synthetic-captchas-library
收藏Hugging Face2026-02-01 更新2026-02-02 收录
下载链接:
https://huggingface.co/datasets/remiai3/synthetic-captchas-library
下载链接
链接失效反馈官方服务:
资源简介:
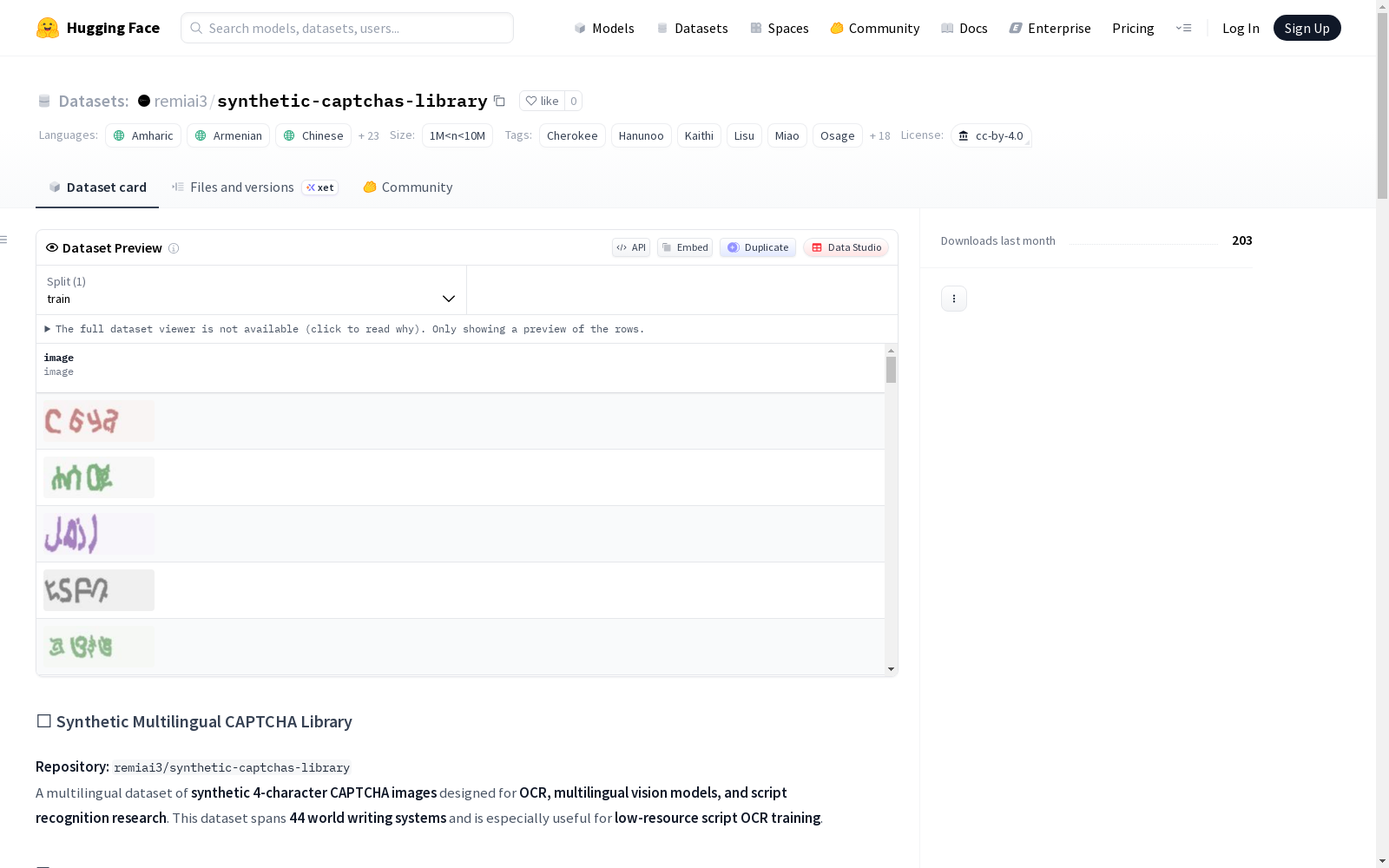
该数据集是一个多语言合成的4字符CAPTCHA图像库,旨在支持OCR、多语言视觉模型和文字识别研究。数据集覆盖了44种世界文字系统,特别适用于低资源语言的OCR训练。每种文字系统包含10万张独特的CAPTCHA图像,总计440万张独特图像(包括重复格式则为880万张)。数据集以两种格式提供:CSV(标准机器学习工作流)和Parquet(大规模管道快速加载)。每个CAPTCHA包含4个字符,图像文件名与正确文本标签相对应。数据集适用于多语言OCR训练、视觉语言模型预训练、文字识别研究以及在扭曲条件下的鲁棒文本识别,但不应用于绕过真实世界的CAPTCHA安全系统。
创建时间:
2026-01-29
搜集汇总
数据集介绍
构建方式
在光学字符识别与多语言视觉模型研究领域,合成数据集的构建对于提升模型在多样文字系统上的泛化能力至关重要。本数据集通过程序化生成方法,为44种世界文字系统各自创建了10万张包含4个字符的验证码图像,总计生成440万张独特样本。这些图像以标准格式存储,并同时提供CSV与Parquet两种标签文件格式,便于适应不同的机器学习工作流程需求。
特点
该数据集最显著的特点在于其广泛的语言覆盖范围,不仅涵盖了拉丁文、中文、阿拉伯文等主流文字,还包含了切罗基文、哈努诺文、索永布文等多种低资源文字系统。每张验证码图像均包含4个字符,并经过视觉变形处理,模拟真实场景中的文本识别挑战。数据集以并行双格式提供,既支持传统的CSV标签读取,也优化了Parquet格式以实现大规模数据管道的高效加载。
使用方法
研究人员可将该数据集应用于多语言光学字符识别模型的训练与评估,尤其适合探索低资源文字系统的识别性能。使用时可从指定语言文件夹中加载images.zip压缩包及对应的标签文件,通过映射关系建立图像与文本的关联。数据集支持直接用于视觉语言模型的预训练,或作为脚本识别研究的基准数据,但需注意其设计初衷仅限于学术研究,不可用于破解实际系统的安全验证。
