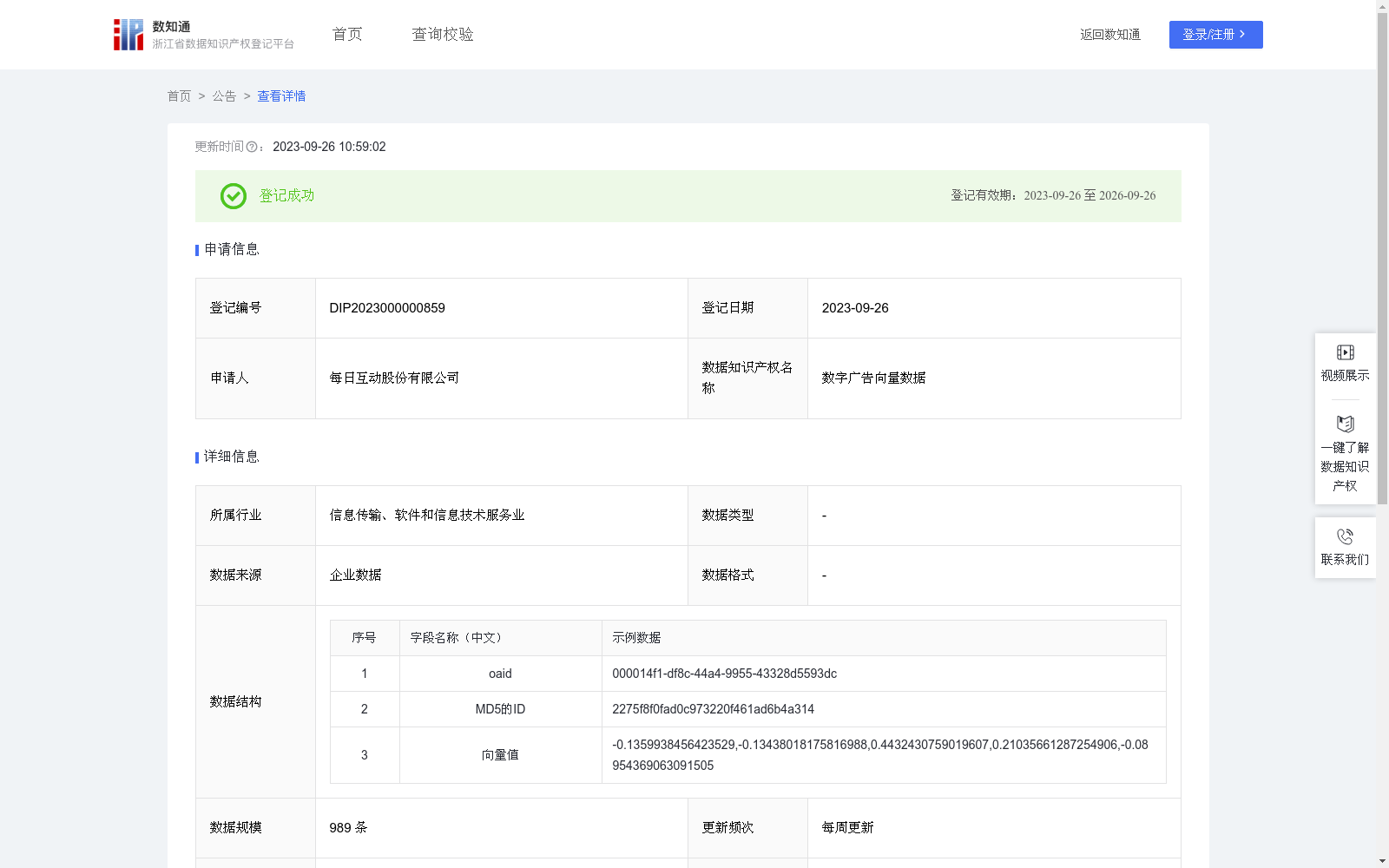
数字广告向量数据
收藏浙江省数据知识产权登记平台2023-09-26 更新2024-05-08 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/3527
下载链接
链接失效反馈官方服务:
资源简介:
依托开发者服务积累海量APP数据,利用深度学习模型,将个推大数据脱敏压缩生产脱敏后的稠密向量,助力互联网客户提升算法模型效果 推荐系统:通过比较用户向量之间的相似度,可以实现个性化推荐。根据用户的历史行为、兴趣爱好等特征,为用户推送更符合其喜好的内容、商品或服务。 广告投放:基于用户行为向量,广告商可以精准定位目标受众,针对性地投放广告,从而提高广告效果和转化率。1.数据采集:开发者服务经过用户授权,对用户最小必要的行为数据进行收集
2.数据处理:为保证内部员工的最小化授权使用,基于公司自研的每日治数平台上对数据进行数据接入,ETL清洗和脱敏去标识化。
3.算法加工:数据清洗:对采集到的用户数据进行预处理,包括去除无效数据、填补缺失值、消除异常值等,使数据更加规范和准确。数据转换:将清洗后的用户数据转换为向量形式,主要使用的方法包括独热编码、嵌入向量、主题模型等,将离散数据转换为连续的向量空间中的表示。向量空间建立:将转换后的用户向量数据构建成一个高维的向量空间,其中每个维度代表一个特征,向量的值代表该特征的值。向量空间优化:为了提高向量空间的表示能力和计算效率,需要对向量空间进行优化。常用的优化方法包括矩阵分解、降维、聚类等,将高维的向量空间进行降维或聚类,以便更好地表示用户特征和相似度计算。相似度计算:在优化后的向量空间中,可以计算用户之间的相似度,主要使用余弦相似度、欧氏距离、Jaccard相似度等算法。算法加工:利用相似度计算的结果,结合业务需求和目标函数,进行相应的算法加工(推荐算法、聚类算法、分类算法)。
4.数据应用:使用向量化能
Leveraging massive APP data accumulated through developer services and deep learning models, GeTui generates desensitized dense vectors by desensitizing and compressing its own big data, to help internet customers improve the performance of their algorithm models.
Recommendation System: Personalized recommendation can be realized by comparing the similarity between user vectors. Based on user characteristics such as historical behaviors and hobbies, content, commodities or services that better match their preferences can be pushed to users.
Advertising Delivery: Based on user behavior vectors, advertisers can accurately target their target audiences and deliver targeted advertisements, thereby improving advertising effectiveness and conversion rates.
1. Data Collection: With user authorization, developer services collect the minimum necessary user behavior data.
