TESTEVAL
收藏arXiv2024-06-07 更新2024-06-21 收录
下载链接:
https://llm4softwaretesting.github.io
下载链接
链接失效反馈官方服务:
资源简介:
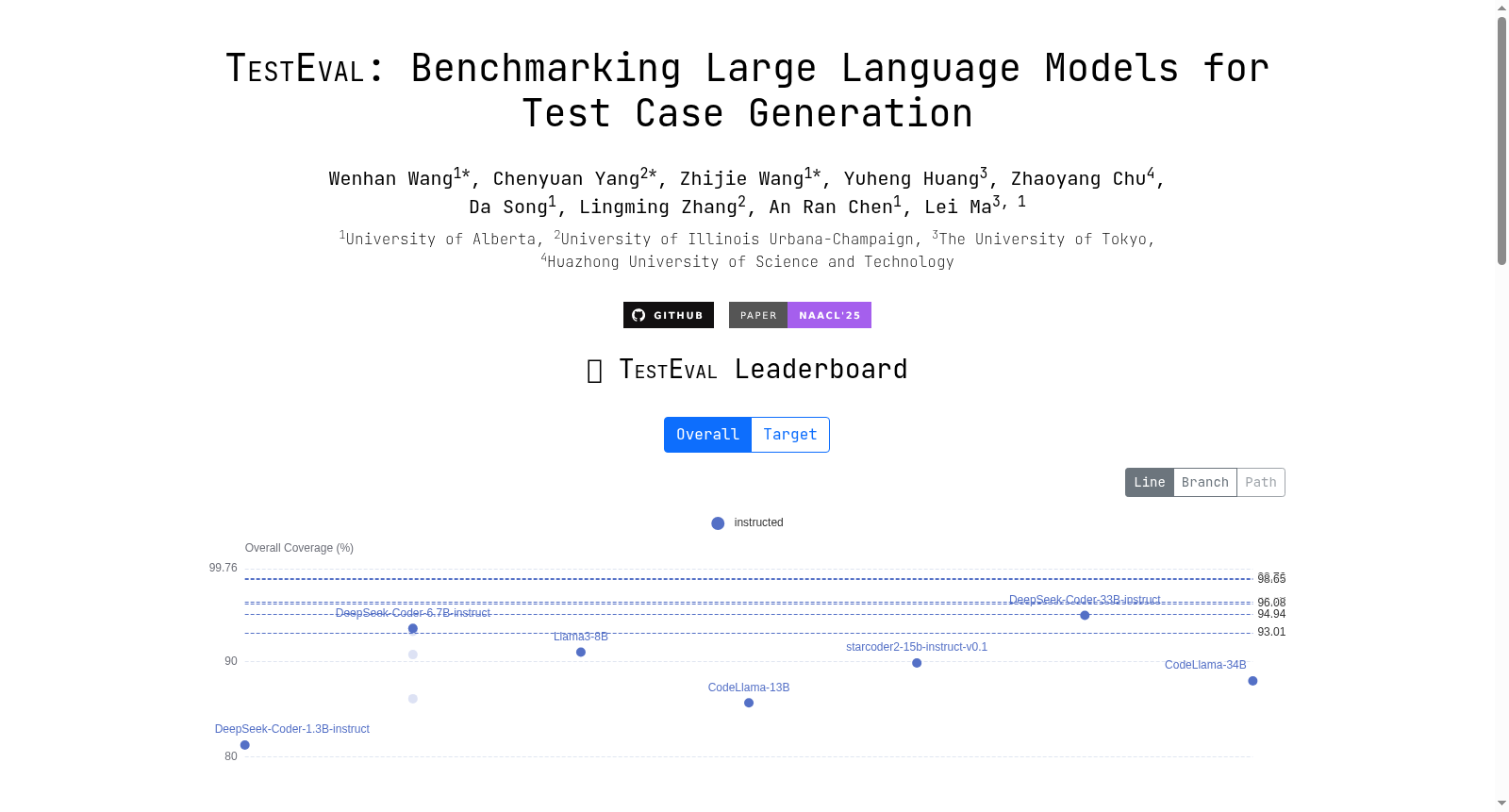
TESTEVAL是一个专注于评估大型语言模型在测试用例生成能力的基准数据集,由阿尔伯塔大学等机构创建。该数据集包含210个从LeetCode平台收集的Python程序,分为三个不同的任务:整体覆盖、目标行/分支覆盖和目标路径覆盖。数据集的创建过程涉及从LeetCode收集程序,并根据程序的复杂性进行筛选。TESTEVAL主要用于解决软件测试中自动化测试用例生成的问题,特别是在理解程序逻辑和执行路径方面。
TESTEVAL is a benchmark dataset dedicated to evaluating the test case generation capabilities of large language models (LLMs), developed by the University of Alberta and other research institutions. This dataset contains 210 Python programs collected from the LeetCode platform, and is divided into three distinct tasks: overall coverage, target line/branch coverage, and target path coverage. The construction process of TESTEVAL involves collecting programs from LeetCode and screening them based on their complexity. TESTEVAL is primarily designed to address the challenges of automated test case generation in software testing, especially in scenarios requiring understanding of program logic and execution paths.
