amkyawdev/mm-llm-coder-dataset
收藏Hugging Face2026-05-02 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/amkyawdev/mm-llm-coder-dataset
下载链接
链接失效反馈官方服务:
资源简介:
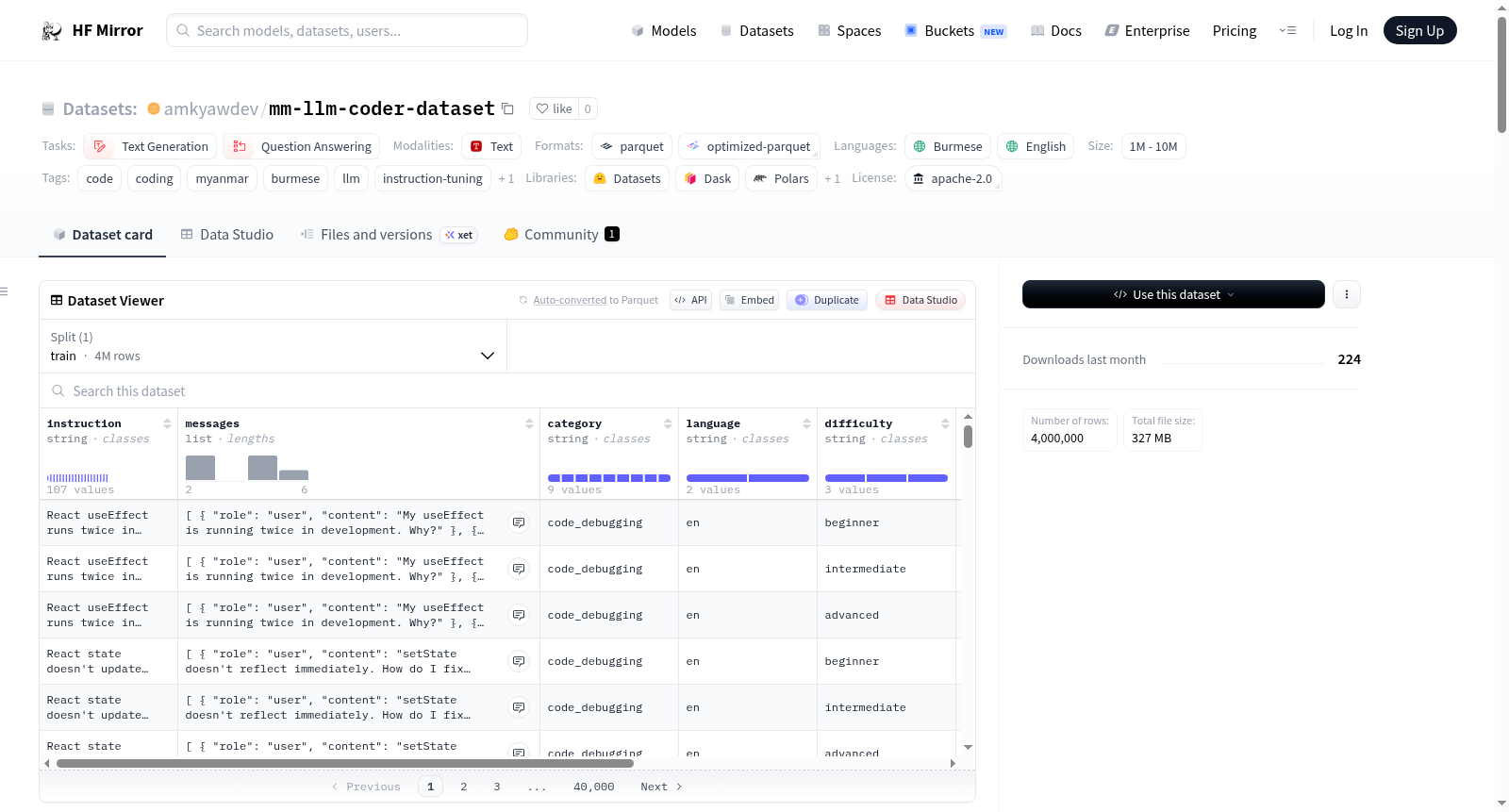
该数据集是一个双语(缅甸语和英语)的编程指令数据集,主要用于训练缅甸语编程语言模型(LLMs)。数据集包含400万条样本,其中缅甸语和英语各占一半。数据格式为Parquet,包含训练集。数据集的结构包括指令、消息(多轮对话)、类别、语言、难度和任务类型等字段。类别分为9种,难度分为初级、中级和高级。数据集的使用场景包括缅甸语编程助手训练、跨语言代码问答、指令调优、代码调试助手和特定主题微调等。
This dataset is a bilingual (Myanmar and English) coding instruction dataset designed primarily for training Myanmar language Coder LLMs. The dataset contains 4 million samples, with 2 million in Myanmar and 2 million in English. The data format is Parquet, including a training set. The dataset structure includes fields such as instruction, messages (multi-turn conversation), category, language, difficulty, and task type. There are 9 categories and 3 difficulty levels (beginner, intermediate, advanced). The dataset is intended for use cases such as Myanmar Coder LLM training, cross-lingual code Q&A, instruction tuning, code debugging assistants, and topic-specific fine-tuning.
