superkart-sales-forecast
收藏Hugging Face2026-05-18 更新2026-05-21 收录
下载链接:
https://huggingface.co/datasets/vikashHugFace/superkart-sales-forecast
下载链接
链接失效反馈官方服务:
资源简介:
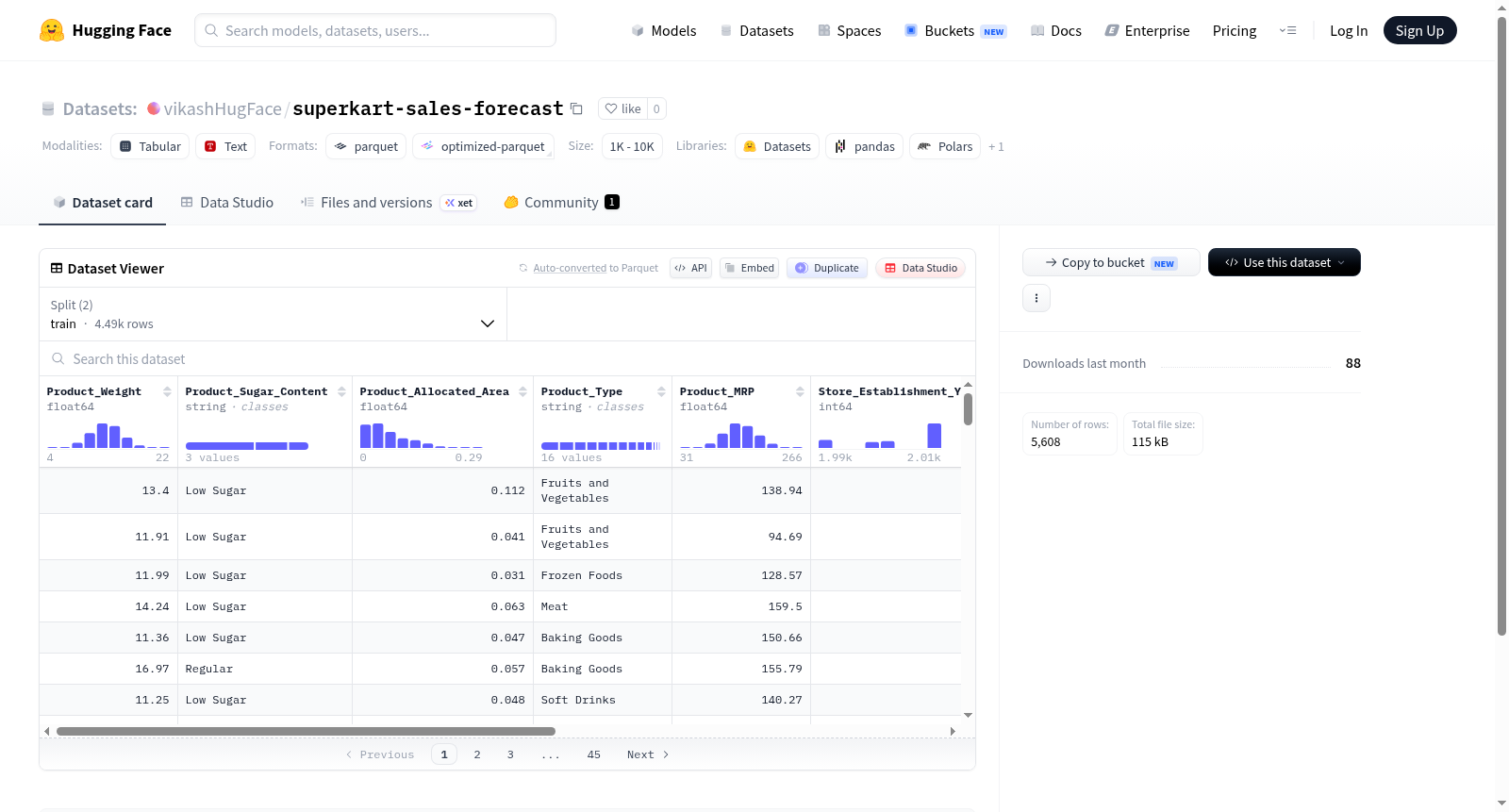
该数据集包含零售场景下的产品与商店信息,旨在支持销售预测或分析任务。数据由10个字段构成,涵盖产品属性(包括重量、含糖量、分配区域、类型、建议零售价)、商店属性(包括成立年份、规模、位置城市类型、类型)以及目标变量“产品商店销售总额”。数据集总大小约为601KB,包含5,608个样本,并已划分为训练集(4,486个样本)和测试集(1,122个样本)。数据以结构化表格形式存储,适用于机器学习模型训练与评估,特别是回归或分类任务。
This dataset contains product and store information in retail scenarios, designed to support sales forecasting or analysis tasks. The data consists of 10 fields, covering product attributes (including weight, sugar content, distribution area, type, suggested retail price), store attributes (including establishment year, size, location city type, type), and the target variable total product store sales. The total dataset size is approximately 601KB, containing 5,608 samples, and is divided into a training set (4,486 samples) and a test set (1,122 samples). The data is stored in structured table format, suitable for machine learning model training and evaluation, particularly for regression or classification tasks.
