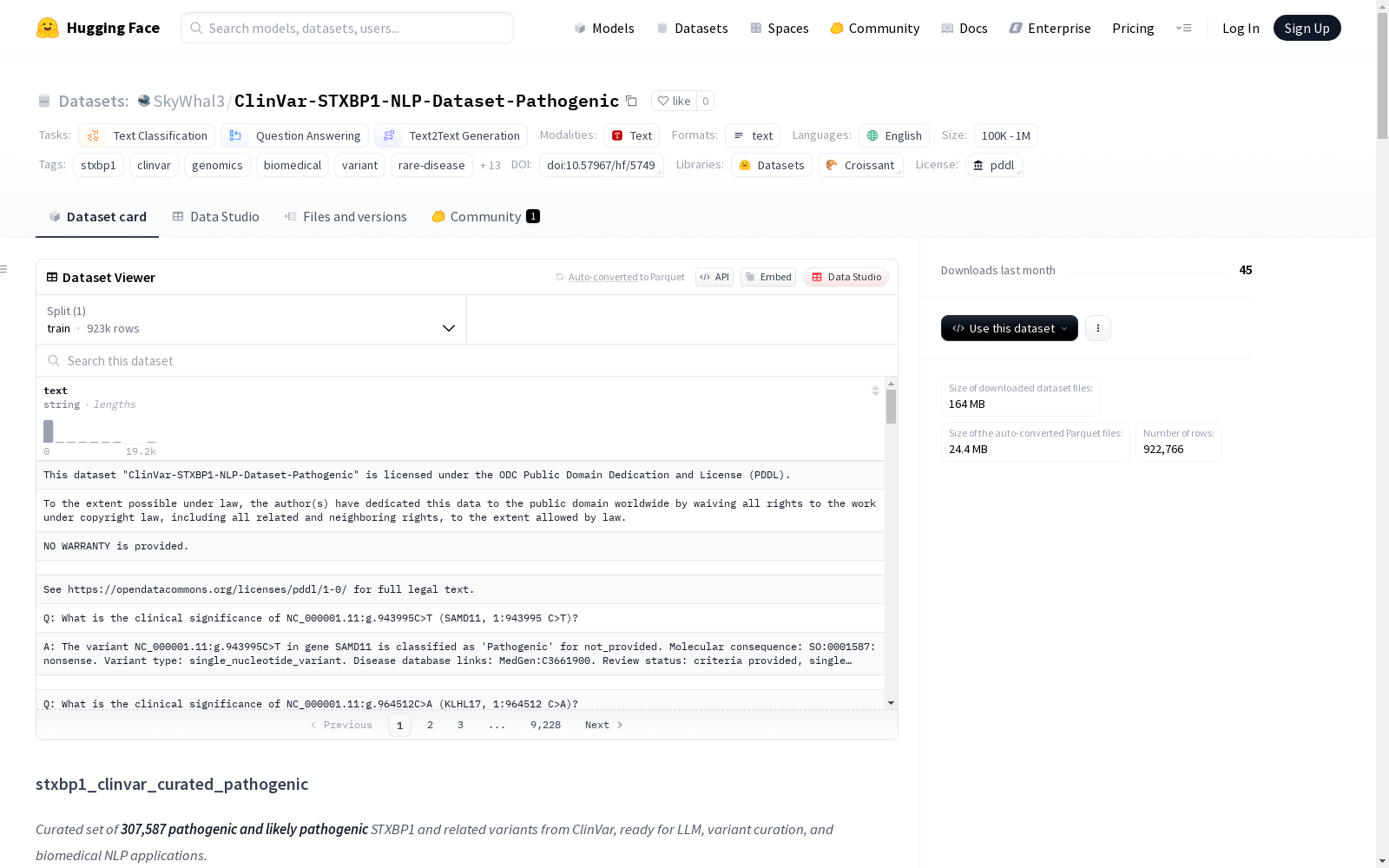
ClinVar-STXBP1-NLP-Dataset-Pathogenic
收藏STXBP1 ClinVar Pathogenic Variants (Curated) 数据集概述
数据集基本信息
- 许可证: ODC Public Domain Dedication and License (PDDL)
- 任务类别: 文本分类、问答、文本生成
- 语言: 英语
- 标签: STXBP1、ClinVar、基因组学、生物医学、变异、罕见病、神经学、癫痫、自然语言处理、大型语言模型、问答、文本分类、生物信息学、SNARE、基因编辑、CRISPR、Cas9、开放数据、指令调优
- 数据集名称: STXBP1 ClinVar Pathogenic Variants (Curated)
- 数据规模: 100K < n < 1M
数据集内容
- 数据量: 307,587个致病性和可能致病性STXBP1及相关变异
- 数据来源: ClinVar
- 数据格式: JSONL(主格式)、Q/A对(TXT)、Parquet(推荐大规模使用)
数据筛选标准
- 临床意义: Pathogenic或Likely_pathogenic
- 基因家族: STXBP1、MUNC18、STXBP2、STXBP3、STXBP4、STXBP5、STXBP6
- 相关关键词: SNARE复合体、CRISPR、神经系统疾病
数据集特征
- 自然语言临床摘要: 每个变异的临床摘要
- 结构化JSONL: 兼容Parquet,适用于数据科学和自然语言处理
- Q/A对: 用于大型语言模型训练和评估
- 完整覆盖: 变异、基因、疾病、临床意义、HGVS、数据库链接、审查状态等
数据集统计
| 格式 | 大小(字节) | 示例/行数 |
|---|---|---|
| QA (.txt) | 163,561,472 | 615,174 |
| JSONL | 157,364,224 | 307,587 |
数据模式
| 字段 | 描述 |
|---|---|
| ID | ClinVar变异ID |
| chrom | 染色体 |
| pos | 基因组位置(GRCh38) |
| ref | 参考等位基因 |
| alt | 替代等位基因 |
| gene | 基因符号 |
| disease | 疾病/表型名称 |
| significance | 临床意义(如Pathogenic、Likely_pathogenic) |
| hgvs | HGVS变异描述 |
| review | ClinVar审查状态 |
| molecular_consequence | 序列本体论+效应 |
| variant_type | SNV、插入、删除等 |
| clndisdb | 疾病数据库链接(OMIM、MedGen等) |
