m-a-p/COIG-Kun
收藏Hugging Face2024-04-08 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/m-a-p/COIG-Kun
下载链接
链接失效反馈官方服务:
资源简介:
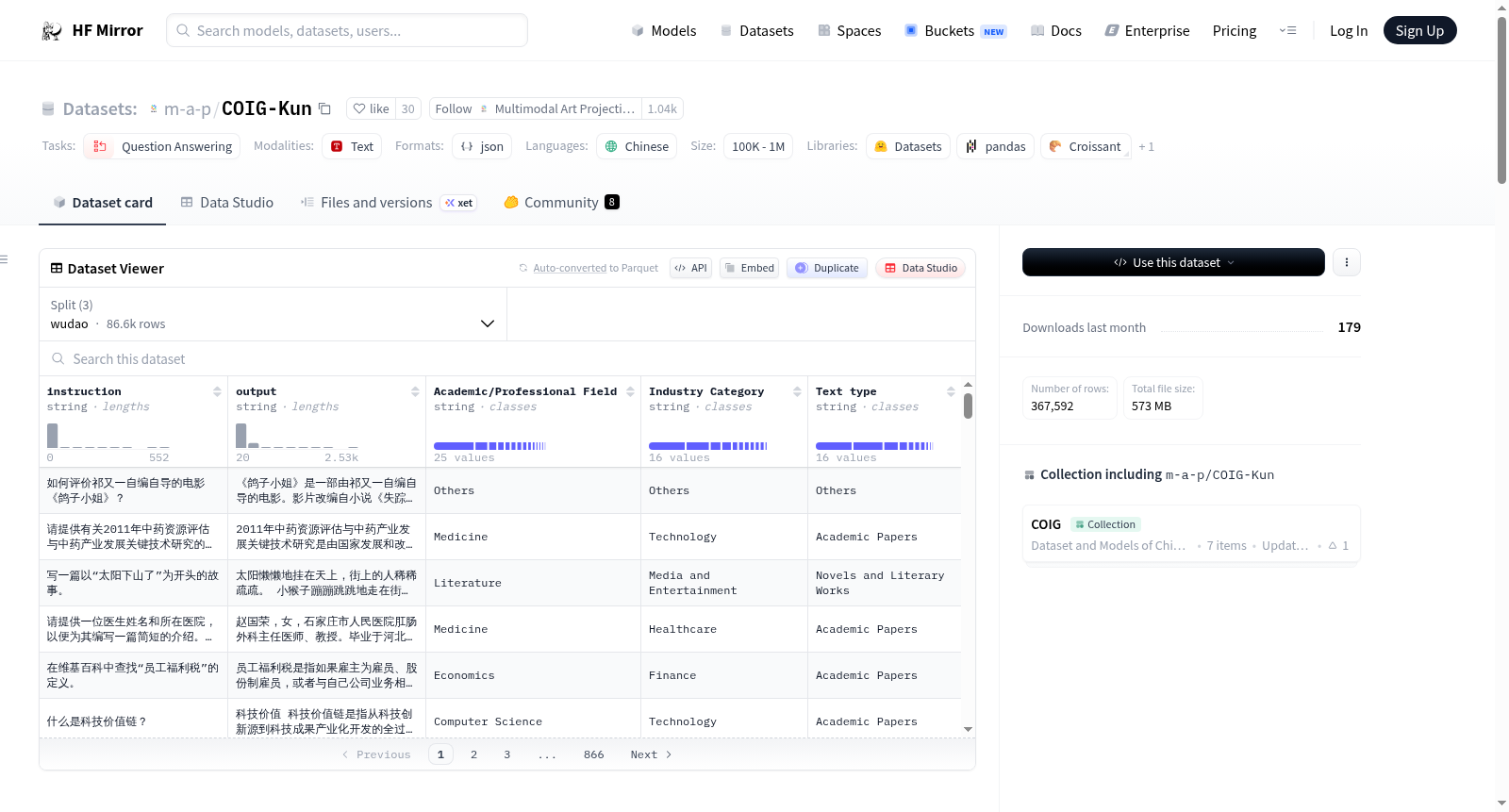
COIG-Kun数据集是用于训练语言模型的指令数据集,主要包含中文指令。数据集由三个子集组成:wudao、wanjuan和skypile,分别包含139,852、328,294和71,560个数据实例。每个数据实例以JSON格式存储,包含`instruction`和`output`两个字段。该数据集旨在提供高质量的指令数据,以增强语言模型的训练效果,特别是在指令理解和响应生成方面。
The COIG-Kun dataset is an instructional dataset for training language models, primarily containing Chinese instructions. The dataset is divided into three subsets: wudao, wanjuan, and skypile, with each data instance stored in JSON format, including `instruction` and `output` fields. The design of this dataset aims to provide high-quality training data to enhance the quality and applicability of language models. The creation of the dataset follows Metas Self-Alignment with Instruction Backtranslation method, with optimizations made to improve data processing efficiency.
提供机构:
m-a-p
原始信息汇总
数据集概述
数据集描述
语言
- 该数据集主要包含中文指令。
数据结构
- 数据实例: 每个数据实例以JSON格式存储,包含两个字段:
instruction和output。- 示例:
{"instruction": "如何评价祁又一自编自导的电影《鸽子小姐》?", "output": "《鸽子小姐》是一部由祁又一自编自导的电影。..."}
- 示例:
- 数据分割: 数据集包含三个子集:
wudao.jsonl: 139,852 实例wanjuan.jsonl: 328,294 实例skypile.jsonl: 71,560 实例
数据特点
- 该数据集旨在提供高质量的指令数据,用于语言模型训练,专注于提高数据的质量和适用性。
使用方法
使用数据
- 该数据集可用于训练和微调语言模型,特别是专注于指令理解和响应生成。
- 用户应参考项目文档,了解在训练过程中使用数据集的详细说明。
引用
如果您在研究中使用此数据集,请按以下方式引用:
bibtex @misc{COIG-Kun, title={Kun: Answer Polishment Saves Your Time for Using Intruction Backtranslation on Self-Alignment}, author={Tianyu, Zheng* and Shuyue, Guo* and Xingwei, Qu and Xinrun, Du and Wenhu, Chen and Jie, Fu and Wenhao, Huang and Ge, Zhang}, year={2023}, publisher={GitHub}, journal={GitHub repository}, howpublished={https://github.com/Zheng0428/COIG-Kun} }
搜集汇总
数据集介绍
背景与挑战
背景概述
COIG-Kun是一个高质量的中文指令数据集,专为语言模型训练设计,包含约36.7万条结构化数据,采用自对齐和指令回译技术优化数据质量。
以上内容由遇见数据集搜集并总结生成