创建时间:
2026-05-16
搜集汇总
数据集介绍
构建方式
在零售业销售预测领域,数据集的构建常基于历史交易记录与产品属性特征的融合。superkart-sales-forecast数据集整合了来自大型零售连锁超市的脱敏销售数据,通过从商品层面与门店层面双重维度进行特征提取,最终形成了包含产品重量、含糖量、分配面积、产品类型、最高零售价(MRP)、门店建立年份、门店规模、所在城市类型及门店类型等十个特征字段的结构化数据集。数据集采用随机抽样划分策略,将原始样本按照8:2的比例分割为训练集与测试集,分别包含4486条和1122条记录,确保模型训练与评估的独立性与客观性。
特点
该数据集的核心特点在于其多维度的特征构成与实用性导向。在预测目标上,它聚焦于'产品-门店销售总量'这一关键业务指标,为时间序列或回归型预测模型提供基准。特征空间涵盖了产品本身属性(如重量、糖分、类型与定价)、门店经营特征(如成立年份、规模、区位类型)以及两者之间的交互关系,这种多层级特征设计使得模型能够捕捉到影响销售的复杂因素。此外,数据集在规模上适中,训练集大小仅为约469KB,既避免了因数据过小导致的过拟合风险,又降低了计算资源门槛。
使用方法
该数据集的设计初衷是服务于零售销量预测模型的训练与评估,尤其适用于回归分析或基于决策树的集成学习方法。用户可通过Hugging Face Datasets库直接加载数据集,利用默认配置一次性获取划分好的训练集和测试集。在建模过程中,可将产品属性与门店特征作为输入特征,以产品-门店销售总量作为回归目标,构建如随机森林、梯度提升机或全连接神经网络等预测模型。为优化预测精度,建议对数值型特征进行标准化处理,并对类别型特征进行独热编码或标签编码,同时可利用数据集的覆盖范围进行特征重要性分析与业务洞察。
背景与挑战
背景概述
在零售与供应链管理领域,准确预测产品销售对于库存优化、资源分配及盈利能力提升具有举足轻重的作用。superkart-sales-forecast数据集由数据科学社区创建,旨在为多变量时间序列预测提供一个标准化的基准测试平台。该数据集整合了产品属性(如重量、糖分含量、分配区域、类型和最高零售价)与店铺特征(如成立年份、规模、所在城市类型和业态),共计10个特征变量,并通过训练集(4486条样本)与测试集(1122条样本)的划分,支持有监督学习任务的开发与评估。其核心研究问题聚焦于如何融合异构的静态属性与动态销售数据,以提升销售预测的准确性与鲁棒性。该数据集的发布填补了中小规模零售场景下结构化销售预测数据集的空白,为相关领域的研究者和从业者提供了可复现的实证基础。
当前挑战
该数据集所解决的领域核心挑战在于零售销售预测中多因子交互效应的复杂建模,例如产品类型与店铺地理位置的协同影响、促销或季节性因素在有限特征下的非显式表达,使得传统统计模型难以捕捉非线性模式。在构建过程中,数据集面临的数据质量挑战包括:原始销售记录中可能存在的缺失值(如产品重量或店铺规模未记录)、字符串特征(如糖分含量、店铺类型)的语义一致性标准化,以及销售总量分布的长尾效应,这些都需要针对性的清洗与变换策略。此外,样本量相对较小(总计5608条)限制了深度模型的直接应用,如何在小样本场景下避免过拟合,并保障预测模型的泛化能力,成为评估该数据集使用成效的关键难点。
常用场景
经典使用场景
在零售与快消品领域,销售量预测是供应链优化与库存管理的核心环节。superkart-sales-forecast数据集汇聚了产品属性(如重量、含糖量、MRP)与门店特征(如成立年份、规模、所在城市类型)等多维信息,为构建回归或时间序列预测模型提供了丰富特征。研究者可借此探索产品特征与门店环境如何共同影响销售表现,经典应用包括基于树模型的销量回归、深度学习中的特征交互分析,以及通过交叉验证评估不同产品类别在异构门店中的预测稳定性。
解决学术问题
该数据集有效回应了零售科学中“多源异构特征如何协同提升预测精度”这一学术难题。通过整合产品固有属性(如类型、含糖量)与门店经营背景(如区域类型、成立年限),研究者得以量化不同维度特征对销售波动的贡献度,并检验模型在稀疏类别(如小众产品类型)上的泛化能力。这为特征工程策略、异常销售检测以及促销效果归因等研究方向提供了可复现的基准,推动了零售预测领域从单一变量建模向多因素融合分析的范式演进。
衍生相关工作
围绕此数据集,研究者已衍生出多项具有启发性的工作。一方面,基于产品与门店的交叉特征,学者构建了轻量级梯度提升模型(如LightGBM)与神经网络混合架构,用于对比传统统计方法与深度学习的预测性能。另一方面,部分工作引入销售数据的时空分解视角,将门店选址与产品生命周期结合,开发出可解释的销售波动诊断工具。此外,该数据集也常被用作特征选择算法的验证基准,通过评估不同特征子集对预测误差的消除效果,推动了零售领域自动化特征工程的进步。
以上内容由遇见数据集搜集并总结生成


