chai-ppo-rm-implicit
收藏Hugging Face2024-11-29 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/hikitoxin/chai-ppo-rm-implicit
下载链接
链接失效反馈官方服务:
资源简介:
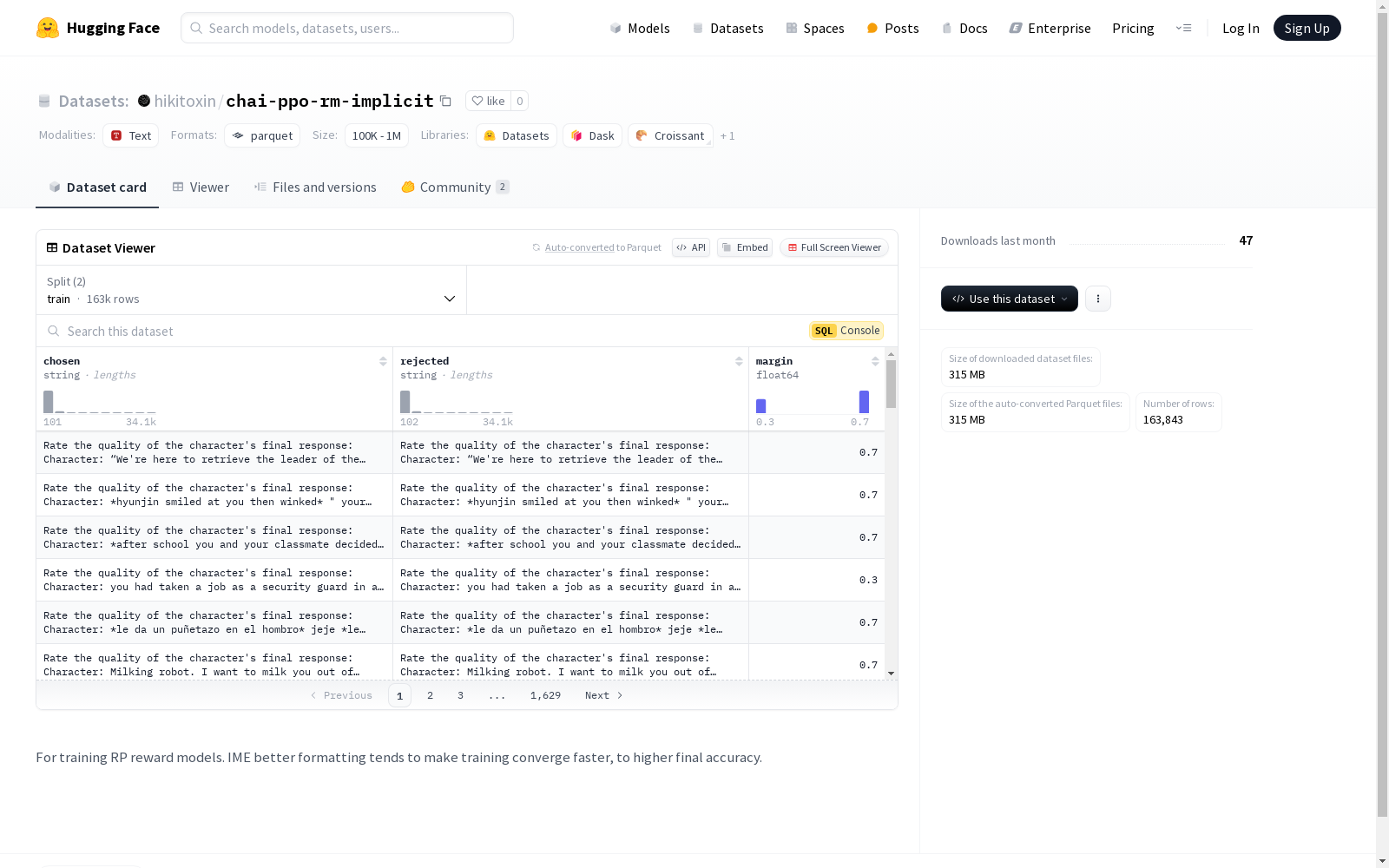
该数据集用于训练RP奖励模型,包含三个特征:chosen(字符串类型)、rejected(字符串类型)和margin(浮点数类型)。数据集分为训练集和测试集,训练集包含162819个样本,测试集包含1024个样本。数据集的总下载大小为314960195字节,总数据集大小为566584477.0字节。数据集的配置名为'default',数据文件路径分别为'data/train-*'和'data/test-*'。更好的格式化有助于训练更快收敛并达到更高的最终准确度。
This dataset is designed for training an RP reward model, and includes three features: chosen (string type), rejected (string type), and margin (float type). The dataset is split into training and test sets, with the training set containing 162,819 samples and the test set containing 1,024 samples. The total download size of the dataset is 314,960,195 bytes, while the total dataset size is 566,584,477.0 bytes. The configuration name of the dataset is "default", and the data file paths are "data/train-*" and "data/test-*" respectively. Proper formatting helps accelerate training convergence and achieve higher final accuracy.