提供机构:
阿尔伯塔大学
创建时间:
2024-06-07
搜集汇总
数据集介绍
构建方式
在软件测试领域,自动化测试用例生成一直是提升开发效率的关键挑战。TESTEVAL数据集的构建过程体现了严谨的学术设计,其核心数据来源于在线编程平台LeetCode,从中筛选出210个Python程序。这些程序经过精心预处理,包括统一代码格式、移除注释以及调整条件语句结构,以确保每行代码对应单一语句。通过计算圈复杂度,数据集排除了过于简单的程序,专注于具有复杂逻辑结构的代码。此外,针对每个程序,研究团队基于抽象语法树提取了条件分支和目标行,并利用随机生成的测试输入对分支难度进行标注,分为简单、中等和困难三个等级,从而构建了一个多层次、结构化的评估基准。
使用方法
使用TESTEVAL数据集进行评估时,研究者需遵循其标准化的流程。首先,根据不同的任务类型(整体覆盖、目标行/分支覆盖或目标路径覆盖),将程序代码和自然语言描述输入到大语言模型中,提示生成单个测试用例。每个任务都有特定的提示模板,例如在目标行覆盖任务中会明确指定需要覆盖的代码行号。生成的测试用例需经过正确性检查,包括语法正确性和执行正确性,只有通过检查的用例才会用于覆盖率计算。评估指标包括行覆盖率、分支覆盖率以及新提出的cov@k指标,后者用于衡量测试用例的多样性。整个流程支持对多种大语言模型进行公平比较,为软件测试领域的研究提供了可复现的实验框架。
背景与挑战
背景概述
在软件工程领域,自动化测试用例生成一直是提升开发效率与软件质量的核心研究课题。TESTEVAL数据集由阿尔伯塔大学、伊利诺伊大学厄巴纳-香槟分校、东京大学及华中科技大学的研究团队于2024年联合创建,旨在系统评估大语言模型在测试用例生成任务中的能力。该数据集从在线编程平台LeetCode收集了210个Python程序,并设计了整体覆盖率、目标行/分支覆盖率和目标路径覆盖率三项任务,以填补现有研究在公平比较不同大语言模型测试生成性能方面的空白。TESTEVAL的推出为软件测试与人工智能交叉领域提供了标准化评估基准,推动了基于大语言模型的智能测试工具的发展。
当前挑战
TESTEVAL所针对的测试用例生成领域面临多重挑战:其一,模型需深入理解程序逻辑与执行路径,以生成覆盖特定代码行、分支或复杂路径的测试输入,这对大语言模型的推理能力提出了较高要求;其二,在数据集构建过程中,研究团队需从数千个初始程序中筛选出具有足够圈复杂度的样本,并精确标注目标行、分支与路径,同时设计兼顾语法与执行正确性的评估指标。此外,如何平衡测试用例的多样性与针对性,以及避免模型重复生成相似测试案例,亦是该数据集旨在解决的关键难题。
常用场景
经典使用场景
在软件工程领域,自动化测试用例生成是提升开发效率与代码质量的关键环节。TESTEVAL作为专门评估大语言模型测试用例生成能力的基准,其经典使用场景聚焦于通过自然语言指令驱动模型为给定Python程序生成覆盖不同代码结构的测试输入。该数据集从LeetCode平台精选210个具有复杂控制流的程序,设计了整体覆盖率、目标行/分支覆盖率和目标路径覆盖率三大任务,模拟了从广泛探索到精准定位的测试需求。研究人员利用这一基准,能够系统评估模型在理解程序逻辑、生成多样化测试用例以及遵循特定覆盖目标方面的表现,为比较不同模型的测试生成能力提供了标准化实验环境。
解决学术问题
TESTEVAL致力于解决大语言模型在软件测试领域中缺乏公平、系统评估框架的学术问题。传统代码生成基准如HumanEval侧重于功能实现,而测试生成需深入理解程序执行路径与逻辑结构。该数据集通过设计多层次覆盖任务,首次量化评估模型在生成测试用例时对程序逻辑的推理能力,揭示了当前模型在覆盖特定行、分支或路径方面的显著不足。其贡献在于填补了LLM测试生成评估的空白,提供了可复现的度量标准,推动了针对程序理解与测试意图跟随的模型能力研究,为改进测试生成中的逻辑推理与路径分析指明了方向。
实际应用
在实际软件开发流程中,TESTEVAL的应用价值体现在加速测试自动化与提升测试精准度。开发团队可借助该基准筛选或优化适用于测试生成的大语言模型,将其集成至持续集成管道,自动为代码库生成高覆盖率的单元测试,减少人工编写测试用例的时间成本。针对关键或复杂代码段,模型可被引导生成覆盖特定分支或路径的测试,辅助定位潜在边界条件错误或隐藏缺陷。此外,该基准支持测试工具开发者验证与比较不同LLM驱动的测试生成方案,推动工业级智能测试引擎的研发,最终增强软件可靠性与维护效率。
数据集最近研究
最新研究方向
在软件测试领域,TESTEVAL数据集的推出标志着大语言模型在测试用例生成能力评估方面迈入了系统化与标准化阶段。该数据集聚焦于Python程序的测试生成,通过整体覆盖率、目标行/分支覆盖率和目标路径覆盖率三大任务,深入探索大语言模型对程序逻辑与执行路径的理解能力。前沿研究揭示,尽管当前先进模型如GPT-4o在整体覆盖率上表现卓越,但在针对特定分支或路径的测试生成中仍面临显著挑战,突显了模型在复杂程序推理方面的不足。这一发现推动了基于大语言模型的智能测试框架向更精细化的推理机制发展,例如结合上下文学习与思维链提示技术,以提升模型在测试生成中的逻辑分析与意图跟随能力。TESTEVAL的开源特性进一步加速了软件测试与人工智能交叉领域的研究进程,为构建高效、可靠的自动化测试引擎奠定了重要基础。
相关研究论文
- 1TESTEVAL: Benchmarking Large Language Models for Test Case Generation阿尔伯塔大学 · 2024年
以上内容由遇见数据集搜集并总结生成


