potomitan-gcf-fr-translation
收藏Hugging Face2025-05-12 更新2025-05-13 收录
下载链接:
https://huggingface.co/datasets/GwadaDLT/potomitan-gcf-fr-translation
下载链接
链接失效反馈官方服务:
资源简介:
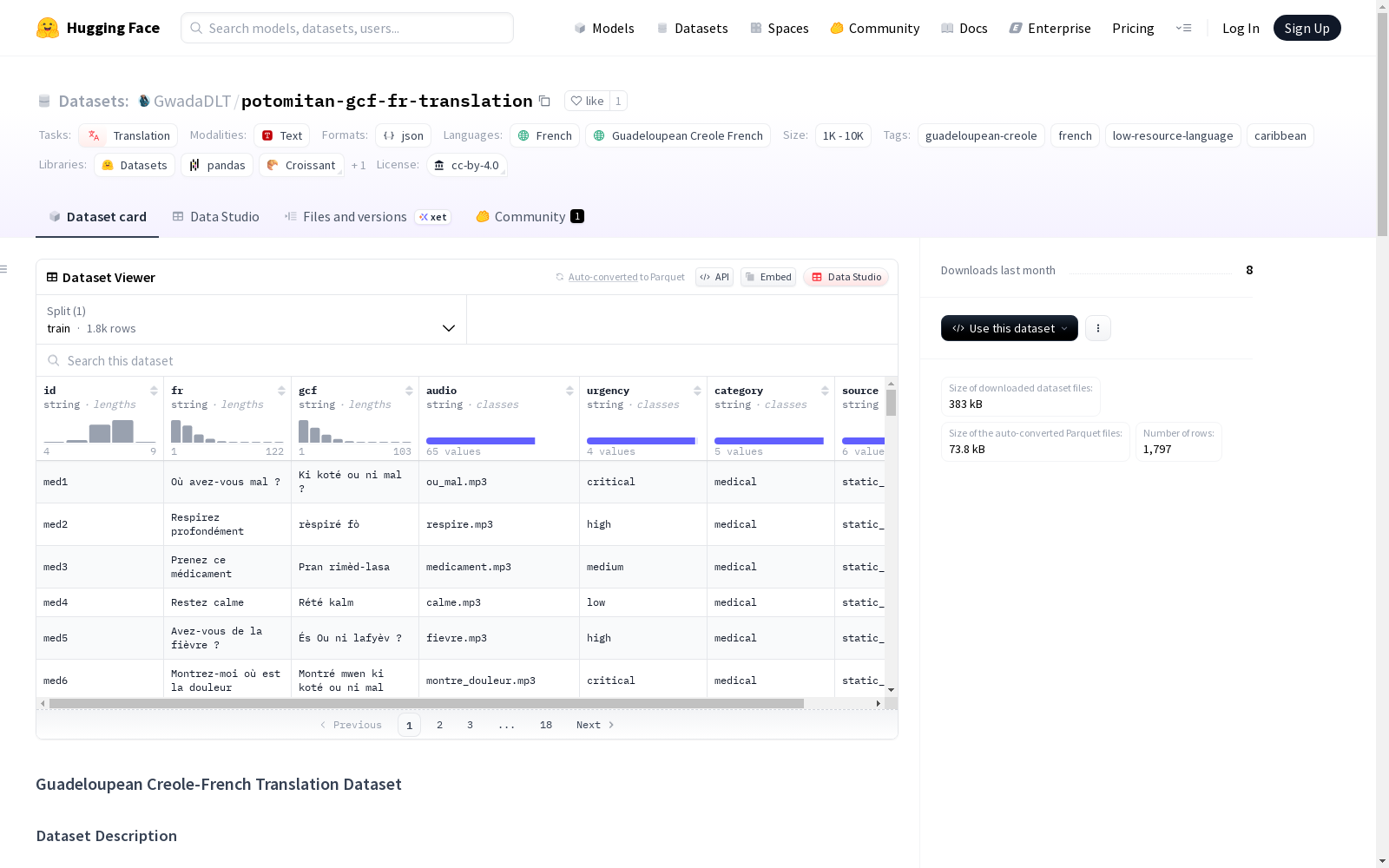
瓜德罗普克里奥尔语-法语翻译数据集包含2,058对翻译,涵盖紧急情况、语言课程、自然灾害、基本需求等多个类别。数据集以JSON格式存储,可用于机器翻译、语言学习、紧急响应等。
创建时间:
2025-05-12
原始信息汇总
瓜德罗普克里奥尔语-法语翻译数据集
数据集描述
- 包含2058个法语与瓜德罗普克里奥尔语(Kreyòl Gwadloup)的翻译对
- 属于POTOMITAN项目的一部分
语言
- 法语 (fr)
- 瓜德罗普克里奥尔语 (gcf)
数据集结构
- 格式:JSON
- 结构示例: json [ { "id": 1, "fr": "French text", "gcf": "Creole text", "section": "category", "emergency_context": boolean } ]
字段说明
id: 唯一标识符fr: 法语文本gcf: 瓜德罗普克里奥尔语翻译文本section: 类别(如assimil_lesson, medical_emergency等)emergency_context: 布尔值,表示是否为紧急相关内容
统计信息
- 总翻译对数量:2,058
- 紧急上下文数量:9
- 类别数量:多个(包括assimil_lesson, medical_emergency, natural_disaster, basic_needs)
数据来源
- Assimil语言课程
- 紧急短语翻译
- 常见会话表达
潜在应用
- 机器翻译系统
- 语言学习应用
- 应急响应系统
- 文化保护计划
- 语言学研究
使用示例
python import json
with open(gcf_fr_translation_dataset.json, r, encoding=utf-8) as f: data = json.load(f)
for pair in data[pairs]: print(f"French: {pair[fr]}") print(f"Creole: {pair[gcf]}")
引用
@dataset{potomitan_gcf_fr_2024, title={Guadeloupean Creole-French Translation Dataset}, author={POTOMITAN Project}, year={2024}, publisher={Hugging Face} }
许可证
- CC BY 4.0
联系方式
