AgentVLN-Instruct
收藏arXiv2026-03-18 更新2026-03-20 收录
下载链接:
https://github.com/Allenxinn/AgentVLN
下载链接
链接失效反馈官方服务:
资源简介:
AgentVLN-Instruct是由南京航空航天大学等机构构建的大规模指令调优数据集,专为视觉语言导航任务设计。该数据集通过动态阶段路由机制,将高级指令与低级技能调用紧密对齐,模拟人类先粗导航后精定位的寻路过程。其创新性地引入目标可见性条件,为下一代轻量化具身导航模型提供了实用的训练范式,可有效解决长视野导航中的语义-空间表征不一致问题。
AgentVLN-Instruct is a large-scale instruction-tuning dataset constructed by Nanjing University of Aeronautics and Astronautics and other institutions, specifically designed for vision-language navigation (VLN) tasks. Leveraging a dynamic phase routing mechanism, it tightly aligns high-level navigation instructions with low-level skill invocations, simulating the human pathfinding process of first performing coarse-grained navigation and then precise positioning. It innovatively introduces the target visibility condition, providing a practical training paradigm for the next generation of lightweight embodied navigation models, which can effectively resolve the inconsistency issue between semantic and spatial representations in long-horizon navigation tasks.
提供机构:
南京航空航天大学; 山东大学; 浙江大学
创建时间:
2026-03-18
原始信息汇总
AgentVLN 数据集概述
数据集基本信息
- 数据集名称:AgentVLN
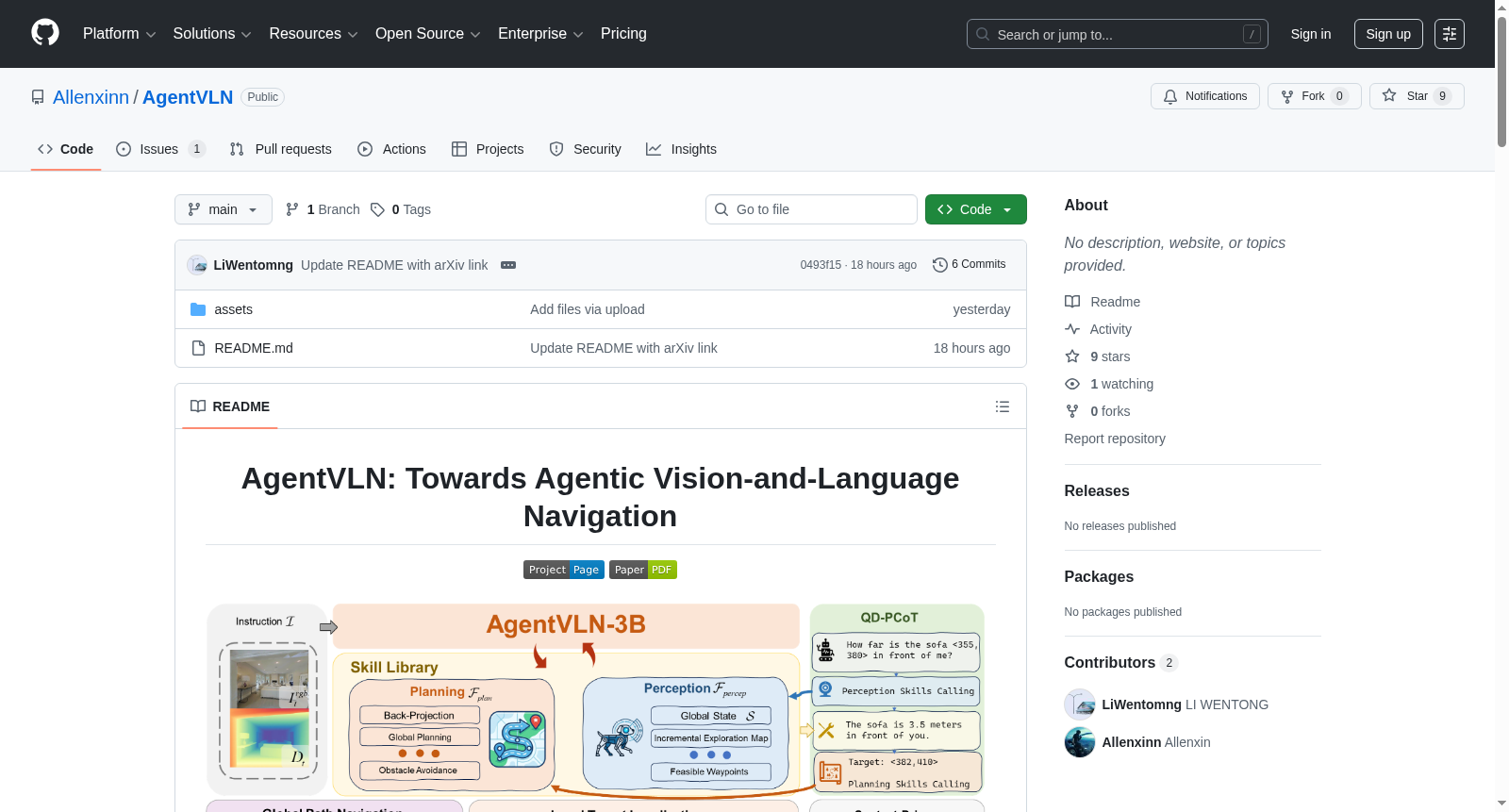
- 核心定位:一个用于未见环境中长视野视觉与语言导航的高效具身导航框架。
- 核心范式:遵循 VLM-as-Brain 范式,将高级语义推理与低级感知和规划解耦。
核心方法与特点
- 问题建模:将视觉与语言导航问题建模为部分可观察马尔可夫决策过程。
- 模块化设计:通过即插即用的技能库实现功能解耦。
- 跨空间表示映射:将3D拓扑路径点投影到图像平面,作为像素对齐的视觉提示,以弥合3D规划与2D视觉语言模型感知之间的差距。
- 上下文感知自校正:细粒度的主动探索帮助智能体在长视野导航中从遮挡、盲点和轨迹漂移中恢复。
- 空间模糊性处理:查询驱动的感知思维链机制使智能体能够主动查询缺失的几何线索,以实现更精确的目标定位。
- 部署效率:框架实现了良好的准确性与效率权衡,支持在嵌入式边缘平台上进行实时本地推理。
性能与评估
