claimify-dataset
收藏数据集概述
基本信息
- 许可证: CDLA Permissive 2.0
- 语言: 英语 (en)
- 任务类别: 文本分类 (text-classification)
数据集内容
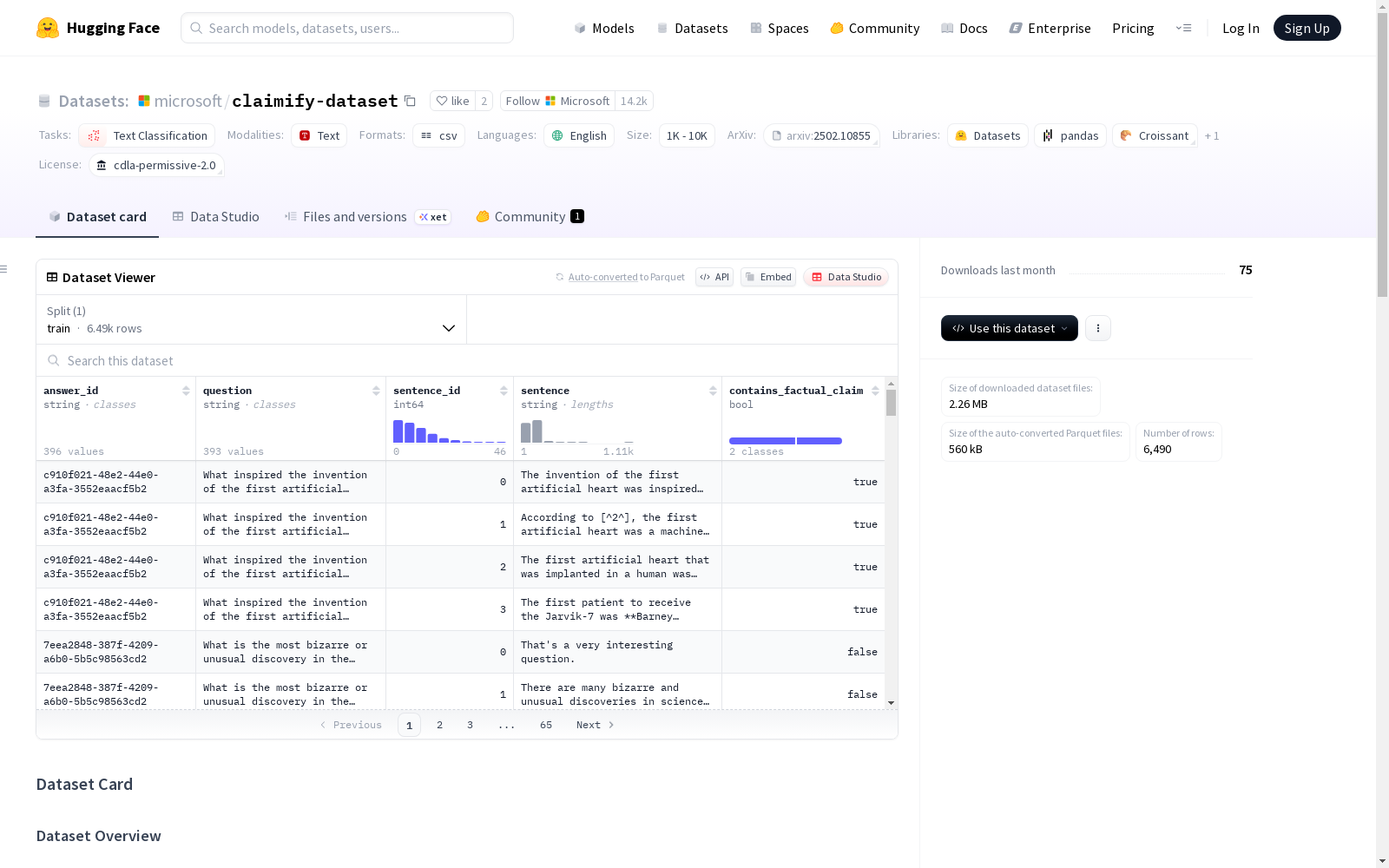
- 数据量: 6,490 条句子
- 标注类型: 二元标签 (是否包含可验证的事实性声明)
- 数据来源: 来自 BingCheck 数据集 的 396 个答案
- 标注比例: 59% 的句子被标注为包含可验证的事实性声明
数据结构
- 列名及类型:
answer_id(string): BingCheck 答案的唯一 IDquestion(string): 原始 BingCheck 问题sentence_id(int): 答案中句子的索引sentence(string): 句子文本contains_factual_claim(bool): 如果句子包含可验证的事实性声明则为 True,否则为 False
示例数据
json { "answer_id": "c910f021-48e2-44e0-a3fa-3552eaacf5b2", "question": "What inspired the invention of the first artificial heart?", "sentence_id": 3, "sentence": "The first patient to receive the Jarvik-7 was Barney Clark, a dentist from Seattle, who survived for 112 days after the implantation[^2^].", "contains_factual_claim": True }
数据集创建
- 句子分割: 首先按换行符分割,然后使用 NLTK 的句子分词器
- 标注过程: 由微软研究院的三名员工执行,遵循论文附录 C 中的详细程序和指南
相关资源
- 论文: Towards Effective Extraction and Evaluation of Factual Claims
- 视频: 视频介绍
- 博客: Claimify: Extracting High-Quality Claims from Language Model Outputs
引用
bibtex @inproceedings{metropolitansky-larson-2025-towards, title = "Towards Effective Extraction and Evaluation of Factual Claims", author = "Metropolitansky, Dasha and Larson, Jonathan", editor = "Che, Wanxiang and Nabende, Joyce and Shutova, Ekaterina and Pilehvar, Mohammad Taher", booktitle = "Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)", month = jul, year = "2025", address = "Vienna, Austria", publisher = "Association for Computational Linguistics", url = "https://aclanthology.org/2025.acl-long.348/", doi = "10.18653/v1/2025.acl-long.348", pages = "6996--7045", ISBN = "979-8-89176-251-0", }
伦理声明
- 所有数据标注均在研究参与者知情同意的情况下进行
- 不包含任何个人身份信息