fancyzhx/dbpedia_14
收藏Hugging Face2024-01-22 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/fancyzhx/dbpedia_14
下载链接
链接失效反馈官方服务:
资源简介:
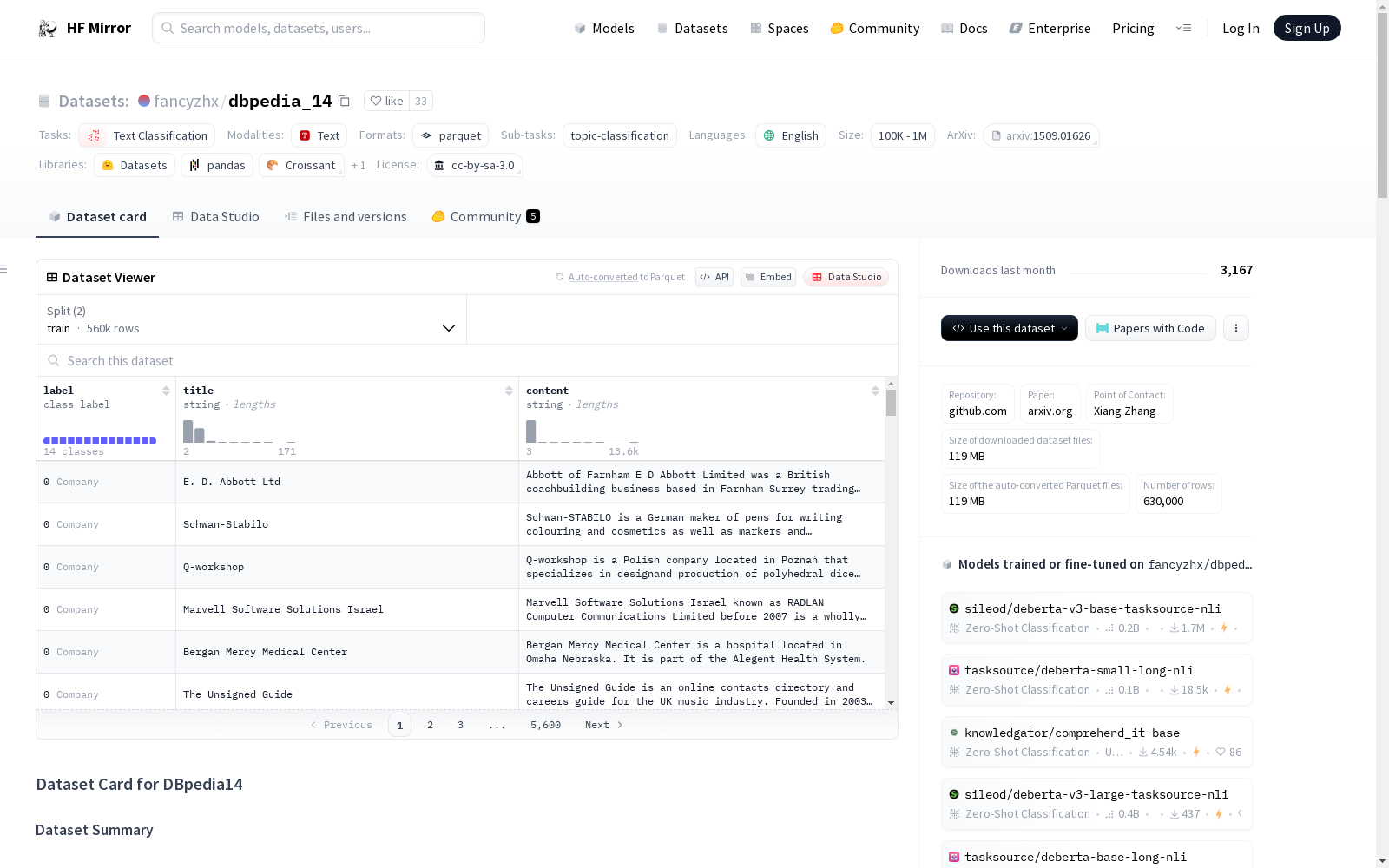
DBpedia14数据集是一个用于文本分类的数据集,主要包含从DBpedia 2014中选取的14个非重叠类别的数据。数据集分为训练集和测试集,分别包含560,000和70,000个样本。每个数据点包含标题、内容和对应的标签。数据集主要用于文本分类任务,特别是主题分类。数据集的创建者Xiang Zhang,并且数据集在NIPS 2015的一篇论文中被用作文本分类的基准。
The DBpedia14 dataset is a text classification dataset that primarily contains data from 14 non-overlapping categories selected from DBpedia 2014. It is divided into training and test sets, with 560,000 and 70,000 samples respectively. Each data point includes a title, content, and its corresponding label. This dataset is mainly utilized for text classification tasks, particularly topic classification. It was created by Xiang Zhang and was adopted as a benchmark for text classification in a paper presented at NIPS 2015.
