Logo-2K+
收藏github2024-04-23 更新2024-05-31 收录
下载链接:
https://github.com/Wangjing1551/Logo-2k-plus-Dataset
下载链接
链接失效反馈官方服务:
资源简介:
在本工作中,我们构建了一个大规模的Logo数据集,Logo-2K+,它涵盖了从真实世界Logo图像中提取的多种Logo类别。我们的Logo数据集包含167,140张图像,分为10个根类别和2,341个子类别。
In this work, we have constructed a large-scale logo dataset, Logo-2K+, which encompasses a diverse range of logo categories extracted from real-world logo images. Our logo dataset comprises 167,140 images, categorized into 10 root categories and 2,341 subcategories.
创建时间:
2020-08-09
原始信息汇总
Logo-2K+ 数据集概述
数据集描述
- Logo-2K+ 是一个大规模的标志数据集,包含来自真实世界标志图像的多样化标志类别。
- 数据集包含
167,140张图像,分为10个根类别和2,341个子类别。
数据集统计
| 根类别 | 标志数量 | 图像数量 |
|---|---|---|
| 食品 | 769 | 54,507 |
| 服装 | 286 | 20,413 |
| 机构 | 238 | 17,103 |
| 配饰 | 210 | 14,569 |
| 交通 | 203 | 14,719 |
| 电子 | 191 | 13,972 |
| 必需品 | 182 | 13,205 |
| 化妆品 | 115 | 7,929 |
| 休闲 | 99 | 7,338 |
| 医疗 | 48 | 3,385 |
| 总计 | 2,341 | 167,140 |
下载链接
- 百度云链接: https://pan.baidu.com/s/1L_9JROsWSQEAznNiy-wTBQ 密码: 945w
- Google Drive链接: https://drive.google.com/open?id=1PTA24UTZcsnzXPN1gmV0_lRg3lMHqwp6
搜集汇总
数据集介绍
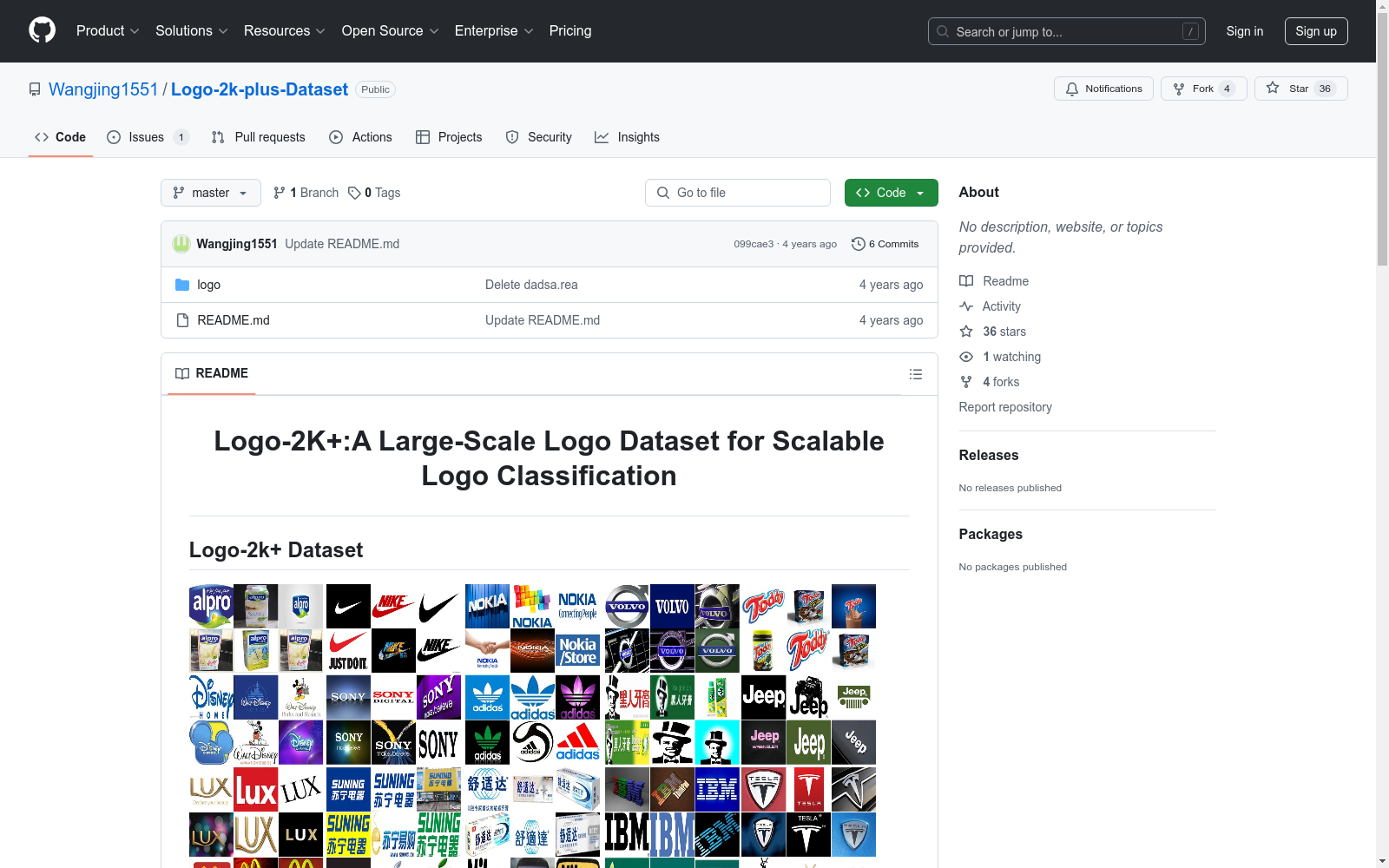
构建方式
在构建Logo-2K+数据集的过程中,研究团队精心策划并收集了来自现实世界的大量标志图像,涵盖了广泛的类别。该数据集包含167,140张图像,分为10个根类别和2,341个子类别,确保了数据的多样性和广泛性。每个根类别进一步细分为多个子类别,如食品、服装、机构等,每个子类别均包含一定数量的图像,从而为标志分类任务提供了丰富的数据资源。
特点
