LogicMark
收藏Hugging Face2026-04-13 更新2026-04-14 收录
下载链接:
https://huggingface.co/datasets/AxiomicLabs/LogicMark
下载链接
链接失效反馈官方服务:
资源简介:
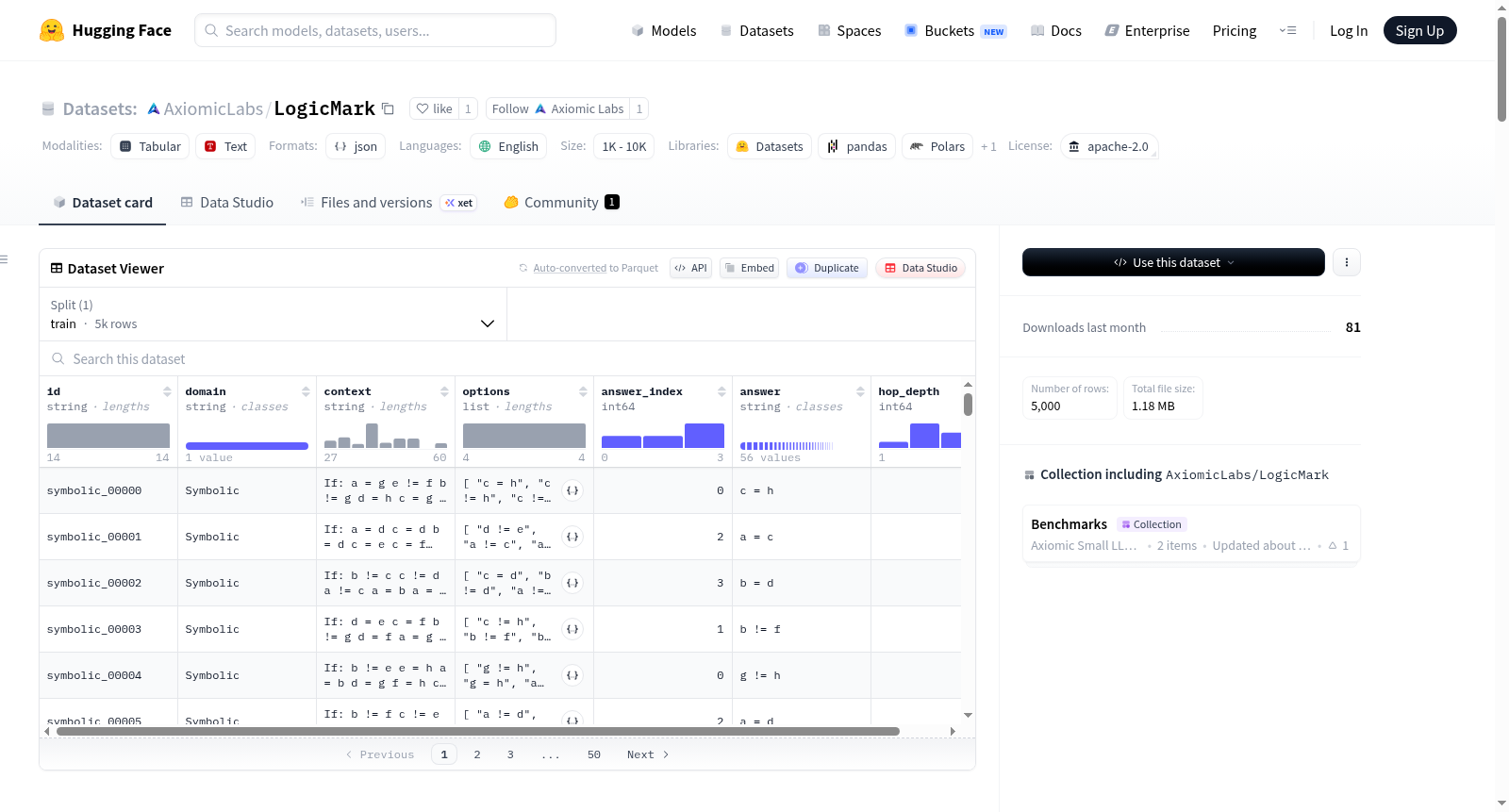
LogicMark 是一个用于评估语言模型符号逻辑能力的程序化生成基准数据集。每个问题提供一组变量相等/不等的前提,要求模型识别必然成立的结论。与基于知识的基准不同,LogicMark 不包含模型可能从预训练中记忆的任何事实,所有问题均使用抽象变量名(如 `a`, `b`, `c` 等)生成,确保模型必须进行实际推理而非模式匹配。数据集包含 1000 个问题,按跳数深度(1 至 5 跳)分布,其中 1 跳占 10%,2 跳占 40%,3 跳占 25%,4 跳占 15%,5 跳占 10%。问题生成采用六种等式图拓扑结构(链式、星型、簇、树、二分和混合),以确保多样化的推理模式。数据集格式为 JSON,包含问题 ID、领域、上下文、选项、答案索引、答案和跳数深度等信息。该数据集适用于评估语言模型的固有推理能力,特别是在符号逻辑任务上的表现。
创建时间:
2026-04-07
原始信息汇总
LogicMark 数据集概述
数据集基本信息
- 名称: LogicMark
- 发布者: Axiomic Labs
- 许可证: Apache 2.0
- 语言: 英语
- 数据规模: 1K<n<10K
- 示例数量: 1000个问题(当前数据集)
数据集目的与特点
LogicMark是一个用于评估语言模型符号逻辑推理能力的程序化生成基准测试。每个问题呈现一组变量相等/不相等的前提,并要求模型识别哪个结论必然成立。该基准测试不包含任何模型可能从预训练中记忆的事实知识,所有问题均使用抽象变量名(a, b, c, ...)生成,因此模型无法通过模式匹配训练数据来回答,必须进行实际推理。这使得LogicMark成为对内在推理能力的直接探测:即通过训练构建到模型权重中的逻辑结构,独立于世界知识或表面启发式方法。
评估方法
评估采用对数似然多项选择法,无需思维链或提示技巧。模型完全根据其为正确完成分配概率的好坏程度进行评分。随机猜测的正确率为25%。
任务格式
每个问题包含一组前提和一个多项选择问题。模型必须选择由前提逻辑蕴含的选项。干扰项包括正确答案的翻转版本以及从同一变量集中提取的错误陈述。
跳数深度
每个问题都标有跳数深度——从前提推导出正确答案所需的最小推理步骤数:
- 1跳: 答案直接作为前提陈述。
- 2跳: 需要一个传递步骤。
- 3跳: 需要两个传递步骤。
- 4跳以上: 更长的推理链。
当前数据集(1000个问题)的目标分布如下:
| 跳数 | 目标比例 |
|---|---|
| 1 | 10% |
| 2 | 40% |
| 3 | 25% |