- GitHub: https://github.com/Brdcie/creoles-translation
致谢
- 感谢所有帮助收集和验证这些翻译的贡献者
搜集汇总
数据集介绍
构建方式
作为加勒比地区语言资源保护的重要成果,该数据集通过系统整合多种权威来源构建而成。其核心素材来源于阿西米尔语言教材的规范课程内容,同时收录了应急场景下的专业短语翻译,并补充了日常会话中的常用表达。数据采集过程特别注重语境多样性,涵盖了医疗救助、自然灾害、基础需求等多个关键领域,最终形成包含2058个翻译对的结构化语料库。
特点
该数据集最显著的特征在于其聚焦于低资源语言保护,专门收录瓜德罗普克里奥尔语与法语的对应翻译。每个语条不仅包含文本对照,还配有克里奥尔语发音的音频文件,并标注了紧急程度分级和主题分类标签。数据集特别强化了应急场景的覆盖范围,包含9类紧急语境数据,为语言技术在实际应用场景中的部署提供了重要支撑。
使用方法
在技术应用层面,使用者可通过标准JSON格式便捷地访问数据集内容。每个翻译单元均以结构化形式存储,包含完整的元数据信息。典型应用流程包括加载数据文件后遍历翻译对,分别提取法语原文和克里奥尔语译文,同时可调用音频资源进行多模态学习。该数据集特别适用于构建机器翻译系统、开发语言学习工具以及应急响应系统中的语言处理模块。
背景与挑战
背景概述
在低资源语言保护与数字化的全球背景下,POTOMITAN项目于2025年发布了瓜德罗普克里奥尔语-法语平行语料库。该数据集由POTOMITAN研究团队构建,聚焦加勒比地区濒危克里奥尔语种的机器翻译与文化遗产保存问题。通过整合医疗急救、自然灾害等关键领域的双语对照文本,该资源为语言技术模型在低资源场景下的开发提供了重要支撑,同时推动了小语种在人工智能时代的应用生态建设。
当前挑战
该数据集面临双重挑战:在领域问题层面,低资源克里奥尔语存在语法结构变异性和文化特定表达,导致传统神经机器翻译模型面临语义对齐困难与领域适应性不足;在构建过程中,受限于濒危语言母语者稀缺,数据采集需依赖有限的口述史料与专业译者协作,同时医疗等专业领域的术语一致性验证需要跨学科专家的反复校准。
常用场景
经典使用场景
在低资源语言处理领域,该数据集为瓜德罗普克里奥尔语与法语之间的机器翻译任务提供了关键支持。其平行语料覆盖医疗急救、自然灾害等多元场景,尤其适用于构建面向加勒比地区的双语翻译模型,有效缓解了克里奥尔语数据稀缺的困境。
实际应用
基于该数据集开发的翻译系统可直接部署于加勒比地区的应急响应体系,实现急救指导与灾情信息的实时本地化传递。在文化保护层面,其音频资源与方言文本为克里奥尔语教学应用提供了核心素材,支撑社区语言活力的可持续维系。
衍生相关工作
受此数据集启发,学界已涌现多项克里奥尔语神经机器翻译研究,其中部分工作聚焦于多模态翻译模型开发,结合音频特征提升低资源语言理解能力。相关成果进一步推动了《加勒比语言资源库》等区域性语料库的构建,形成良性学术生态。
以上内容由遇见数据集搜集并总结生成