背景与挑战
背景概述
在光学字符识别与多语言视觉模型研究领域,低资源文字脚本的识别一直存在数据稀缺的瓶颈。由研究机构或团队创建的Synthetic Multilingual CAPTCHA Library数据集,旨在通过合成四字符验证码图像,为涵盖44种世界书写系统的文字识别提供大规模、标准化的训练资源。该数据集的核心研究问题聚焦于提升多语言OCR模型的泛化能力,特别是在非拉丁文字及濒危文字脚本上的识别性能,对推动语言技术公平性与包容性发展具有显著影响力。
当前挑战
该数据集致力于解决多语言光学字符识别领域中的核心挑战,即模型在低资源文字脚本上因训练数据不足而导致的识别准确率低下问题。构建过程中的挑战主要体现在合成数据的真实性与多样性平衡上,需要模拟不同书写系统的字形结构、连字规则及视觉扭曲,同时确保生成图像在风格上贴近真实场景,避免因合成偏差而影响模型在实际应用中的迁移效果。
常用场景
经典使用场景
在光学字符识别与多语言视觉模型研究领域,合成验证码数据集为跨文字系统的文本识别提供了标准化基准。该数据集涵盖44种书写体系,每种包含10万张四字符验证码图像,其经典使用场景在于训练和评估多语言OCR模型,特别是在低资源脚本识别任务中。研究者利用这些合成图像模拟真实场景中的字符扭曲与噪声干扰,从而系统性地提升模型对罕见或复杂文字体系的泛化能力。
实际应用
在实际应用层面,该数据集为多语言文档数字化、历史文献自动转录以及全球化互联网服务的无障碍访问提供了技术支撑。例如,在数字图书馆建设中,基于该数据集训练的模型能够准确识别罕见文字的历史手稿;在跨国企业服务平台中,它助力实现多语言验证码的自动处理与用户身份验证。这些应用显著提升了信息系统的语言覆盖范围与用户体验,促进了文化资源的数字化保存与传播。
衍生相关工作
围绕该数据集衍生的经典工作主要集中在多模态语言模型预训练与低资源脚本识别方法创新上。例如,研究者基于其构建了跨文字系统的对比学习框架,提升了模型对字形相似字符的区分能力;另有工作利用该数据集的合成机制开发了对抗性样本生成技术,用于评估OCR模型的鲁棒性。这些衍生研究不仅推动了多语言视觉表征学习的发展,也为濒危文字的数字复兴提供了方法论基础。
以上内容由遇见数据集搜集并总结生成


