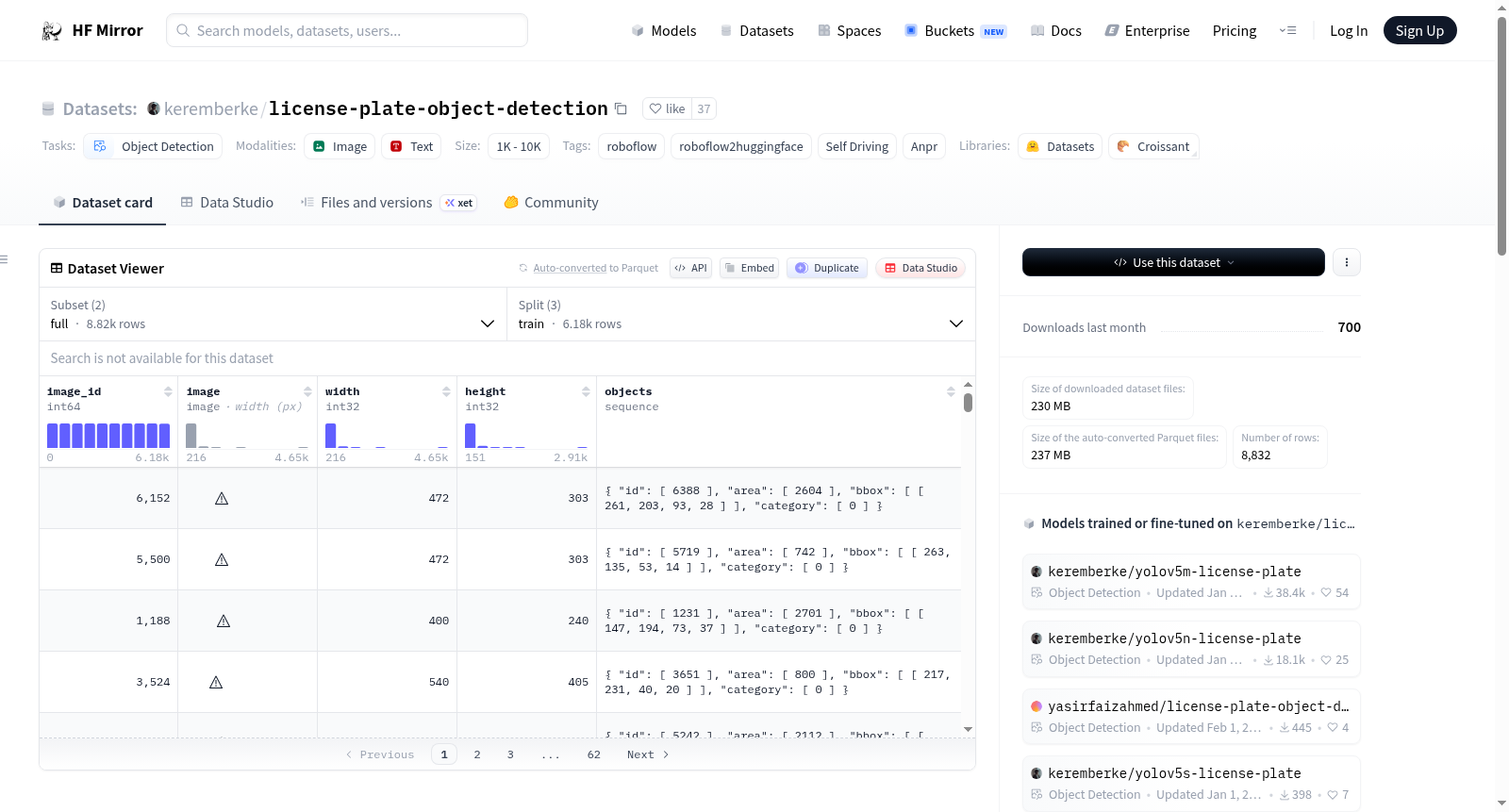
该数据集包含8823张图像,图像中的车辆注册牌照(VRP)以COCO格式进行标注。每张图像都进行了自动方向调整的预处理,但没有应用图像增强技术。数据集分为训练集(6176张)、验证集(1765张)和测试集(882张)。
This dataset consists of 8,823 images. Vehicle Registration Plates (VRPs) in these images are annotated in the COCO format. Preprocessing with automatic orientation adjustment has been applied to each image, while no image augmentation techniques were utilized. The dataset is partitioned into three subsets: a training set with 6,176 images, a validation set with 1,765 images, and a test set with 882 images.
