TIME
收藏Hugging Face2025-05-23 更新2025-05-24 收录
下载链接:
https://huggingface.co/datasets/SylvainWei/TIME
下载链接
链接失效反馈官方服务:
资源简介:
TIME是一个多级别的时间推理基准测试,包含38,522个问答对,涵盖知识密集型场景、动态事件和多会话交互场景的时间推理。它分为TIME-Wiki、TIME-News和TIME-Dial三个子数据集,并提供了人工注释的子集TIME-Lite。
创建时间:
2025-05-15
原始信息汇总
⏳TIME: 多层级时序推理基准数据集
📌 数据集概述
- 名称: TIME (Temporal Reasoning in Multi-level Environments)
- 规模: 38,522个问答对(含943个高质量人工标注子集TIME-Lite)
- 类型: 多层级时序推理评估基准
- 领域: 自然语言处理/时序推理
🌟 核心特点
-
多层级任务设计:
- Level 1: 基础时序理解与检索
- Level 2: 时序表达式推理
- Level 3: 复杂时序关系推理
-
三大子数据集:
- TIME-Wiki: 知识密集型场景(基于Wikidata)
- TIME-News: 动态新闻事件场景
- TIME-Dial: 多会话交互场景
📊 数据统计
| 数据集 | 总问答对数 | 子任务分布 (11类) |
|---|---|---|
| TIME | 38,522 | 详见任务缩写表 |
| TIME-Wiki | 13,848 | |
| TIME-News | 19,958 | |
| TIME-Dial | 4,716 | |
| TIME-Lite | 943 |
🛠️ 构建方法
- 数据来源: Wikidata/新闻时间线/对话数据集(LoCoMo, RealTalk)
- 生成方式: 规则模板+LLM生成(DeepSeek-V3/R1)
- 质量保证: 人工验证的高质量子集TIME-Lite
🎯 应用场景
- 评估LLMs在不同复杂度下的时序推理能力
- 研究知识密集型/动态事件/多会话交互场景的时序理解
- 建立时序推理标准化评估基准
📚 资源链接
- GitHub代码库: https://github.com/sylvain-wei/TIME
- 项目主页: https://omni-time.github.io
- 论文地址: https://arxiv.org/pdf/2505.12891
✍️ 引用格式
bibtex @article{wei2025time, title={TIME: A Multi-level Benchmark for Temporal Reasoning of LLMs in Real-World Scenarios}, author={Wei, Shaohang and Li, Wei and Song, Feifan and Luo, Wen and Zhuang, Tianyi and Tan, Haochen and Guo, Zhijiang and Wang, Houfeng}, journal={arXiv preprint arXiv:2505.12891}, year={2025} }
搜集汇总
数据集介绍