提供机构:
amkyawdev
搜集汇总
数据集介绍
构建方式
该数据集是为训练缅甸语编程语言模型而精心打造的双语指令微调资源,涵盖缅甸语与英语两种语言。构建过程基于模板化的策略,通过将精心策划的编程指令与类别、难度及对话轮次等维度进行系统性组合,最终生成规模达四百万条的高质量样本,确保了数据结构的一致性与完整性。
特点
数据集的一大亮点在于其双语并行与多维分类的结构。它均衡包含两百万条缅甸语及两百万条英语样本,横跨代码调试、MongoDB项目、Telegram机器人开发等九个专业类别,并依据难度划分为初阶、中阶与高阶三个层次。每条样本均以多轮对话形式呈现,为训练能够理解并回应缅甸语编程问题的智能助手提供了丰富素材。
使用方法
研究人员可通过HuggingFace的datasets库便捷加载该数据集。支持按语言过滤以进行单语或跨语种微调,也可依据类别与难度筛选用于特定主题的精调。对于大规模训练场景,推荐使用流式加载模式以优化内存。该数据集尤其适用于将Llama、Qwen等基座模型微调为缅甸语编程助手,或构建跨语言代码问答系统。
背景与挑战
背景概述
在大语言模型(LLM)技术日新月异的浪潮中,面向低资源语言的编程辅助工具开发已成为自然语言处理领域的重要前沿。2025年,由研究人员amkyawdev主导构建的缅甸语编程语言模型数据集(mm-llm-coder-dataset)应运而生,该数据集专为训练能够以缅甸语(my)和英语(en)双语提供编程支持的对话式代码助手而设计。其核心研究问题聚焦于如何弥合高资源语言与低资源语言在编程辅助能力上的鸿沟,通过提供400万条涵盖代码调试、API集成、项目部署等九大类别、三种难度等级的多轮问答样本,为缅甸语Coder LLM的指令微调奠定了坚实的语料基础。该数据集的发布,不仅填补了缅甸语在编程领域的稀缺资源空白,也推动了多语言代码智能助手向语言多样性方向的发展,对亚太地区开发者社区的普惠化人工智能应用具有重要示范意义。
当前挑战
该数据集所面临的挑战首先体现在领域问题的复杂性上:尽管缅甸语拥有超过3000万使用者,但受限于网络资源匮乏和编程交流社区不活跃,高质量的缅甸语编程问答数据极度稀缺,使得模型难以从零获取足够的语义与句法知识。此外,数据集构建过程本身亦存在显著困难——当前4M样本均基于模板生成,通过对有限数量的编程指令进行类别、难度与对话轮次的组合排列来扩充规模,这导致语义多样性受限,同一主题下的表达模式固化,容易让模型产生过拟合与模板化回应。另一个挑战在于质量与规模的平衡:模板化生成虽确保了结构一致性,但缺乏真实用户交互中的歧义、省略与错误修正等自然语言特性,且翻译扩充方案可能引入语义失真,亟需后续通过人工审核或更高阶的生成后处理来提升样本的生态真实性与跨语言泛化能力。
常用场景
经典使用场景
在低资源语言代码智能领域,mm-llm-coder-dataset 的核心使命在于赋予预训练语言模型以缅甸语与英语双语的编程理解与生成能力。该数据集包含四百万条精心构造的指令样本,覆盖代码调试、API集成、网站构建等九大类别,并按照初级、中级、高级划分难度层次。其最经典的使用场景是作为缅甸语 Coder LLM 的微调数据源,研究者可基于 Llama、Qwen、Mistral 等基座模型,通过对话式的指令数据引导模型掌握缅甸语编程问题的解答范式,从而突破语言壁垒,构建能够以母语为缅甸开发者提供智能编码辅助的人工智能体。
解决学术问题
该数据集直面自然语言处理领域中低资源语言编程能力缺失的学术挑战。长期以来,缅甸语因其语料稀缺和结构复杂性在代码生成与问答任务中鲜有研究。mm-llm-coder-dataset 通过提供大规模、结构化、双语对齐的编程指令数据,为跨语言代码智能的研究奠定了基准资源。它使得研究人员能够系统性地探索多语言指令微调对模型编码能力的影响,验证模板化数据在特定任务上的有效性边界,并推动学术社区关注缅甸语等低资源语言在软件工程中的语言学与计算语言学问题,具有重要的理论启发性与方法论借鉴意义。
衍生相关工作
作为缅甸语大语言模型生态的重要组成部分,mm-llm-coder-dataset 衍生出一系列相关研究工作。与之配套的还有面向对话技能的 myanmar-llm-data 数据集和面向代理任务编码的 mm-llm-coder-agent-dataset,三者共同构成了分层的技能数据体系。这一系列工作启示了后续研究者构建类似的多技能、多语言数据集框架,并促进了跨语言代码智能评估基准的开发。此外,对该数据集局限性的分析——如模板化导致语义多样性有限——也催生了利用大语言模型自动增强数据质量与多样性等后续方法论探索,体现了其在低资源语言 NLP 研究链中的范式带动作用。
以上内容由遇见数据集搜集并总结生成


