110-PT-BN-KP
收藏github2019-11-29 更新2024-05-31 收录
下载链接:
https://github.com/vitordouzi/AKE_Datasets
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含新闻故事的监督式主题关键词提取,使用了众包、轻量级过滤和共指规范化方法。
This dataset encompasses supervised topic keyword extraction from news stories, employing methods such as crowdsourcing, lightweight filtering, and coreference normalization.
创建时间:
2018-09-18
原始信息汇总
数据集概述
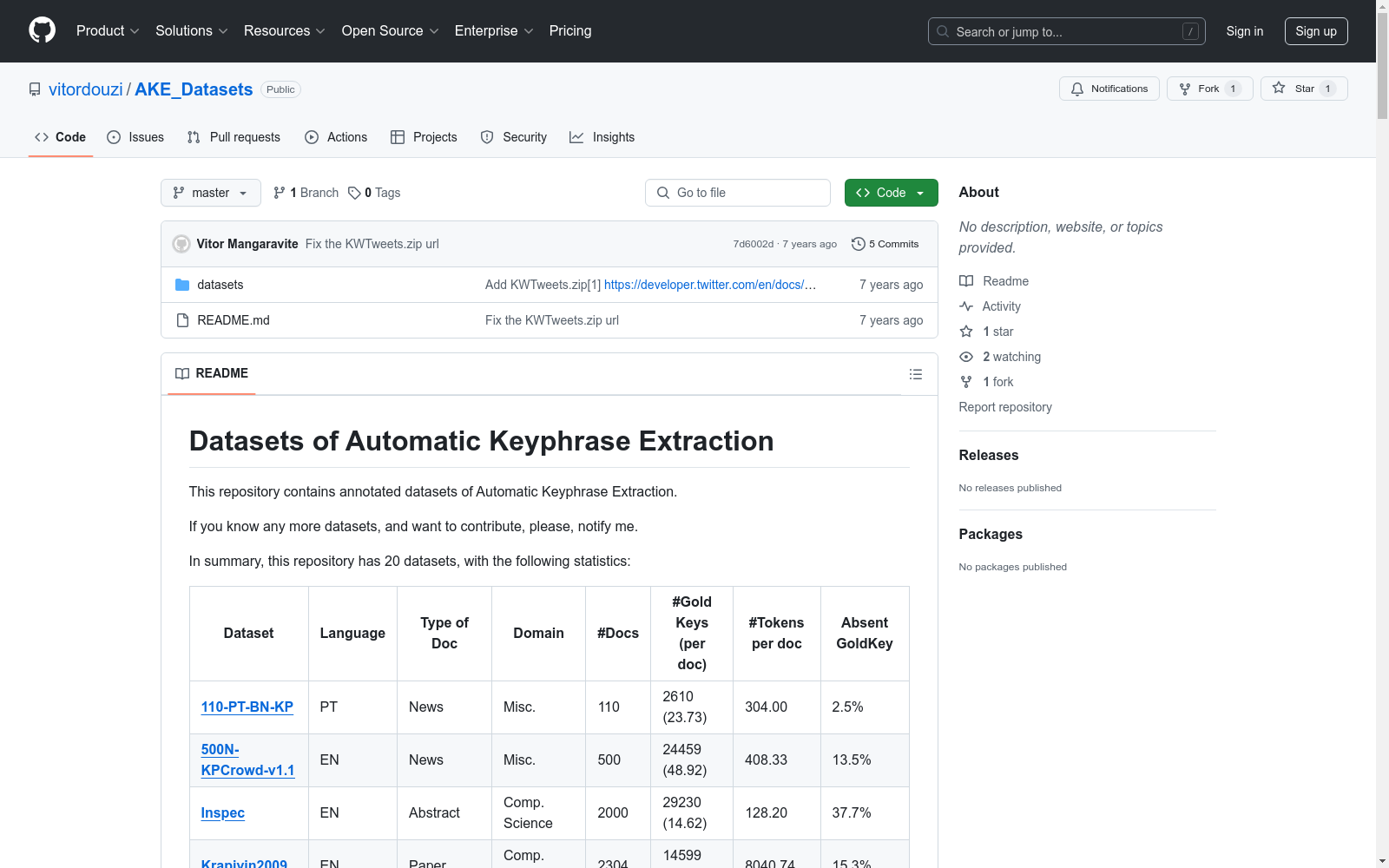
本数据集集合包含20个不同来源和领域的自动关键词提取标注数据集,涵盖多种语言和文档类型。以下是各数据集的详细信息:
| 数据集名称 | 语言 | 文档类型 | 领域 | 文档数量 | 黄金关键词数量(每文档) | 每文档平均词数 | 缺失黄金关键词比例 |
|---|---|---|---|---|---|---|---|
| 110-PT-BN-KP | PT | 新闻 | 杂项 | 110 | 2610 (23.73) | 304.00 | 2.5% |
| 500N-KPCrowd-v1.1 | EN | 新闻 | 杂项 | 500 | 24459 (48.92) | 408.33 | 13.5% |
| Inspec | EN | 摘要 | 计算机科学 | 2000 | 29230 (14.62) | 128.20 | 37.7% |
| Krapivin2009 | EN | 论文 | 计算机科学 | 2304 | 14599 (6.34) | 8040.74 | 15.3% |
| KWTweet | EN | 推文 | 杂项 | 7736 | 31759 (4.12) | 19.79 | 7.87% |
| Nguyen2007 | EN | 论文 | 计算机科学 | 209 | 2369 (11.33) | 5201.09 | 17.8% |
| PubMed | EN | 论文 | 计算机科学 | 500 | 7620 (15.24) | 3992.78 | 60.2% |
| Schutz2008 | EN | 论文 | 计算机科学 | 1231 | 55013 (44.69) | 3901.31 | 13.6% |
| SemEval2010 | EN | 论文 | 计算机科学 | 243 | 4002 (16.47) | 8332.34 | 11.3% |
| SemEval2017 | EN | 段落 | 杂项 | 493 | 8969 (18.19) | 178.22 | 0.0% |
| WikiNews | FR | 新闻 | 杂项 | 100 | 1177 (11.77) | 293.52 | 5.0% |
| cacic | ES | 论文 | 计算机科学 | 888 | 4282 (4.82) | 3985.84 | 2.2% |
| citeulike180 | EN | 论文 | 杂项 | 183 | 3370 (18.42) | 4796.08 | 32.2% |