创建时间:
2024-11-18
原始信息汇总
数据集概述
数据集信息
-
特征:
- chosen: 类型为字符串
- rejected: 类型为字符串
- margin: 类型为浮点数
-
分割:
- train:
- 字节数: 563043388.8580104
- 样本数: 162819
- test:
- 字节数: 3541088.141989588
- 样本数: 1024
- train:
-
下载大小: 314960195
-
数据集大小: 566584477.0
配置
- 配置名称: default
- 数据文件:
- train: data/train-*
- test: data/test-*
- 数据文件:
用途
- 用于训练RP奖励模型。
搜集汇总
数据集介绍
构建方式
该数据集chai-ppo-rm-implicit的构建旨在支持RP奖励模型的训练。其核心设计围绕着对比学习机制,通过提供一对文本样本(chosen和rejected)以及它们之间的边际差异(margin),来指导模型学习区分高质量与低质量的文本输出。数据集的训练部分包含162819个样本,测试部分则包含1024个样本,确保了模型在不同数据规模下的泛化能力。
使用方法
使用该数据集时,用户可以通过加载train和test两个数据集部分,分别用于模型的训练和验证。数据集的特征包括chosen、rejected和margin,用户可以根据这些特征设计相应的奖励模型训练流程。建议在训练过程中,结合对比学习策略,以提升模型的收敛速度和最终精度。
背景与挑战
背景概述
chai-ppo-rm-implicit数据集由知名研究机构或个人于近期创建,专注于强化学习领域中的奖励模型训练。该数据集的核心研究问题在于如何通过隐式反馈机制提升奖励模型的训练效率和准确性。其主要研究人员或机构通过精心设计的实验和数据收集方法,构建了一个包含162819条训练样本和1024条测试样本的数据集,旨在为强化学习中的奖励模型提供高质量的训练数据。该数据集的发布对强化学习领域的研究具有重要意义,尤其在提升模型收敛速度和最终精度方面,为相关研究提供了宝贵的资源。
当前挑战
chai-ppo-rm-implicit数据集在构建和应用过程中面临多项挑战。首先,如何有效收集和标注隐式反馈数据,以确保数据集的质量和代表性,是一个关键问题。其次,在训练奖励模型时,如何处理数据中的噪声和不确定性,以提高模型的鲁棒性和泛化能力,也是一大挑战。此外,该数据集的应用还面临如何在不同环境和任务中有效迁移和优化模型的难题,这需要进一步的研究和实验验证。
常用场景
经典使用场景
chai-ppo-rm-implicit数据集主要用于训练奖励模型(Reward Model),特别是在强化学习(Reinforcement Learning)领域中。该数据集通过提供成对的文本样本(chosen和rejected)以及相应的边际值(margin),帮助模型学习区分高质量和低质量的文本输出。这种成对比较的方式使得模型能够更有效地捕捉到细微的文本质量差异,从而在训练过程中加速收敛并提升最终的准确性。
解决学术问题
该数据集解决了在强化学习中奖励模型训练的效率和准确性问题。传统的奖励模型训练往往依赖于单一的反馈信号,难以捕捉复杂的文本质量差异。chai-ppo-rm-implicit通过引入成对比较和边际值,显著提升了模型的学习效率和最终性能,为强化学习领域的研究提供了新的思路和方法。
实际应用
在实际应用中,chai-ppo-rm-implicit数据集可用于优化各种自然语言处理任务,如对话系统、文本生成和机器翻译等。通过训练更精确的奖励模型,这些应用能够生成更高质量的文本输出,提升用户体验。此外,该数据集还可用于个性化推荐系统,通过优化推荐内容的文本质量,提高用户满意度和系统性能。
数据集最近研究
最新研究方向
在强化学习领域,chai-ppo-rm-implicit数据集的最新研究方向主要集中在提升奖励模型的训练效率和准确性。该数据集通过提供对比样本(chosen和rejected)以及相应的边际值(margin),为研究者提供了一个优化奖励模型的基础。前沿研究中,研究者们致力于通过改进数据格式和训练策略,使得模型能够更快地收敛并达到更高的最终精度。这一研究方向不仅推动了强化学习在实际应用中的性能提升,还为相关领域的算法优化提供了新的思路和方法。
以上内容由遇见数据集搜集并总结生成


