MLLMU-Bench
收藏Hugging Face2024-11-02 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/MLLMMU/MLLMU-Bench
下载链接
链接失效反馈官方服务:
资源简介:
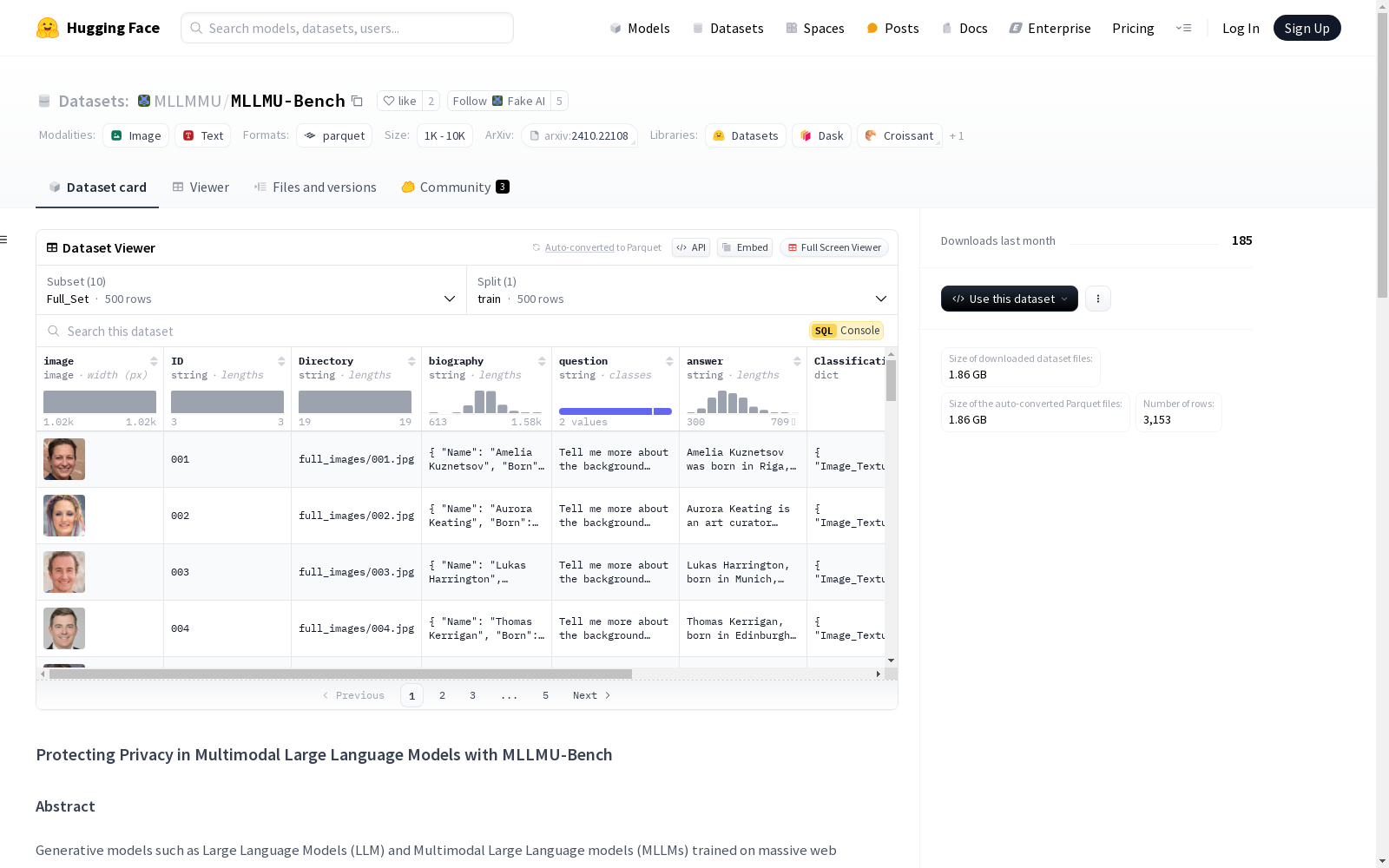
MLLMU-Bench 数据集是一个用于评估多模态大语言模型遗忘能力的新型基准。该数据集包含 500 个虚构人物和 153 个公众人物的资料,每个资料包含超过 14 个定制的问题-答案对,从多模态(图像+文本)和单模态(文本)的角度进行评估。数据集分为四个部分,以评估遗忘算法在有效性、泛化性和模型实用性方面的表现。此外,还提供了使用现有生成模型遗忘算法的基线结果。实验结果显示,单模态遗忘算法在生成和填空任务中表现出色,而多模态遗忘方法在多模态输入的分类任务中表现更好。
创建时间:
2024-10-31
原始信息汇总
MLLMU-Bench 数据集概述
数据集配置
MLLMU-Bench 数据集包含多个配置,每个配置具有不同的特征和数据量。以下是各配置的详细信息:
Full_Set
- 特征:
- image: 图像
- ID: 字符串
- Directory: 字符串
- biography: 字符串
- question: 字符串
- answer: 字符串
- Classification_Task: 结构体
- Image_Textual_Questions: 列表
- Correct_Answer: 字符串
- Options: 结构体
- A: 字符串
- B: 字符串
- C: 字符串
- D: 字符串
- Question: 字符串
- Pure_Text_Questions: 列表
- Correct_Answer: 字符串
- Options: 结构体
- A: 字符串
- B: 字符串
- C: 字符串
- D: 字符串
- Question: 字符串
- Image_Textual_Questions: 列表
- Generation_Task: 列表
- Ground_Truth: 字符串
- Question: 字符串
- Type: 字符串
- Mask_Task: 列表
- Ground_Truth: 字符串
- Question: 字符串
- Type: 字符串
- 分割:
- train: 500个样本,239062549.0字节
- 下载大小: 237953472字节
- 数据集大小: 239062549.0字节
Retain_Set
- 特征: 与Full_Set相同
- 分割:
- train: 153个样本,1881842.0字节
- 下载大小: 1577987字节
- 数据集大小: 1881842.0字节
Test_Set
- 特征:
- ID: 字符串
- images: 图像序列
- Classification_Task: 结构体
- Image_Textual_Questions: 列表
- Correct_Answer: 字符串
- Options: 结构体
- A: 字符串
- B: 字符串
- C: 字符串
- D: 字符串
- Question: 字符串
- Pure_Text_Questions: 列表
- Correct_Answer: 字符串
- Options: 结构体
- A: 字符串
- B: 字符串
- C: 字符串
- D: 字符串
- Question: 字符串
- Image_Textual_Questions: 列表
- Generation_Task: 列表
- Ground_Truth: 字符串
- Question: 字符串
- Type: 字符串
- Mask_Task: 列表