| clndnincl | 包含的变异疾病名称 |
| clndisdbincl | 包含的变异疾病数据库链接 |
| onc_fields | 致癌性字段字典 |
| sci_fields | 体细胞临床影响字段字典 |
| incl_fields | 包含字段字典(INCL) |
数据示例
json { "ID": "3385321", "chrom": "1", "pos": "66926", "ref": "AG", "alt": "A", "gene": "STXBP1", "disease": "Developmental and epileptic encephalopathy, 4", "significance": "Pathogenic", "hgvs": "NC_000001.11:g.66927del", "review": "criteria_provided, single_submitter", "molecular_consequence": "SO:0001627: intron_variant", "variant_type": "Deletion", "clndisdb": "Human_Phenotype_Ontology:HP:0000547,MONDO:MONDO:0019200,MeSH:D012174,MedGen:C0035334,OMIM:268000", "clndnincl": null, "clndisdbincl": null, "onc_fields": {}, "sci_fields": {}, "incl_fields": {} }
数据加载方法
-
使用🤗 Datasets库加载: python from datasets import load_dataset ds = load_dataset("SkyWhal3/ClinVar-STXBP1-NLP-Dataset", data_files="ClinVar-STXBP1-NLP-Dataset.jsonl", split="train") print(ds[0])
-
转换为Parquet格式: python import pandas as pd df = pd.read_json("ClinVar-STXBP1-NLP-Dataset.jsonl", lines=True) df.to_parquet("ClinVar-STXBP1-NLP-Dataset.parquet")
创建者
Adam Freygang, A.K.A. SkyWhal3
许可证信息
- 许可证类型: ODC Public Domain Dedication and License (PDDL)
- 许可证链接: https://opendatacommons.org/licenses/pddl/1-0/