| 4 | 15% |
| 5 | 10% |
图样式
前提使用六种相等性图拓扑生成,每种产生不同的推理模式:
chain: 变量以线性序列链接。star: 一个中心变量连接到许多其他变量。clusters: 内部链接的变量组。tree: 二叉树拓扑——最大化每个变量的链深度。bipartite: 边仅在两个半区之间交叉——同侧相等在结构上不可能。mixed: 上述样式的随机组合。
数据集格式
数据集以JSON格式提供,每个条目包含以下字段:
id: 问题唯一标识符。domain: 领域(固定为"Symbolic")。context: 问题上下文,包含前提。options: 多项选择选项列表。answer_index: 正确答案在选项列表中的索引。answer: 正确答案文本。hop_depth: 问题的跳数深度。
生成器
数据集由baseloggen_v2.py生成器创建,该生成器具有跳数深度控制和相等类型平衡功能。关键配置参数包括:
min_answer_hop: 正确答案的最小跳数深度(抑制简单问题)。target_hop_dist: 映射跳数深度到比例的字典。生成器精确采样每个桶。styles: 要从中采样的图拓扑元组。
设计决策
- 相等类型平衡: 正确答案以50/50的比例从
=和!=陈述中采样,以防止模型利用“正确答案往往是相等陈述”这一观察结果。 - 精确跳数目标: 当设置
target_hop_dist时,每个桶通过拒绝采样生成,精确针对该跳数深度,而不是依赖自然分布(后者严重偏向2跳)。 - 翻转干扰项: 正确答案的否定形式始终作为干扰项包含在内,以确保模型不能通过忽略不等式结构来获胜。
基准测试结果
基准测试结果基于5000个示例(每个跳数桶500个)进行评估,使用结束令牌的平均对数似然并按长度归一化。结果表格比较了不同公司和模型在1跳至5跳以及平均性能上的表现。
搜集汇总
数据集介绍
构建方式
在符号逻辑推理评估领域,LogicMark数据集采用程序化生成方法构建,旨在精准衡量语言模型的内在推理能力。生成过程基于抽象变量名称(如a、b、c等)随机创建等式与不等式前提,确保每个问题均独立于预训练数据中的事实记忆。通过配置生成器参数,系统严格控制问题的推理步长分布,涵盖从单步直接推理到多步链式推理的不同难度层级,并采用六种图拓扑结构来模拟多样化的逻辑关系模式。
使用方法
使用LogicMark进行评估时,通常采用对数似然多项选择范式,直接计算模型为正确选项分配的概率,无需依赖思维链或提示工程等外部技巧。研究人员可通过提供的生成脚本灵活配置变量数量、等式不等式比例及推理步长分布,以创建定制化的评估子集。数据集以标准JSON格式呈现,每个样本包含问题上下文、选项列表、答案索引及推理深度标签,便于直接集成到现有的模型评估流程中。
背景与挑战
背景概述
