BeIR/quora-generated-queries
收藏Hugging Face2022-10-23 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/BeIR/quora-generated-queries
下载链接
链接失效反馈官方服务:
资源简介:
BEIR Benchmark是一个异构的基准测试,由18个不同的数据集组成,涵盖了9种信息检索任务,包括事实核查、问答、生物医学信息检索等。所有数据集均为英文,并且已经过预处理,可以直接用于实验。数据集的结构包括corpus、queries和qrels文件,分别用于存储文档、查询和相关判断。
BEIR Benchmark is a heterogeneous benchmark consisting of 18 distinct datasets, covering 9 information retrieval tasks including fact checking, question answering, biomedical information retrieval and others. All datasets are in English and have been preprocessed for direct experimental use. The dataset structure includes corpus, queries and qrels files, which are used to store documents, queries and relevance judgments respectively.
提供机构:
BeIR
原始信息汇总
BEIR Benchmark 数据集概述
数据集描述
数据集摘要
BEIR是一个异构基准,由18个不同数据集组成,涵盖9种信息检索任务,包括事实检查、问答、生物医学信息检索等。
支持的任务和排行榜
BEIR支持多种任务,包括文本检索、零样本检索、信息检索等,并提供排行榜以评估模型性能。
语言
所有任务均使用英语。
数据集结构
数据实例
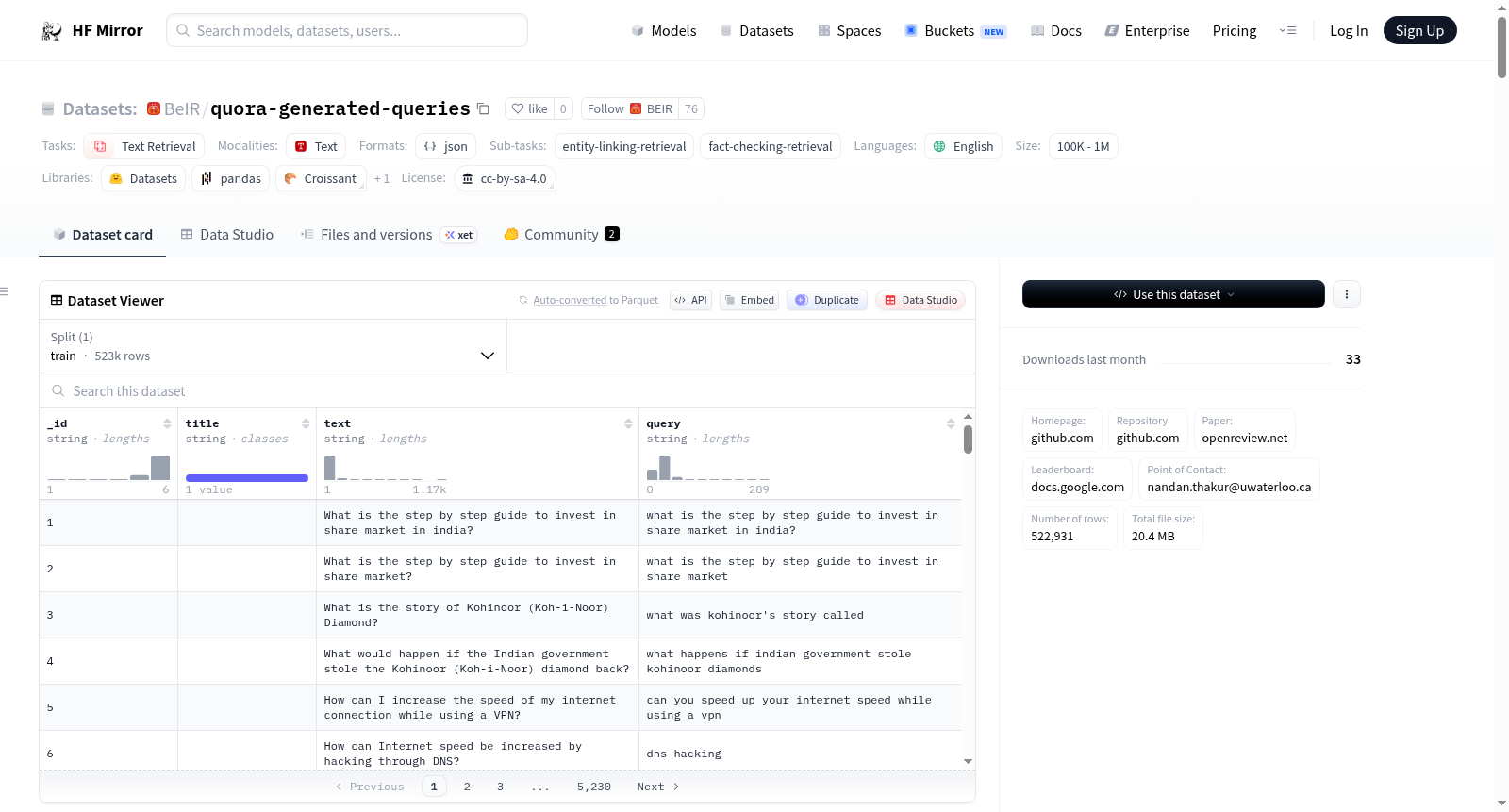
BEIR数据集包含三个主要部分:文档库、查询和相关性判断文件。文档库和查询以.jsonl格式存储,相关性判断以.tsv格式存储。
数据字段
- 文档库:包含文档ID、标题和文本。
- 查询:包含查询ID和查询文本。
- 相关性判断:包含查询ID、文档ID和相关性分数。
数据分割
数据集根据不同任务和数据集进行分割,如MSMARCO、TREC-COVID等,每个数据集的查询数量、文档数量和相关性判断数量各不相同。
数据集创建
数据来源
数据集由多个现有数据集组成,但具体的数据收集和标准化过程未详细说明。
注释信息
数据集的注释过程、注释者和个人敏感信息处理未详细说明。
使用数据集的考虑
社会影响
数据集的社会影响、潜在偏见和其他已知限制未详细说明。
附加信息
数据集管理员
数据集管理员信息未详细说明。
许可信息
数据集使用CC-BY-SA-4.0许可。
引用信息
引用此数据集时,应使用提供的引用格式。
贡献者
感谢@Nthakur20为数据集的贡献。
搜集汇总
数据集介绍
构建方式
在信息检索领域,构建一个全面且多样化的基准数据集对于评估模型性能至关重要。BEIR基准通过整合18个异构数据集,覆盖了事实核查、问答系统、生物医学检索等九大任务类型,其构建过程体现了高度的系统性和严谨性。每个子数据集均经过标准化预处理,统一转化为包含语料库、查询及相关性标注的三元组格式,确保了数据的一致性与可比性。这种集成方法不仅融合了多源数据,还通过严格的格式规范,为后续的零样本检索评估奠定了坚实基础。