提供机构:
fancyzhx
原始信息汇总
数据集概述
数据集名称
- 名称: DBpedia14
- 别名: DBpedia
数据集属性
- 语言: 英语 (主要)
- 许可证: Creative Commons Attribution-ShareAlike 3.0 (cc-by-sa-3.0)
- 多语言性: 单语
- 大小: 100,000 < n < 1,000,000
- 来源: 原始数据
- 任务类型: 文本分类
- 任务ID: 主题分类
数据集结构
- 特征:
- label: 类别标签,包括14种不同的类别,如公司、教育机构等。
- title: 文档标题,字符串类型。
- content: 文档内容,字符串类型。
- 数据分割:
- 训练集: 560,000样本,178,428,970字节。
- 测试集: 70,000样本,22,310,285字节。
数据集创建
- 创建者: Xiang Zhang (xiang.zhang@nyu.edu)
- 创建理由: 用于文本分类的基准数据集,特别是在论文 "Character-level Convolutional Networks for Text Classification" 中使用。
- 源数据: 来自DBpedia (https://wiki.dbpedia.org/develop/datasets)
使用注意事项
- 许可证: 使用需遵守Creative Commons Attribution-ShareAlike 3.0和GNU Free Documentation License。
- 引用信息: 引用时需使用提供的引用格式。
搜集汇总
数据集介绍
构建方式
DBpedia14数据集是由Xiang Zhang构建的,该数据集从DBpedia 2014中选取了14个不重叠的类别。每个类别下随机选择了40,000个训练样本和5,000个测试样本,总计训练集规模为560,000个样本,测试集规模为70,000个样本。数据集包含标题、内容以及对应的标签,均采用字符串形式表示,其中标签对应于14个可能的主题类别。
特点
DBpedia14数据集的特点在于其专注于文本分类任务,提供的是单语种英文数据,尽管DBpedia本身是一个多语言的知识库。数据集采用Creative Commons Attribution-ShareAlike License和GNU Free Documentation License双许可,保证了数据的开放性和可用性。每个数据点由标题、内容和标签组成,为文本分类研究提供了丰富的样本资源。
使用方法
使用DBpedia14数据集时,用户可以从提供的训练集和测试集中进行数据加载和模型训练。数据集的结构允许用户轻松地将其用于文本分类任务,如根据文档的标题和内容预测正确的主题类别。用户应当遵循数据集的许可协议,并在使用数据集时正确引用相关文献。
背景与挑战
背景概述
DBpedia14数据集,源自于DBpedia知识库,由纽约大学的研究人员Xiang Zhang于2014年构建,旨在为文本分类任务提供基准。该数据集选取了DBpedia中的14个非重叠类别,每个类别分别随机抽取了40000个训练样本和5000个测试样本,总计包含560000个训练样本和70000个测试样本。数据集的核心研究问题是通过文档的标题和内容,预测其正确的主题类别。DBpedia14对相关领域的影响力体现在,它被广泛用作评估文本分类模型的性能,尤其是在字符级卷积网络在文本分类中的应用研究方面。
当前挑战
在数据集构建过程中,面临的挑战包括如何从DBpedia知识库中有效地抽取和分类数据,以及如何处理数据中的多语言现象。此外,数据集使用中存在的挑战包括如何处理潜在的偏见和敏感性信息,确保数据的使用不会引起社会负面影响,以及如何识别和讨论数据集中的潜在偏差和其他局限性。
常用场景
经典使用场景
在文本分类领域,DBpedia 14数据集被广泛用作基准测试,其经典使用场景是训练和评估文本分类模型,以实现对输入文本内容的主题类别预测。该数据集包含了14个非重叠的主题类别,涵盖了从公司、教育机构到自然地点、动植物等多种领域,为模型提供了多样化的训练样本。
衍生相关工作
基于DBpedia 14数据集,学术界衍生出了一系列相关工作,包括但不限于字符级卷积网络在文本分类中的应用研究,这些研究进一步拓展了文本分类技术的边界,并在多个任务中取得了显著的性能提升。
数据集最近研究
最新研究方向
DBpedia14数据集作为文本分类领域的重要基准,其最新研究方向主要聚焦于细粒度文本分类,尤其是通过深度学习模型,如字符级卷积网络,对非结构化文本数据进行有效特征提取和分类。近期研究在提升模型泛化能力、降低过拟合以及增强对长文本处理能力等方面取得显著进展。此外,该数据集在探索模型的可解释性、处理数据偏见和提升多语言文本分类性能等热点事件上展现出重要影响,为构建更加公平、透明和高效的知识提取系统提供了有力支撑。
以上内容由遇见数据集搜集并总结生成