在人工智能领域,评估语言模型的推理能力一直是核心研究议题。LogicMark数据集由Axiomic Labs创建,旨在通过程序化生成的方式,专门评估语言模型在符号逻辑方面的内在推理能力。该数据集摒弃了依赖外部知识或记忆的模式,纯粹基于抽象变量(如a、b、c)的等式与不等式前提,要求模型从中推导出必然结论。其核心研究问题聚焦于剥离模型的世界知识,直接探测其通过训练构建的逻辑结构权重,从而为衡量模型的本质推理能力提供了标准化基准。
当前挑战
LogicMark所针对的领域挑战在于,现有许多基准测试易受模型预训练知识或表面启发式方法的影响,难以准确分离模型的记忆能力与纯逻辑推理能力。该数据集旨在解决符号逻辑推理这一特定问题的评估难题,要求模型在无外部知识干扰下进行多步推导。在构建过程中,挑战体现在确保问题的程序化生成能精确控制推理步长(hop depth),平衡等式与不等式结论以避免模型偏向性,并设计有效的干扰项(如包含正确答案的否定形式),从而生成既具挑战性又无偏见的评估样本。
常用场景
经典使用场景
在人工智能领域,评估语言模型的推理能力一直是核心挑战。LogicMark数据集通过程序化生成符号逻辑问题,为模型提供了纯粹的推理测试环境。其经典使用场景在于,研究者利用该数据集对语言模型进行零样本评估,无需任何提示工程或思维链辅助,直接测量模型在变量等式与不等式前提下的逻辑蕴含判断能力。这种评估方式剥离了知识记忆的干扰,专注于模型内在的符号推理结构,成为衡量模型是否真正掌握逻辑规则的关键基准。
解决学术问题
LogicMark数据集有效解决了语言模型评估中知识污染与表面启发式偏差的学术难题。传统基准常受预训练数据记忆影响,而该数据集使用抽象变量名称,确保每个问题都是首次出现,迫使模型进行本质推理而非模式匹配。这为探究模型内在推理能力的形成机制提供了纯净的实验平台,推动了关于模型是否真正理解逻辑关系、以及训练过程如何塑造符号处理能力的深层研究,对理解人工智能的推理本质具有重要理论意义。
实际应用
在实际应用层面,LogicMark数据集为开发可靠的人工智能系统提供了关键的质量检验工具。在需要严格逻辑一致性的领域,如自动定理证明、程序代码验证或法律条文分析中,模型的推理鲁棒性至关重要。通过该数据集评估,开发者能够筛选出在符号逻辑层面表现稳健的模型,避免因模型依赖虚假相关性或记忆碎片而导致关键决策错误。这直接提升了AI系统在安全敏感和高可靠性场景中的部署可行性。
数据集最近研究
最新研究方向
在语言模型推理能力评估领域,LogicMark数据集以其程序化生成的纯符号逻辑问题,为剥离知识记忆、直接探测模型内在推理结构提供了精准工具。当前研究聚焦于利用该数据集揭示不同规模模型在符号推理任务上的表现差异,特别是针对多跳推理深度的系统性评估。前沿探索涉及分析模型在链式、星型、树状等复杂图结构上的泛化能力,以及探究小参数模型在特定拓扑上超越大模型的机理。这一方向紧密关联于当前对模型“推理涌现”现象的热议,旨在区分表面模式匹配与本质逻辑演绎,为构建更具鲁棒性的推理系统提供实证基础。
以上内容由遇见数据集搜集并总结生成