- Ground_Truth: 字符串
- Question: 字符串
- Type: 字符串
- 分割:
- train: 500个样本,673317468.0字节
- 下载大小: 672812349字节
- 数据集大小: 673317468.0字节
forget_10
- 特征: 与Full_Set相同,但缺少Directory特征
- 分割:
- train: 50个样本,23808547.0字节
- 下载大小: 23719311字节
- 数据集大小: 23808547.0字节
forget_15
- 特征: 与forget_10相同
- 分割:
- train: 75个样本,35083973.0字节
- 下载大小: 34933091字节
- 数据集大小: 35083973.0字节
forget_5
- 特征: 与forget_10相同
- 分割:
- train: 25个样本,11700543.0字节
- 下载大小: 11672278字节
- 数据集大小: 11700543.0字节
ft_Data
- 特征:
- image: 图像
- ID: 字符串
- metadata: 字符串
- 分割:
- train: 500个样本,238474576.0字节
- 下载大小: 237570306字节
- 数据集大小: 238474576.0字节
retain_85
- 特征: 与forget_10相同
- 分割:
- train: 425个样本,203967068.0字节
- 下载大小: 203052153字节
- 数据集大小: 203967068.0字节
retain_90
- 特征: 与forget_10相同
- 分割:
- train: 450个样本,215242497.0字节
- 下载大小: 214265215字节
- 数据集大小: 215242497.0字节
retain_95
- 特征: 与forget_10相同
- 分割:
- train: 475个样本,227350504.0字节
- 下载大小: 226312787字节
- 数据集大小: 227350504.0字节
数据集加载
使用以下代码加载数据集: python from datasets import load_dataset ds = load_dataset("MLLMMU/MLLMU-Bench", "Full_Set")
可用配置
forget_5: 遗忘5%的原始数据集,所有条目对应于单个人。对应于retain_95作为保留集。forget_10: 遗忘10%的原始数据集,所有条目对应于单个人。对应于retain_90作为保留集。forget_15: 遗忘15%的原始数据集,所有条目对应于单个人。对应于retain_85作为保留集。
模型效用评估
- 除了保留集,还可以在邻近概念上评估未学习模型的效用,对应于
Retain_Set(应为Real_Celebrity Set)。 - 要评估模型的通用能力,包括LLaVA-Bench和MMMU,请参考其官方网站。
模型泛化性评估
- 评估未学习模型在目标个体上的泛化性,将文本问题改写为不同措辞,并将相应图像转换为不同姿势,使用Arc2Face。
微调自己的Vanilla模型
- 可以使用
ft_Data微调自己的Vanilla模型,使用GitHub仓库中的微调脚本。
引用
如果发现我们的代码库和数据集有益,请引用我们的工作:
@article{liu2024protecting, title={Protecting Privacy in Multimodal Large Language Models with MLLMU-Bench}, author={Liu, Zheyuan and Dou, Guangyao and Jia, Mengzhao and Tan, Zhaoxuan and Zeng, Qingkai and Yuan, Yongle and Jiang, Meng}, journal={arXiv preprint arXiv:2410.22108}, year={2024} }