提供机构:
keremberke
原始信息汇总
数据集概述
任务类别
- 目标检测
标签
license_plate
图像数量
- 训练集: 6176张
- 验证集: 1765张
- 测试集: 882张
使用方法
-
安装
datasets库: bash pip install datasets -
加载数据集: python from datasets import load_dataset ds = load_dataset("keremberke/license-plate-object-detection", name="full") example = ds[train][0]
许可证
- CC BY 4.0
搜集汇总
数据集介绍
构建方式
在自动驾驶与智能交通系统领域,车牌检测数据集的构建需兼顾多样性与精确性。本数据集通过Roboflow平台导出,包含8823张图像,所有车牌均以COCO格式进行标注。构建过程中,每张图像均经过自动方向校正处理,移除了EXIF方向信息,但未采用任何图像增强技术,确保了数据的原始性与一致性。数据划分为训练集6176张、验证集1765张及测试集882张,为模型训练与评估提供了结构化支持。
特点
该数据集专注于单一目标类别——车牌检测,标签集简洁明确,仅包含'license_plate'一类。图像内容涵盖多样化的车辆与场景,适用于自动驾驶及自动车牌识别(ANPR)任务。数据集遵循CC BY 4.0许可协议,具有开源可访问性,且标注格式采用通用的COCO标准,便于与现有目标检测框架无缝集成。其规模适中,划分合理,为算法开发与性能验证提供了可靠的基础。
使用方法
使用本数据集前,需通过pip安装datasets库。加载时调用load_dataset函数,指定数据集名称及配置(如'full'),即可获取包含训练、验证与测试分割的数据对象。用户可便捷访问图像及对应的边界框标注,直接应用于模型训练或评估流程。数据集源自Roboflow Universe平台,相关详情页提供了额外的元信息与可视化示例,辅助用户深入理解数据分布与应用场景。
背景与挑战
背景概述
随着自动驾驶与智能交通系统的蓬勃发展,车牌检测作为自动车牌识别(ANPR)技术的核心环节,其重要性日益凸显。该数据集由Augmented Startups机构于2022年创建,旨在为车牌目标检测任务提供高质量的标注数据。数据集包含超过八千张图像,涵盖训练、验证与测试集,采用COCO格式标注,专注于解决复杂交通场景下车牌的精确定位问题。该资源的发布,显著推动了计算机视觉在车辆识别、安防监控及智慧城市等领域的应用研究,为相关算法模型的训练与评估提供了重要基准。
当前挑战
车牌检测任务面临多重现实挑战:在复杂多变的交通环境中,车牌常受光照变化、遮挡、污损、视角倾斜及远距离拍摄等因素干扰,导致检测精度下降;同时,不同国家与地区的车牌样式、尺寸、颜色及字符布局差异显著,要求模型具备强大的泛化能力。在数据集构建过程中,挑战主要集中于大规模图像的高质量标注,需确保边界框的精确性与一致性,并克服数据采集时因天气、时间及拍摄设备差异引入的噪声,以构建具有广泛代表性的样本集合。
常用场景
经典使用场景
在自动驾驶与智能交通系统领域,车牌检测作为关键视觉任务,其数据集常被用于训练和评估目标检测模型。该数据集通过提供大量标注精确的车牌图像,为研究者构建高效的车牌定位算法奠定了数据基础。经典使用场景包括在复杂道路环境中,利用深度学习模型如YOLO或Faster R-CNN,实现实时、高精度的车牌区域识别,进而支撑后续的字符分割与识别流程。
衍生相关工作
围绕该数据集,已催生了一系列经典的学术与工程实践。许多研究工作以其为基础,探索了轻量化检测网络以适应边缘计算设备,或结合注意力机制以提升模型在密集车辆场景下的表现。同时,它也常作为基准数据集,用于比较不同目标检测框架在车牌识别任务上的性能,促进了相关开源工具链和预训练模型的迭代与发展。
数据集最近研究
最新研究方向
在自动驾驶与智能交通系统领域,车牌检测数据集正推动着计算机视觉技术的深度应用。当前研究聚焦于提升模型在复杂环境下的鲁棒性,如应对光照变化、遮挡及多角度视角的挑战。前沿探索涉及轻量化网络架构的设计,旨在实现边缘设备上的实时处理,同时结合多模态数据融合,增强车牌识别的准确性与泛化能力。相关热点事件包括智慧城市安防升级与自动化收费系统的普及,这些进展不仅优化了交通管理效率,也为隐私保护与数据安全提供了新的研究维度,彰显了该数据集在推动产业智能化转型中的关键意义。
以上内容由遇见数据集搜集并总结生成


