Akihito_Kanbara_Videos_Captioned
收藏Hugging Face2025-03-14 更新2025-03-15 收录
下载链接:
https://huggingface.co/datasets/svjack/Akihito_Kanbara_Videos_Captioned
下载链接
链接失效反馈官方服务:
资源简介:
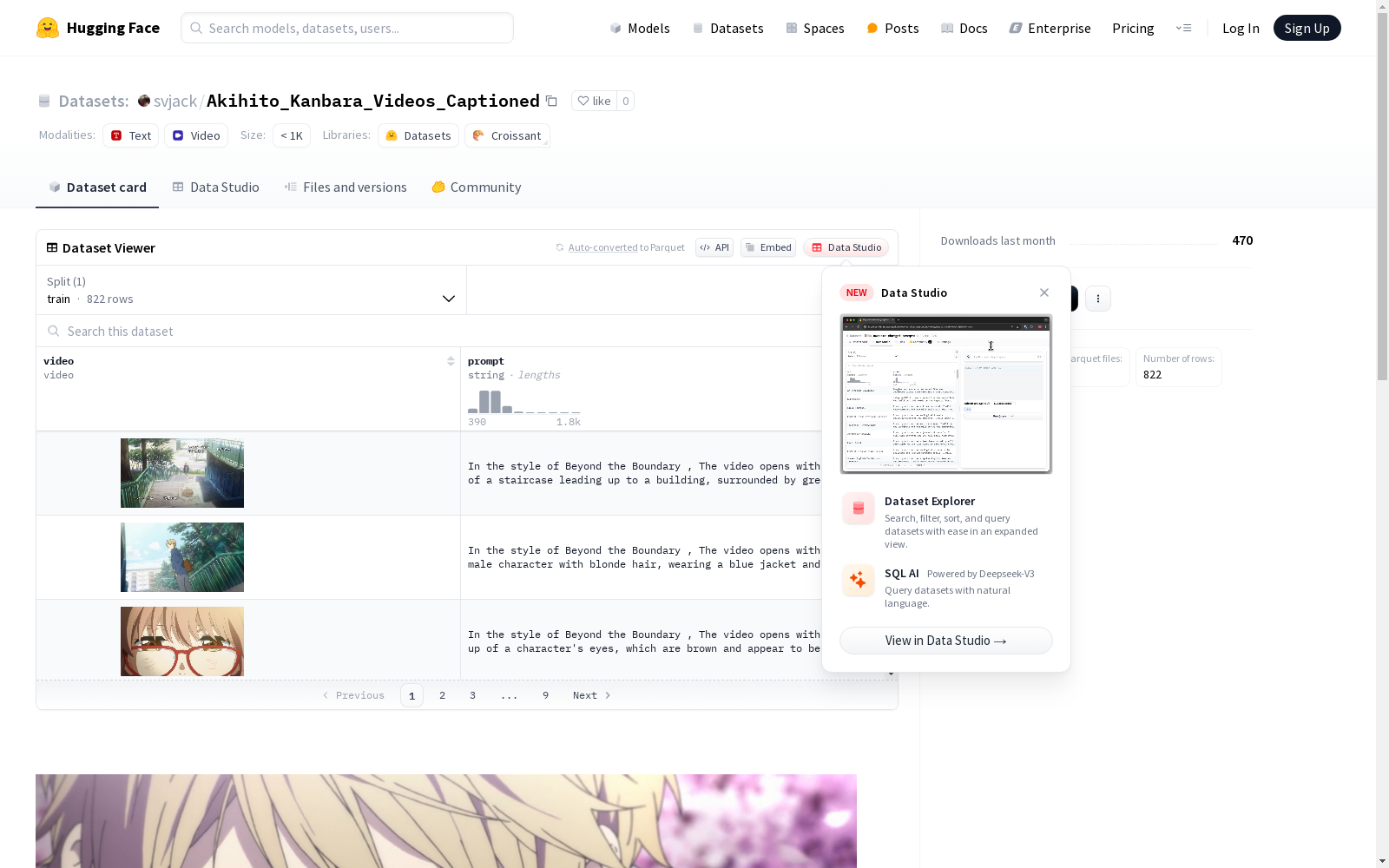
该数据集是一个视频数据集,用于训练,包含了MP4格式的视频文件和CSV格式的元数据文件。具体内容和使用场景未在README中说明。
创建时间:
2025-03-12
搜集汇总
数据集介绍
构建方式
Akihito_Kanbara_Videos_Captioned数据集的构建,是通过整合视频文件及其对应的元数据表实现的。视频文件以MP4格式存储,元数据则以CSV格式记录,包含了视频的相关描述信息。该数据集的构建过程注重视频内容与元数据描述的准确性匹配,确保了数据集在后续应用中的可靠性。
使用方法
在使用Akihito_Kanbara_Videos_Captioned数据集时,用户需先获取数据集的视频文件和元数据表。通过分析元数据表中的描述信息,用户可以有效地对视频进行分类、检索等操作。同时,视频文件可用于视频内容分析,如视频标注、内容识别等任务,进而支持更深入的研究和应用开发。
背景与挑战
背景概述
Akihito_Kanbara_Videos_Captioned数据集,是在多媒体研究领域中,由Kanbara等人于近年开发的一个视频描述生成数据集。该数据集汇集了Akihito Kanbara教授的视频材料,辅以详尽的描述性文字注释,旨在推动视频内容理解与自动描述技术的发展。数据集的创建,不仅丰富了视频处理领域的研究资源,也为相关算法的改进提供了重要的实验基础,对自然语言处理与计算机视觉的交叉领域产生了显著影响。
当前挑战
该数据集在构建过程中遭遇了诸多挑战,其中包括视频内容的多样性、动态场景的复杂性以及自然语言描述的主观性。具体而言,研究人员需解决如何准确捕捉视频中的动态变化并转化为流畅的自然语言描述的问题。此外,构建过程中的技术挑战还包括数据标注的一致性和准确性,以及如何确保大规模数据集的可用性和可维护性。
常用场景
经典使用场景
在视频理解与自然语言处理领域,Akihito_Kanbara_Videos_Captioned数据集以其丰富的视频内容与对应的文字描述,成为研究视频自动字幕生成的重要资源。该数据集通过提供大量视频及其精确字幕,使得研究者能够训练模型识别视频内容,并自动生成对应的文字描述,极大地推动了视频内容理解技术的发展。
解决学术问题
该数据集有效地解决了视频字幕生成中的语义理解与同步问题,为学术研究提供了可靠的数据基础。通过该数据集,研究者可以探索视频帧与文字描述之间的复杂对应关系,提高字幕生成的准确性和自然性,对于推动多模态信息处理技术的发展具有重要的学术意义。
实际应用
实际应用中,Akihito_Kanbara_Videos_Captioned数据集可用于开发视频内容分析工具,为视障人士提供视频内容描述,以及优化视频搜索引擎算法,提升用户体验。这些应用不仅拓宽了人工智能技术的应用领域,也为社会带来了积极的影响。
数据集最近研究
最新研究方向
在视频字幕领域,Akihito_Kanbara_Videos_Captioned数据集近期成为研究的热点。该数据集包含了经过标注的视频文件和相应的字幕信息,为视频理解与生成研究提供了重要资源。当前,学者们正致力于深入探索视频内容与字幕之间的关联性,以期提升自动字幕生成系统的准确性和流畅性,推动视频信息无障碍化进程。此外,该数据集亦被应用于多模态信息处理和情感分析等前沿研究方向,其研究成果对于推动相关技术的发展具有重要的理论与实践意义。
以上内容由遇见数据集搜集并总结生成