特点
BEIR基准的显著特点在于其异构性与任务多样性,它涵盖了从科学文献到社交媒体文本的广泛领域,为信息检索模型提供了跨场景的评估平台。数据集规模跨度极大,语料库数量从数千到数百万不等,查询与相关文档的比例也呈现差异化分布,这模拟了真实世界检索任务的复杂性。所有数据均以英文呈现,并采用统一的JSON Lines和TSV格式存储,便于研究者直接加载与使用,其结构化的设计支持高效的批量处理与模型训练。
使用方法
使用BEIR基准时,研究者可通过其GitHub仓库提供的工具链轻松加载任一子数据集,每个数据集均包含语料库、查询及相关性标注文件。典型流程包括:首先加载语料库文档与查询文本,随后基于相关性标注进行模型训练或评估,支持零样本检索设置。该基准已集成标准评估指标,用户可参照官方示例代码快速实现检索模型的性能测试,并参与公开排行榜的比较,从而推动信息检索技术的迭代与优化。
背景与挑战
背景概述
BEIR基准数据集由德国达姆施塔特工业大学UKP实验室的研究团队于2021年构建,旨在解决信息检索领域零样本评估的标准化难题。该数据集整合了来自18个异构数据源的多样化任务,涵盖事实核查、问答系统、生物医学检索等九大领域,其核心研究目标是为检索模型提供跨任务的统一评估框架。通过系统化地预处理和格式化多源数据,BEIR显著推动了检索模型泛化能力的研究,成为衡量模型在未见领域表现的重要基准。
当前挑战
BEIR数据集面临的挑战主要体现在两个方面:在领域问题层面,其需应对异构任务带来的评估复杂性,例如如何在事实核查、生物医学检索等差异显著的场景中建立统一的性能度量标准,这对模型的领域适应性与鲁棒性提出了极高要求。在构建过程中,挑战源于多源数据的整合与标准化,包括不同数据集的格式差异、标注质量不一以及规模悬殊等问题,需通过精细的预处理流程确保数据的一致性与可比性。
常用场景
经典使用场景
在信息检索领域,BEIR/quora-generated-queries数据集作为BEIR基准的组成部分,其经典使用场景聚焦于重复问题检索任务。该数据集通过Quora平台收集的问答对,构建了丰富的查询-文档相关性标注,为评估检索模型在零样本或少量样本下的泛化能力提供了标准化测试环境。研究者常利用该数据集训练和验证密集检索模型,如双编码器架构,以探索模型在跨领域检索任务中的表现,从而推动检索技术向更高效、更精准的方向演进。
解决学术问题
该数据集有效解决了信息检索研究中模型泛化能力评估的难题。传统检索模型往往在特定数据集上表现优异,但迁移到新领域时性能显著下降。BEIR基准通过整合包括Quora在内的多领域数据集,为学术界提供了统一的评估框架,使得研究者能够系统性地分析模型在事实核查、问答、生物医学检索等九类任务上的零样本性能。这一举措促进了检索模型从过度拟合向通用性发展的转变,对推动跨领域检索理论的发展具有深远意义。
衍生相关工作
围绕该数据集衍生的经典工作包括密集检索模型的创新与基准评估工具的完善。例如,DPR、ANCE等模型利用BEIR基准进行了广泛测试,推动了双编码器技术在检索任务中的应用。同时,像Sentence-Transformers库和RAG框架等工具也集成BEIR以优化检索性能。这些工作不仅拓展了数据集的使用边界,还为后续研究如多语言检索、跨模态检索提供了理论基础和实践参考,形成了持续迭代的学术生态。
以上内容由遇见数据集搜集并总结生成