- 评估基准:在 R2R-CE 和 RxR-CE 基准的未见环境验证集上进行了测试。
- 性能表现:在未见复杂环境中展现出强大的泛化能力,持续优于先前的先进方法。
资源状态
- 已发布:项目页面与论文PDF。
- 待发布:训练与推理代码、预训练模型检查点、安装与环境设置说明。
相关链接
- 项目页面:https://allenxinn.github.io/AgentVLN/
- 论文:https://arxiv.org/abs/2603.17670
引用格式
latex @misc{xin2026agentvln, title={AgentVLN: Towards Agentic Vision-and-Language Navigation}, author={Zihao Xin and Wentong Li and Yixuan Jiang and Ziyuan Huang and Bin Wang and Piji Li and Jianke Zhu and Jie Qin and Sheng-Jun Huang}, year={2026}, eprint={2603.17670}, archivePrefix={arXiv}, primaryClass={cs.RO}, url={https://arxiv.org/abs/2603.17670}, }
搜集汇总
数据集介绍
构建方式
在视觉与语言导航领域,构建高质量的数据集对于推动具身智能体的发展至关重要。AgentVLN-Instruct数据集基于Habitat仿真平台构建,其核心创新在于引入了动态阶段路由机制。该机制根据目标在视觉观测中的可见性,将导航过程划分为全局路径规划与局部目标定位两个阶段,模拟人类从粗到精的寻路认知模式。数据生成过程中,全局路径规划阶段通过调用感知技能选择专家对齐的路径点;局部目标定位阶段则采用多轮感知思维链模拟主动推理,预测精确的目标像素坐标。为增强鲁棒性,数据集还注入了轨迹噪声,并在视觉路径点缺失时使用细粒度动作序列作为后备方案,从而实现了高层指令与底层技能调用的紧密对齐。
特点
AgentVLN-Instruct数据集的设计深刻反映了解决当前视觉语言导航系统核心挑战的意图。其首要特点是动态的阶段路由机制,该机制并非采用单一控制策略,而是根据目标可见性自适应切换导航阶段,有效模拟了人类在未知环境中的分层决策过程。其次,数据集紧密集成了可泛化的技能调用标注,将复杂的导航任务分解为模块化的感知与规划技能执行序列,为模型学习高层调度提供了结构化监督。此外,数据集包含了用于局部目标定位的主动问答交互与推理链数据,旨在赋予模型在面临空间歧义时主动查询几何信息的能力,从而缓解单目视觉的尺度模糊性问题。这些特点共同构成了一个旨在弥合二维视觉表征与三维物理空间语义鸿沟的综合性指令调优资源。
使用方法
AgentVLN-Instruct数据集主要用于训练和微调基于‘视觉语言模型即大脑’范式的具身导航智能体。在使用时,该数据集与通用多模态视频数据(如LLaVA-Video-178K)结合进行指令调优,以在提升导航专用能力的同时保留模型的基础多模态理解能力。训练过程中,模型的视觉编码器与多模态投影层通常被冻结,优化重点在于使视觉语言模型学会根据动态的视觉历史上下文和自然语言指令,来调度感知与规划技能库中的相应模块。具体而言,模型需要学习在全局路径不可见时触发细粒度的探索动作进行自我校正,并在检测到空间歧义时,通过生成自然语言查询并调用感知技能来启动查询驱动的感知思维链推理,最终输出精确的目标坐标。这种使用方法旨在将导航任务转化为高层语义匹配与技能调度问题,从而提升模型在未知复杂环境中的泛化性与决策透明度。
背景与挑战
背景概述
