情感数据集
收藏魔搭社区2025-09-24 更新2025-06-14 收录
下载链接:
https://modelscope.cn/datasets/cr17784624325/Genesis
下载链接
链接失效反馈官方服务:
资源简介:
# Genesis: Multimodal Multi-Party Dataset for Emotional Causal Analysis
> Code: [GitHub](https://github.com/zRzRzRzRzRzRzR/Genesis)
> Paper: [arXiv (Comming Soon)]()
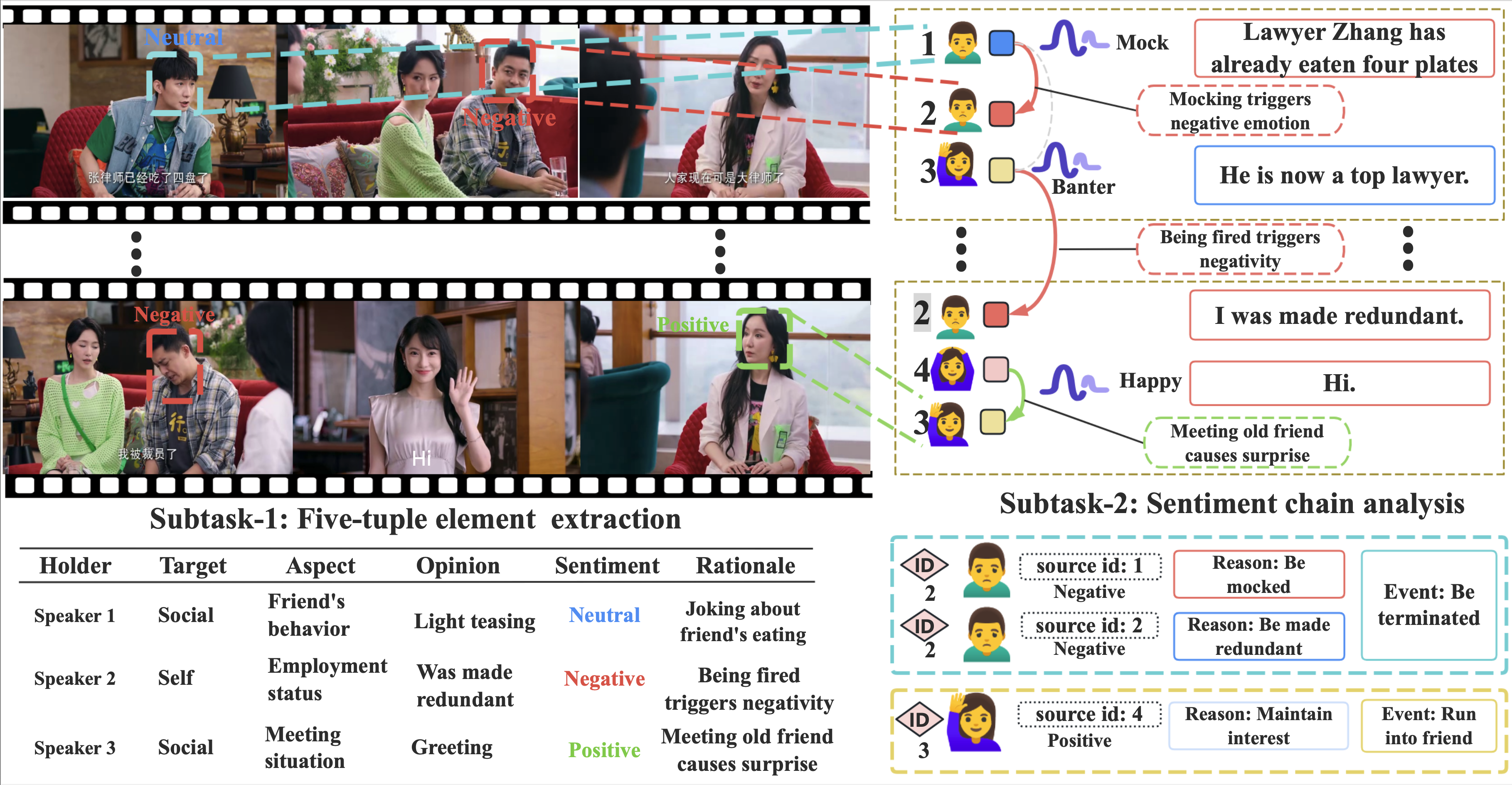
Genesis contains 1,000 dialogues (average 208 turns each) across diverse real-life settings (debate, family, education,
social). We use a two-layer annotation system to capture both immediate emotional triggers and long-term causal chains,
including cross-modal inconsistencies and long-distance emotional dependencies.
We benchmark 20 popular multimodal models and find they struggle with long-term emotional reasoning. To address this, we
propose Empathica, a new evaluation baseline using a Recognition-Memory-Attribution framework that outperforms both
text-based and multimodal models.
