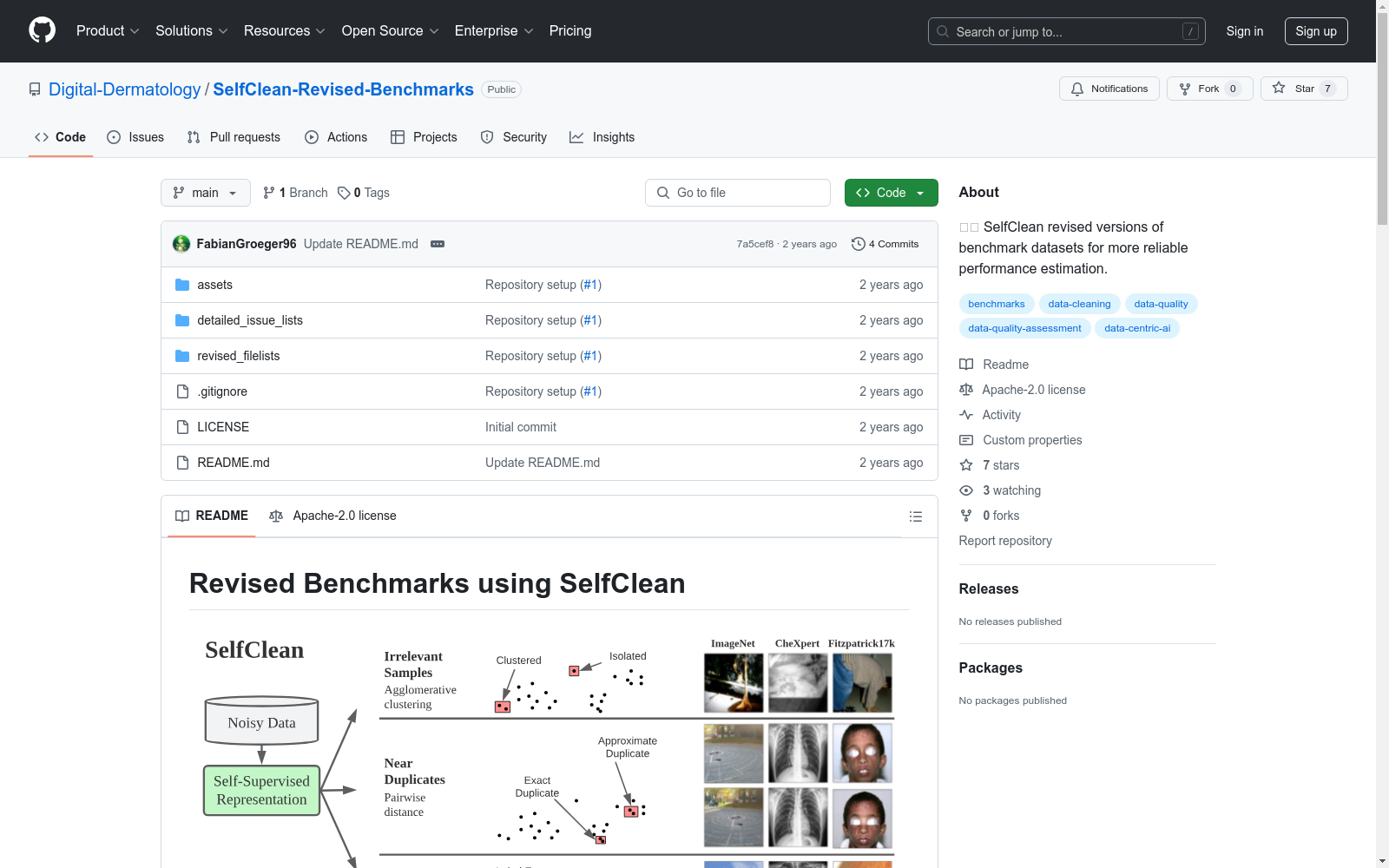
Revised Benchmarks
收藏数据集概述
数据集名称
Revised Benchmarks using SelfClean
数据集内容
本数据集包含使用SelfClean数据清洗协议和专家注释者创建的基准数据集的修订版本。修订文件列表应被用于模型评估,为跨领域更可信的性能评估铺平道路。
修订的基准
修订的文件列表包括原始数据集中有效图像的文件名,排除了无关和近重复样本。标签错误未被纠正,以公平对待类似SelfClean编码器的模型,但其普遍性被报告,可用于推断由于标签质量导致的性能饱和水平。
数据集详情
| 数据集 | 大小 | 无关样本 | 近重复 | 标签错误 |
|---|---|---|---|---|
| MED-NODE | 170 | 3 (1.8%) | 1 (0.6%) | 2 (1.2%) |
| PH2 | 200 | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) |
| DDI | 656 | 3 (0.5%) | 6 (0.9%) | 8 (1.2%) |
| Derm7pt | 2,022 | 1 (0.1%) | 9 (0.5%) | 2 (0.1%) |
| PAD-UFES-20 | 2,298 | 2 (0.1%) | 56 (2.4%) | 3 (0.1%) |
| SD-128 | 5,619 | 3 (0.1%) | 156 (2.8%) | 4 (0.1%) |
数据集使用说明
数据集包含修订的文件列表(revised_filelists/)和详细的问题列表(detailed_issue_lists)。修订的文件列表由排除数据质量问题的有效图像的文件名组成。
数据清洗协议
数据清洗协议结合了现有的算法清洗策略来发现候选问题,并使用可解释的停止准则进行有效注释。具体步骤包括:
- 使用SelfClean找出基准数据集中的潜在数据质量问题。
- 将SelfClean获得的排名呈现给人类注释者进行确认,依赖实践专家进行确认。
- 在确认过程后,保守地要求所有专家一致同意来识别问题,然后通过丢弃确认的无关样本和随机移除每个确认的近重复样本对来生成清洗后的基准数据集。
引用信息
如发现此存储库对您的研究有用或使用其中一个修订文件列表,请引用以下工作: bib @misc{groger_selfclean_2023, title = {{SelfClean}: {A} {Self}-{Supervised} {Data} {Cleaning} {Strategy}}, shorttitle = {{SelfClean}}, author = {Gröger, Fabian and Lionetti, Simone and Gottfrois, Philippe and Gonzalez-Jimenez, Alvaro and Amruthalingam, Ludovic and Consortium, Labelling and Groh, Matthew and Navarini, Alexander A. and Pouly, Marc}, year = 2023, } @InProceedings{pmlr-v225-groger23a, title = {Towards Reliable Dermatology Evaluation Benchmarks}, author = {Gr"oger, Fabian and Lionetti, Simone and Gottfrois, Philippe and Gonzalez-Jimenez, Alvaro and Groh, Matthew and Daneshjou, Roxana and Consortium, Labelling and Navarini, Alexander A. and Pouly, Marc}, booktitle = {Proceedings of the 3rd Machine Learning for Health Symposium}, pages = {101--128}, year = {2023}, volume = {225}, series = {Proceedings of Machine Learning Research}, month = {10 Dec}, publisher = {PMLR}, }