SPCD (Semcor Pairs for Concept Differentiation)
收藏arXiv2025-08-06 更新2025-08-08 收录
下载链接:
https://hf.co/datasets/gabrielloiseau/CALE-SPCD/
下载链接
链接失效反馈官方服务:
资源简介:
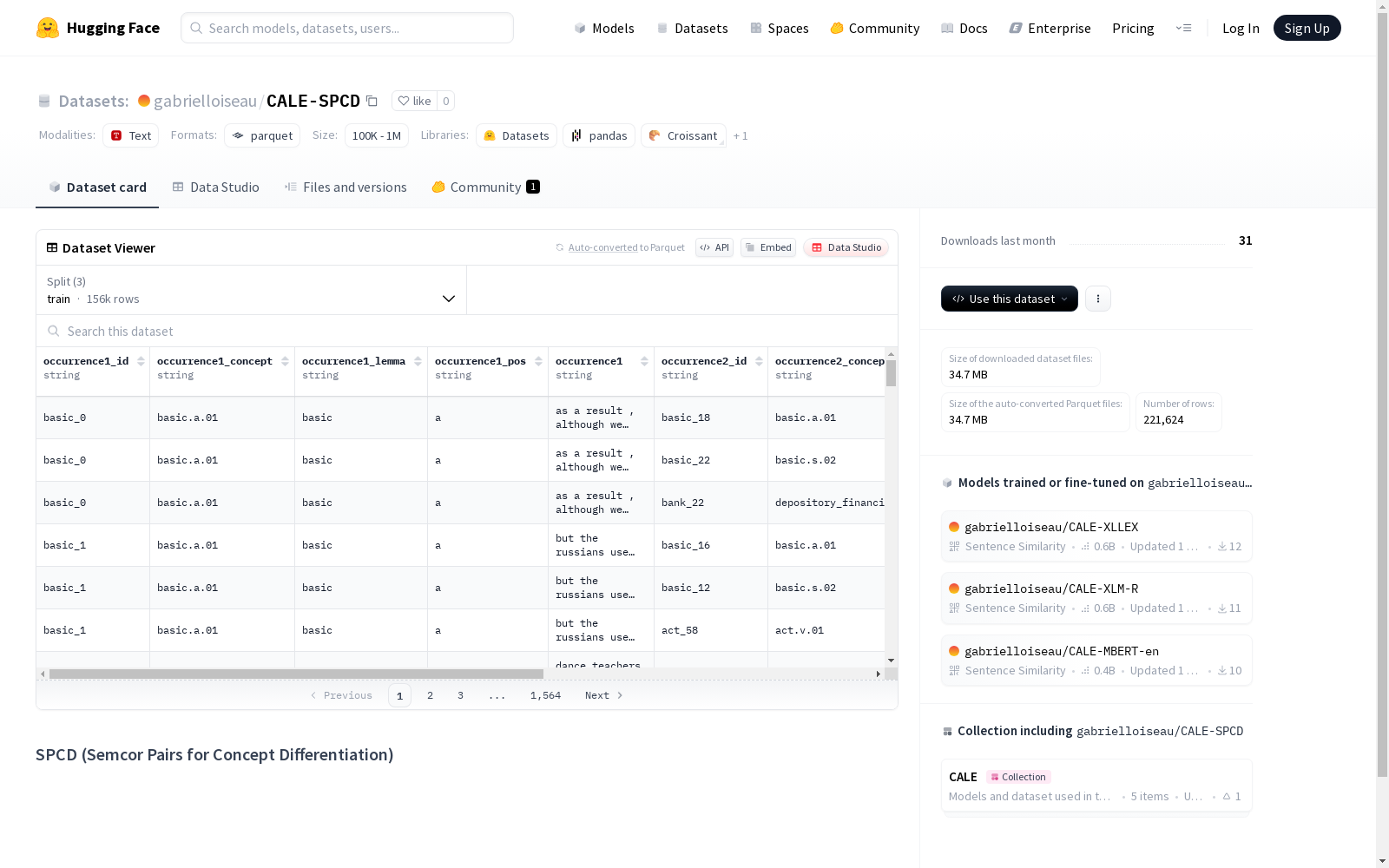
SPCD数据集由法国里尔大学的研究人员创建,旨在支持词汇语义研究。该数据集从SemCor语料库中提取,包含1902个目标词的70.3万条记录,涵盖5899个概念。数据集包含44k对测试数据、20k对验证数据和156k对训练数据,旨在支持词汇语义表示和消歧研究。
The SPCD dataset was created by researchers from the University of Lille, France, to support lexical semantics research. Extracted from the SemCor corpus, it contains 703,000 records for 1902 target words, covering 5899 concepts. The dataset includes 44k test pairs, 20k validation pairs and 156k training pairs, and is designed to support research on lexical semantic representation and word sense disambiguation.