2. Data Processing: To ensure the minimal authorized use by internal employees, data access, ETL cleaning, desensitization and de-identification are conducted on the company's self-developed daily data governance platform.
3. Algorithm Processing:
Data Cleaning: Preprocess the collected user data, including removing invalid data, imputing missing values, and eliminating outliers, to make the data more standardized and accurate.
Data Transformation: Convert the cleaned user data into vector form. Commonly used methods include one-hot encoding, embedding vectors, topic models, etc., to transform discrete data into representations in a continuous vector space.
Vector Space Construction: Construct the converted user vector data into a high-dimensional vector space, where each dimension represents a feature, and the vector value corresponds to the value of that feature.
Vector Space Optimization: To improve the representation capability and computational efficiency of the vector space, optimization is required. Common optimization methods include matrix factorization, dimensionality reduction, clustering, etc., which reduce the dimensionality or cluster the high-dimensional vector space to better represent user features and facilitate similarity calculation.
Similarity Calculation: In the optimized vector space, the similarity between users can be calculated. Commonly used algorithms include cosine similarity, Euclidean distance, Jaccard similarity, etc.
Algorithm Refinement: Using the results of similarity calculation, combined with business requirements and objective functions, perform corresponding algorithm processing (recommendation algorithms, clustering algorithms, classification algorithms).
4. Data Application: Using vectorization can
提供机构:
每日互动股份有限公司
创建时间:
2023-09-11
搜集汇总
数据集介绍
特点
数字广告向量数据由每日互动股份有限公司提供,包含989条经过脱敏处理的稠密向量数据,每周更新。该数据集主要用于推荐系统和广告投放,通过用户行为向量实现个性化推荐和精准广告投放,提升算法模型效果。
以上内容由遇见数据集搜集并总结生成