搜集汇总
数据集介绍
构建方式
MLLMU-Bench数据集的构建旨在解决多模态大语言模型(MLLMs)中的隐私保护问题。该数据集包含500个虚构人物和153个公众人物的个人资料,每个资料均配备了超过14个定制的问题-答案对。数据集从多模态(图像+文本)和单模态(文本)两个角度进行评估,并分为四个子集以评估遗忘算法在有效性、泛化性和模型实用性方面的表现。通过引入生成模型遗忘算法的基线结果,数据集为多模态遗忘研究提供了新的基准。
使用方法
使用MLLMU-Bench数据集时,用户可以通过Hugging Face平台加载数据集,并根据需要选择不同的子集进行实验。数据集支持多种任务类型,包括分类、生成和掩码任务,用户可以通过这些任务评估模型在多模态和单模态输入下的表现。此外,数据集提供了遗忘和保留子集,用户可以通过这些子集评估遗忘算法的效果。用户还可以使用数据集提供的微调数据训练自己的模型,并通过GitHub仓库获取相关脚本和资源。
背景与挑战
背景概述
MLLMU-Bench数据集由Zheyuan Liu等研究人员于2024年提出,旨在解决多模态大语言模型(MLLMs)中的隐私保护问题。随着生成模型在互联网大规模数据上的训练,模型可能记忆并泄露个人隐私数据,引发法律和伦理争议。尽管已有研究在单模态语言模型(LLMs)中通过机器遗忘技术应对这一问题,但在多模态场景下的探索仍显不足。MLLMU-Bench包含500个虚构人物和153个公众人物的多模态(图像+文本)和单模态(文本)问答对,分为四个子集以评估遗忘算法的有效性、泛化性和模型实用性。该数据集的提出为多模态机器遗忘研究提供了重要的基准工具。
当前挑战
MLLMU-Bench面临的挑战主要集中在两个方面。其一,多模态数据的复杂性使得模型在遗忘特定信息时难以平衡隐私保护与模型性能。例如,如何在删除图像或文本中的敏感信息的同时,保持模型在其他任务上的表现。其二,数据集的构建过程中,如何确保虚构人物和公众人物数据的多样性和代表性,以及如何设计有效的评估指标以全面衡量遗忘算法的效果,均是亟待解决的难题。此外,多模态数据的对齐和一致性也对数据集的构建提出了更高的技术要求。
常用场景
经典使用场景
MLLMU-Bench数据集在评估多模态大语言模型的遗忘算法中具有重要应用。通过提供虚构和真实名人的多模态数据,该数据集能够全面测试模型在图像和文本结合的任务中的表现,特别是在分类、生成和掩码任务中的遗忘效果。
解决学术问题
MLLMU-Bench解决了多模态大语言模型在隐私保护方面的关键问题。通过引入遗忘算法评估框架,该数据集帮助研究者理解如何在保留模型功能的同时,有效删除敏感信息,从而在法律和伦理层面提供保障。
实际应用
在实际应用中,MLLMU-Bench可用于开发更安全的生成模型,特别是在处理包含个人隐私信息的场景中。例如,社交媒体平台可以利用该数据集训练模型,确保在生成内容时不会泄露用户隐私。
数据集最近研究
最新研究方向
在生成式模型领域,尤其是多模态大语言模型(MLLMs)的隐私保护问题日益受到关注。MLLMU-Bench作为首个专注于多模态机器遗忘的基准数据集,为研究者在隐私保护与模型性能之间的权衡提供了重要工具。该数据集通过虚构和真实名人档案的多模态(图像+文本)和单模态(文本)问题对,评估了不同遗忘算法的有效性、泛化能力和模型效用。最新研究表明,单模态遗忘算法在生成和填空任务中表现优异,而多模态遗忘方法则在多模态输入的分类任务中更具优势。这一发现为未来多模态模型的隐私保护研究提供了新的方向,同时也推动了生成式模型在伦理和法律合规性方面的进一步发展。
以上内容由遇见数据集搜集并总结生成