AgentVLN-Instruct 数据集由南京航空航天大学、山东大学与浙江大学的联合研究团队于2026年创建,旨在推动具身视觉语言导航领域的发展。该数据集的核心研究问题是解决传统视觉语言导航系统中存在的多层级表征不一致、二维与三维空间语义割裂以及单目尺度模糊性等关键瓶颈。通过引入动态阶段路由机制,并依据目标可见性条件生成指令调优数据,该数据集有效模拟了人类从粗粒度路径规划到细粒度目标定位的渐进式寻路过程。其构建为AgentVLN框架提供了关键的训练基础,显著提升了导航模型在未知复杂环境中的泛化能力与部署效率,对推动轻量级、可解释的具身智能系统迈向实际应用具有重要影响力。
当前挑战
AgentVLN-Instruct 数据集致力于解决视觉语言导航领域的两大核心挑战。在领域问题层面,传统VLN系统难以实现二维视觉语义与三维物理几何之间的精准对齐,导致智能体在遵循自然语言指令进行长程导航时,常因空间感知局限与尺度歧义而失败。该数据集通过显式的跨空间表征映射与查询驱动的感知思维链机制,旨在弥合这一语义鸿沟。在构建过程中,研究团队面临如何生成大规模、高质量且与模块化技能调用紧密对齐的指令-轨迹配对数据的挑战。这需要设计动态的阶段路由逻辑,以模拟目标可见性变化下的决策切换,并注入轨迹噪声以增强模型的纠错与泛化能力,确保数据能有效支撑高级语义推理与低层技能执行的解耦训练。
常用场景
经典使用场景
在具身智能与视觉语言导航领域,AgentVLN-Instruct数据集主要用于训练和评估能够理解复杂自然语言指令并在未知三维环境中进行长程导航的智能体。该数据集通过模拟人类从粗到精的寻路过程,构建了动态的阶段路由机制,其核心应用场景在于解决传统视觉语言模型在物理世界中因二维视觉表征与三维几何结构不匹配而导致的导航失效问题。具体而言,数据集引导模型在全局路径规划阶段调用感知技能选择专家对齐的路径点,在局部目标定位阶段则通过多轮感知思维链模拟主动推理,以预测精确的目标像素坐标,从而弥合了高层语义指令与底层技能执行之间的鸿沟。
衍生相关工作
AgentVLN-Instruct数据集的构建理念与核心方法,启发并推动了后续一系列相关研究。其提出的‘视觉语言模型即大脑’及技能解耦范式,与同期兴起的双系统导航架构(如DualVLN, InternVLA-N1)形成了思想共鸣,共同探索将高层语义推理与底层动作执行分离的有效路径。数据集为解决表征不一致性而设计的跨空间映射机制,为后续研究如何将三维几何信息更自然地融入视觉语言模型的认知流程提供了明确的技术蓝图。此外,其首创的查询驱动感知思维链机制,直接促进了具身智能领域对‘主动感知’和‘需求信息查询’范式的关注,相关思想被后续工作拓展应用于更广泛的机器人交互与场景理解任务中,成为提升智能体在开放世界中适应性的重要技术路线之一。
数据集最近研究
最新研究方向
在具身智能与视觉语言导航领域,AgentVLN-Instruct数据集的研究聚焦于解决传统导航系统中2D视觉表示与3D物理空间之间的表征不一致性难题。该数据集通过引入动态阶段路由机制,模拟人类从粗到精的寻路过程,并构建了大规模指令调优数据,以紧密对齐高层语义指令与低层技能调用。其前沿探索体现在推动‘视觉语言模型作为大脑’的范式,将长程导航任务解耦为模块化技能执行,并结合跨空间表征映射、上下文感知的自我校正以及查询驱动的感知思维链,显著提升了导航模型在未知复杂环境中的泛化能力与部署效率,为轻量级边缘计算平台上的实时导航提供了切实可行的解决方案。
相关研究论文
- 1AgentVLN: Towards Agentic Vision-and-Language Navigation南京航空航天大学; 山东大学; 浙江大学 · 2026年
以上内容由遇见数据集搜集并总结生成