## Dataset Information
### Format
The dataset contains mian folders: `data` .The `data` include original text data ( `chat_*.txt` ), video data( `chat_*.mp4` ) and Causal chain data( `chat_*.json`).Each sample in the subtitle file follows the
format below:
### video data:
### causal chain data:
In order to ensure the quality of causal chain annotation, we employed the method of human alignment and cross-validation, make sure get a correct structure, source_id and no repeat event.
The two individuals review the same causal chain. By comparing the corresponding segments in the text and the video, they determine whether there are any significant errors in the emotional events within the causal chain, whether the speaker ID is missing, or whether it cannot match the ID in the original text. For emotional events, if the two parties' evaluations are consistent, there will be no dispute. If the two reviewers' results are different, the final review mechanism will be introduced, and the result of the third reviewer will be taken as the final decision.
```json
{
"1": {
"events": [
{
"event": "参加舞会相亲",
"sentence_ids": [2, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 131, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146, 147, 148, 149, 150, 151, 152, 153, 154, 155, 156, 157, 158, 159, 160, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 172, 173, 174, 175],
"emotions": [
{
"source_id": 1,
"state": "negative",
"reason": "脚扭伤无法正常跳舞感到不适"
},
{
"source_id": 7,
"state": "negative",
"reason": "被指责为何来这种地方,感到受到质疑"
},
{
"source_id": 5,
"state": "positive",
"reason": "对方主动关心并帮助自己离开"
}
]
}
}
```
### Structure
The data is stored in two folders, with 1000 files each for videos and text respectively.
The directory structure is as follows:
```plaintext
.
├── README.md
└── data
├── chat_1
├── chat_1.txt
├── chat_1.mp4
└── chat_1.json
├── chat_2
...
└── chat_1000
```
## Citation
If you find our work helpful, please consider citing the following paper.
```bibtex
Coming Soon
```
# Genesis: 用于情感因果分析的多模态(Multimodal)多对话数据集
> Code: [GitHub](https://github.com/zRzRzRzRzRzRzR/Genesis)
> Paper: [arXiv(即将上线)]()

Genesis包含1000段对话(平均每段208轮),涵盖辩论、家庭、教育、社交等多样化真实生活场景。我们采用双层标注体系,以捕捉即时情感触发因子与长期因果链条,包括跨模态不一致性与长距离情感依赖关系。
我们对20款主流多模态模型开展基准测试,发现其在长期情感推理任务中表现欠佳。为解决这一痛点,我们提出Empathica——一种基于“识别-记忆-归因”(Recognition-Memory-Attribution)框架的全新评估基准,其性能优于文本模型与多模态模型。
## 数据集信息
### 格式
本数据集包含主文件夹`data`。`data`目录下涵盖原始文本数据(`chat_*.txt`)、视频数据(`chat_*.mp4`)与因果链数据(`chat_*.json`)。字幕文件中的每个样本均遵循以下格式:
### 视频数据:
### 因果链数据:
为保障因果链标注质量,我们采用人工对齐与交叉验证的方法,确保因果链结构合规、源ID(source_id)准确且事件无重复。两名标注人员将对同一因果链进行评审,通过比对文本与视频中的对应片段,判断因果链内的情感事件是否存在显著错误、是否缺失说话人ID,或无法与原始文本中的ID匹配。对于情感事件,若两名评审意见一致则无争议;若评审结果存在分歧,则启动最终评审机制,以第三名评审的结果作为最终判定。
json
{
"1": {
"events": [
{
"event": "参加舞会相亲",
"sentence_ids": [2, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 131, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146, 147, 148, 149, 150, 151, 152, 153, 154, 155, 156, 157, 158, 159, 160, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 172, 173, 174, 175],
"emotions": [
{
"source_id": 1,
"state": "negative",
"reason": "脚扭伤无法正常跳舞感到不适"
},
{
"source_id": 7,
"state": "negative",
"reason": "被指责为何来这种地方,感到受到质疑"
},
{
"source_id": 5,
"state": "positive",
"reason": "对方主动关心并帮助自己离开"
}
]
}
}
### 数据结构
数据存储于两个文件夹中,视频与文本文件各1000份。目录结构如下:
plaintext
.
├── README.md
└── data
├── chat_1
├── chat_1.txt
├── chat_1.mp4
└── chat_1.json
├── chat_2
...
└── chat_1000
## 引用
若您的研究受益于本工作,请引用以下论文。
bibtex
Coming Soon
提供机构:
maas
创建时间:
2025-06-08
搜集汇总
数据集介绍
背景与挑战
背景概述
Genesis是一个多模态多方情感因果分析数据集,包含1000个平均208轮对话的样本,覆盖辩论、家庭、教育、社交等多种真实场景。它采用双层标注系统捕捉即时情感触发和长期因果链,并提供文本、视频和因果链数据,用于评估模型在长距离情感推理方面的能力。
以上内容由遇见数据集搜集并总结生成