提供机构:
法国里尔大学
创建时间:
2025-08-06
搜集汇总
数据集介绍
构建方式
SPCD数据集从SemCor语料库中提取,专注于形容词、名词和动词的词义标注。通过严格的筛选标准,仅保留长度在10至100词之间且带有WordNet同义词集标注的句子。每个目标词的出现次数需满足最低10次的条件,并排除复合词和专有名词。数据集的构建过程确保了概念标注的准确性和多样性,涵盖了同一词形不同概念和不同词形相同概念的配对。
特点
SPCD数据集的特点在于其严格的概念标注和丰富的语义多样性。它不仅包含同一词形不同概念的配对(多义性),还涵盖不同词形相同概念的配对(同义性)。数据集通过分区训练集、验证集和测试集,确保模型能够泛化到未见过的词形和概念。此外,数据集的标注基于WordNet同义词集,提供了丰富的语义层次结构信息。
使用方法
SPCD数据集主要用于训练和评估词义表示模型,特别是在概念区分任务中。用户可以通过计算词对在上下文中的余弦相似度,判断它们是否指向同一概念。数据集还可用于跨语言词义变化检测和上下文词义相似性评估。使用时需注意严格分区,避免数据泄露,确保模型评估的可靠性。
背景与挑战
背景概述
SPCD(Semcor Pairs for Concept Differentiation)数据集由法国里尔大学、Inria和CNRS的研究团队于2025年创建,旨在解决词汇语义学中的概念区分问题。该数据集基于SemCor语料库构建,通过标注WordNet的synsets作为概念标签,支持跨词项(inter-lemma)和同词项(intra-lemma)的语义对比研究。SPCD的提出填补了传统Word-in-Context(WiC)任务仅关注同词项语义差异的局限,为概念对齐嵌入(CALE)模型的训练提供了重要资源,推动了词义表示从词形中心向概念中心的范式转变。
当前挑战
SPCD数据集面临的核心挑战包括:1)领域问题层面,需解决跨词项语义关系(如同义性)与词内多义性(polysemy)的联合建模,传统WiC任务仅能处理后者;2)构建过程中需克服SemCor标注粒度与概念对齐的冲突,例如严格划分训练/测试集时需确保概念与词项的非重叠性以避免数据泄露,同时平衡40%的正样本比例以反映自然语言中概念分布的稀疏性。此外,跨语言迁移中英语单语训练的局限性,以及二元分类对连续语义相似度的简化,均为后续研究留下改进空间。
常用场景
经典使用场景
SPCD数据集在自然语言处理领域被广泛用于概念区分任务,特别是在词义消歧和词义相似性计算中。该数据集通过提供同一词素和不同词素之间的概念对齐标注,为研究者提供了一个评估模型在复杂语义场景下表现的标准平台。在词义消歧任务中,SPCD帮助模型区分同一词素在不同上下文中的不同含义;而在词义相似性计算中,它则支持模型识别不同词素在特定上下文中表达的相同概念。
衍生相关工作
基于SPCD数据集衍生的经典工作包括CALE模型系列,其在跨语言词义变化检测任务中刷新了性能记录。XL-LEXEME模型的改进版本通过融入SPCD训练数据,显著提升了跨词素概念识别的鲁棒性。后续研究进一步扩展了该数据集的适用场景,开发出面向多词表达的概念对齐评估框架,为语义解析任务提供了新的基准工具。
数据集最近研究
最新研究方向
在计算词汇语义学领域,SPCD(Semcor Pairs for Concept Differentiation)数据集的最新研究方向聚焦于概念对齐嵌入(Concept-Aligned Embeddings, CALE)的开发与应用。该数据集源自SemCor语料库,通过构建同义词和跨词对的二元分类任务,旨在捕捉词汇的多义性和同义性关系。前沿研究显示,CALE模型在概念区分任务中表现卓越,平衡准确率达到79.3%,并在跨语言的词汇语义变化检测(LSCD)和上下文词汇相似性任务中展现出强大的泛化能力。这一进展不仅推动了词义表示从词形中心向概念中心的转变,还为语义框架归纳和多词表达式分析等任务提供了新的研究路径。
相关研究论文
- 1CALE : Concept-Aligned Embeddings for Both Within-Lemma and Inter-Lemma Sense Differentiation法国里尔大学 · 2025年
以上内容由遇见数据集搜集并总结生成