Logo-2K+数据集的一个显著特点是其规模和多样性。该数据集不仅包含大量的图像,还涵盖了从食品到医疗等多个领域的标志,确保了数据的多领域覆盖。此外,数据集的结构化分类使得研究人员能够针对特定领域进行深入分析和模型训练。这种细致的分类和庞大的数据量使得Logo-2K+成为标志分类研究中的重要资源。
使用方法
使用Logo-2K+数据集进行研究时,首先需要从提供的下载链接获取数据集,并将其放置在项目的根目录中。接着,用户可以通过设置数据路径和调整超参数来进行模型训练。训练过程中,用户可以运行'python train.py'脚本,训练结果将保存在指定的目录中。测试模型时,运行'python test.py'脚本,并指定测试模型以评估模型的性能。
背景与挑战
背景概述
在计算机视觉领域,标志(Logo)识别与分类一直是重要的研究课题,尤其在品牌识别、广告监测和知识产权保护等方面具有广泛应用。Logo-2K+数据集由一支多机构合作的研究团队于2020年构建,旨在为大规模标志分类提供高质量的基准数据。该数据集涵盖了2,341个类别,包含167,140张图像,涵盖了从食品、服装到电子产品等多个领域的标志。其多样性和规模使其成为标志分类研究的重要资源,推动了相关算法的发展与评估。
当前挑战
Logo-2K+数据集的构建面临多重挑战。首先,标志图像的多样性极高,不同品牌和类别的标志在形状、颜色和复杂度上存在显著差异,增加了分类任务的复杂性。其次,标志图像的获取和标注过程需要大量的人力和时间,确保数据集的高质量和一致性。此外,标志分类任务中,类间相似性和类内差异性也是主要挑战,要求算法具备较高的区分能力。这些挑战不仅推动了数据集的构建,也促进了标志分类算法的研究与创新。
常用场景
经典使用场景
Logo-2K+数据集因其丰富的类别和大规模的图像数量,成为图像分类和识别领域中的经典研究对象。该数据集广泛应用于深度学习模型的训练与评估,特别是在卷积神经网络(CNN)和迁移学习中,用于提升模型对复杂背景下标志的识别能力。通过Logo-2K+,研究者能够探索不同类别标志的特征提取与分类策略,从而推动标志识别技术的进步。
衍生相关工作
基于Logo-2K+数据集,研究者们开展了多项相关工作,推动了标志识别技术的进一步发展。例如,有研究提出了基于深度学习的标志检测与识别框架,显著提升了标志识别的准确率和鲁棒性。此外,还有工作探讨了如何在多类别、小样本的情况下进行有效的迁移学习,为标志识别技术在实际应用中的推广提供了新的思路和方法。
数据集最近研究
最新研究方向
在计算机视觉领域,Logo-2K+数据集的引入为大规模标志分类任务提供了丰富的资源,推动了该领域的研究前沿。该数据集不仅涵盖了2,341个类别,还包含了167,140张图像,极大地扩展了标志识别的研究范围。近年来,研究者们利用这一数据集探索了深度学习模型在标志分类中的应用,尤其是在多类别、大规模数据环境下的模型优化与泛化能力。此外,Logo-2K+数据集的多样性和广泛性也激发了跨领域研究,如品牌识别、图像检索和视觉搜索等,进一步推动了计算机视觉技术的实际应用。
以上内容由遇见数据集搜集并总结生成