| fao30 | EN | 论文 | 农业 | 30 | 997 (33.23) | 4777.70 | 41.7% |
| fao780 | EN | 论文 | 农业 | 779 | 6990 (8.97) | 4971.79 | 36.1% |
| kdd | EN | 论文 | 计算机科学 | 755 | 3831 (5.07) | 75.97 | 53.2% |
| pak2018 | PL | 摘要 | 杂项 | 50 | 232 (4.64) | 97.36 | 64.7% |
| theses100 | EN | 硕士/博士论文 | 杂项 | 100 | 767 (7.67) | 4728.86 | 47.6% |
| wicc | ES | 论文 | 计算机科学 | 1640 | 7498 (4.57) | 1955.56 | 2.7% |
| wiki20 | EN | 研究报告 | 计算机科学 | 20 | 730 (36.50) | 6177.65 | 51.8% |
| www | EN | 论文 | 计算机科学 | 1330 | 7711 (5.80) | 84.08 | 55.0% |
每个数据集的具体描述、引用信息和下载链接请参考原始README文件中的详细说明。
搜集汇总
数据集介绍
构建方式
110-PT-BN-KP数据集的构建是通过转录8个欧洲葡萄牙ALERT BN数据库中的电视广播新闻节目文本,并对转录文本进行人工检查以修正分段错误,进而创建黄金关键词。这些关键词是由一位标注者从文档内容中提取,以总结文档的主要内容。
特点
该数据集的特点在于,它包含110篇葡萄牙语新闻文档,覆盖了政治、体育、金融等多个领域。文档经过人工审查确保质量,且每个文档都附带有一组由标注者提取的黄金关键词,这些关键词能够准确概括文档内容。
使用方法
使用该数据集时,研究者可以依据提供的黄金关键词进行关键短语提取算法的训练和评估。数据集以.zip格式提供,研究者需要解压后获取文档和对应的黄金关键词,以便进行进一步的数据处理和分析。
背景与挑战
背景概述
110-PT-BN-KP数据集,创建于葡萄牙语新闻领域,旨在为自动关键短语提取研究提供基准。该数据集由ALERT BN数据库中的8个电视新闻节目转录文本构成,共计110篇文档,内容涵盖政治、体育、财经等多个领域。数据集的构建过程中,转录文本经过人工审核以修正切分错误,并进一步由标注员提取能够概括文档内容的关键短语。此数据集的研究背景与欧洲葡萄牙语新闻的自动处理紧密相关,对于推动该领域的研究具有重要意义。
当前挑战
在构建110-PT-BN-KP数据集的过程中,研究人员面临了诸多挑战。首先,电视新闻文本的口语化和非正式性使得关键短语的提取面临较大困难。其次,由于涉及多领域的新闻内容,领域知识的缺乏可能导致关键短语提取的准确性和全面性受限。此外,标注过程中的一致性保证也是一大挑战,确保不同标注员之间对于关键短语的认定保持一致,对于数据集的质量至关重要。
常用场景
经典使用场景
110-PT-BN-KP数据集是一份专注于电视新闻故事的自动关键短语提取的标注数据集。其经典的使用场景在于,研究者可以利用该数据集对自动关键短语提取算法进行训练和评估,以提高算法对新闻文本中关键信息的提取能力。
实际应用
在实际应用中,110-PT-BN-KP数据集可用于新闻聚合平台的自动标签生成、搜索引擎的关键词优化以及智能问答系统中的信息抽取等场景。
衍生相关工作
基于110-PT-BN-KP数据集,研究者们已经衍生出了一系列相关工作,如新闻文本的语义分析、情感分析以及跨语言关键短语提取等领域的探索。
以上内容由遇见数据集搜集并总结生成