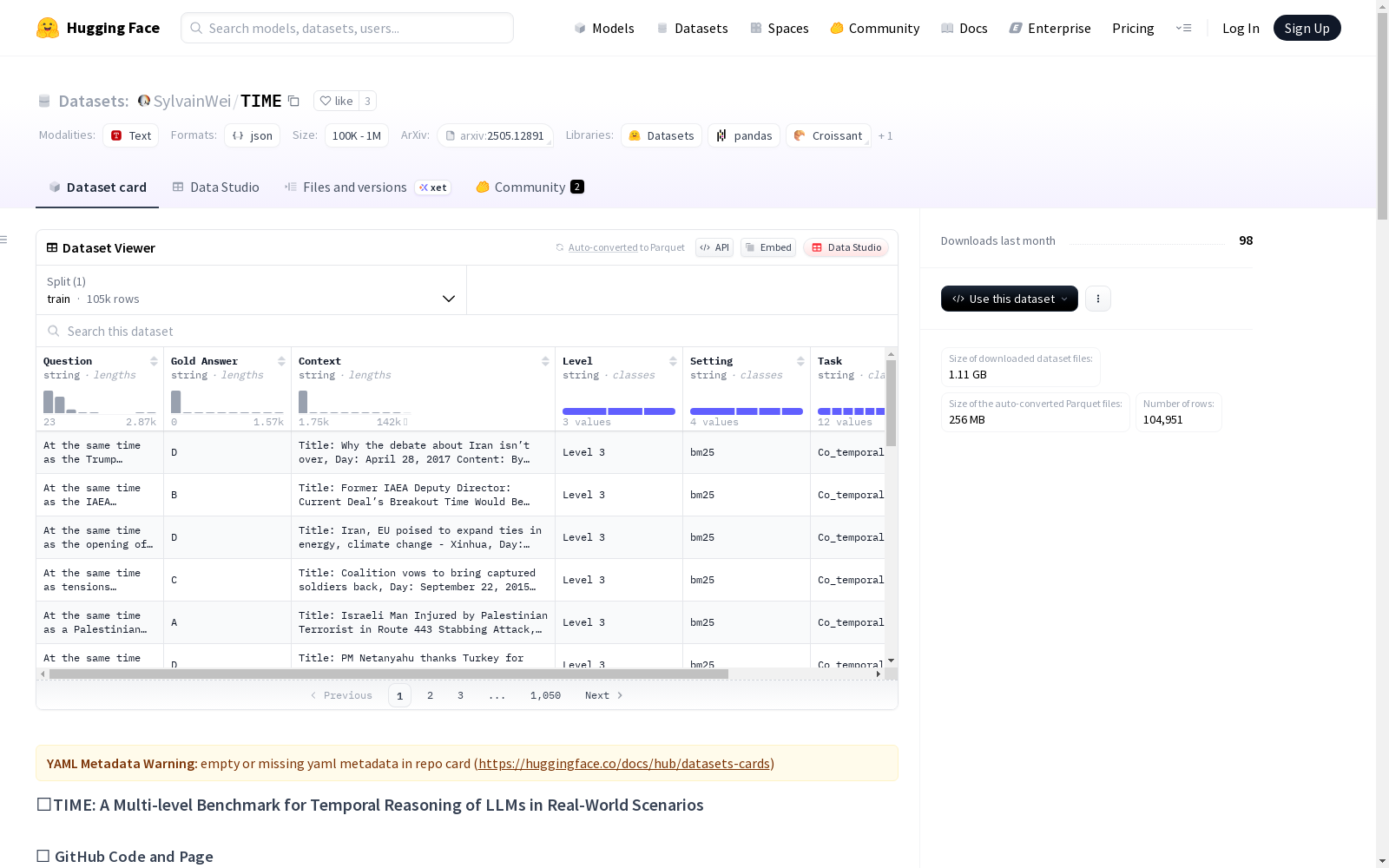
构建方式
在构建时序推理基准数据集的过程中,TIME采用了多源数据融合的策略,从Wikidata知识库、在线新闻时间线和多轮对话语料中提取真实场景的时序信息。通过构建时序知识图谱和事件演化链条,结合规则模板与大语言模型生成技术,系统性地合成了涵盖三个难度层级和十一类子任务的问答对。为确保数据质量,研究团队还专门标注了人工验证的子集TIME-Lite,为时序推理研究提供了可靠的基础资源。
特点
该数据集最显著的特征在于其多层次的任务架构设计,全面覆盖了基础时序理解、时序表达式推理和复杂时序关系三大认知层级。通过融合知识密集型场景、动态事件演化和长对话依赖三大真实挑战,数据集呈现出丰富的时序推理维度。38,522对问答数据与943对精标注子集的组合,既保证了评估的广度,又提供了精准验证的可能,为大型语言模型的时序认知能力评估建立了新的标准。
使用方法
研究者可借助该数据集开展多维度评估实验,通过三个子数据集分别检验模型在静态知识时序推理、动态事件追踪和社交交互时序依赖等场景的表现。评估体系采用渐进式设计,从基础的时间点提取到复杂的反事实推理,全面衡量模型的时序认知深度。特别提供的检索增强生成设置和人工标注子集,为不同研究需求提供了灵活的实验方案,推动时序推理研究的标准化进程。
背景与挑战
背景概述
随着大型语言模型在自然语言处理领域的广泛应用,其时间推理能力成为衡量智能水平的关键指标。TIME数据集由研究团队于2025年创建,旨在构建覆盖现实场景的多层次时序推理基准。该数据集通过整合维基知识库、新闻事件流与多轮对话数据,形成包含38,522组问答对的评估体系,有效填补了现有基准在复杂时序关系建模方面的空白。其三级任务架构从基础时间表达识别延伸至复杂事件关系推演,为模型在动态社会环境中的时序认知能力评估提供了标准化框架。
当前挑战
时序推理领域长期面临三大核心挑战:世界知识中密集时序信息的提取难题、快速演变事件动态的追踪困境,以及多轮对话中复杂时序依赖的解析瓶颈。在数据集构建过程中,研发团队需攻克多源异构数据的时序对齐技术,通过规则模板与大语言模型协同生成高质量问答对。针对新闻事件的瞬时性特征,设计了时序复杂事件建模机制;面对超长对话的上下文依赖,创新性地构建了多会话时序推理单元。这些技术突破为真实场景下的时序推理研究奠定了坚实基础。
常用场景
经典使用场景
在时序推理研究领域,TIME数据集作为多层级基准测试工具,被广泛用于评估大语言模型对现实场景中时间信息的理解能力。该数据集通过维基知识库、新闻事件流和长对话三种情境,系统检验模型从基础时间表达式提取到复杂事件关系推演的全方位表现,为时序认知研究提供了标准化评估框架。
解决学术问题
该数据集有效解决了时序推理研究中三个关键难题:知识密集型场景中的时间事实嵌入问题、动态事件细节的时序演化追踪问题,以及长对话中复杂时间依赖关系的解析问题。通过构建包含38522个问答对的多层次任务体系,填补了现有基准在真实场景时序推理深度评估方面的空白。
衍生相关工作
基于TIME基准已催生多项重要研究,包括时序增强的检索增强生成架构、多粒度时序表示学习方法,以及针对长文档时序推理的专用模型设计。其轻量化子集TIME-Lite更成为时序推理模型快速验证的标准工具,推动着该领域研究范式的标准化进程。
以上内容由遇见数据集搜集并总结生成


